保持精度又縮小AI模型,英特爾開發新的訓練技術

一般來說,人工智能模型的大小與它們的訓練時間有關,因此較大的模型需要更多的時間來訓練,隨后需要更多的計算。優化數學函數(或神經元)之間的連接是有可能的,通過一個稱為修剪的過程,它在不影響準確性的情況下減少了它們的整體大小。但是修剪要等到訓練后才能進行。
本文引用地址:http://www.104case.com/article/201906/401535.htm這就是為什么英特爾的研究人員設計了一種從相反的方向進行訓練的技術,從一個緊湊的模型開始,在培訓期間根據數據修改結構。他們聲稱,與從一個大模型開始,然后進行壓縮相比,它具有更強的可伸縮性和計算效率,因為訓練直接在緊湊模型上進行。
作為背景,大多數人工智能系統的核心神經網絡由神經元組成,神經元呈層狀排列,并將信號傳遞給其他神經元。這些信號從一層傳遞到另一層,通過調整每個連接的突觸強度(權重)來慢慢地“調整”網絡。隨著時間的推移,該網絡從數據集中提取特征,并識別跨樣本趨勢,最終學會做出預測。
神經網絡不會攝取原始圖像、視頻、音頻或文本。相反,來自訓練語料的樣本被代數地轉換成多維數組,如標量(單個數字)、向量(標量的有序數組)和矩陣(標量排列成一個或多個列和一個或多個行)。封裝標量、向量和矩陣的第四種實體類型——張量增加了對有效線性變換(或關系)的描述。
該團隊的計劃在一篇新發表的論文中進行了描述,該論文已被接受為2019年機器學習國際會議的口頭陳述,訓練一種稱為深度卷積神經網絡(CNN)的神經網絡,其中大部分層具有稀疏權張量,或者張量大部分為零。所有這些張量都是在相同的稀疏性(零點的百分比)級別初始化的,而非稀疏參數(具有一系列值之一的函數參數)用于大多數其他層。
在整個訓練過程中,當參數在張量內部或跨張量移動時,網絡中的非零參數總數保持不變,每幾百次訓練迭代進行一次,分兩個階段進行:修剪階段之后緊接著是增長階段。一種稱為基于大小的修剪的類型用于刪除具有最小權值的鏈接,并且在訓練期間跨層重新分配參數。
為了解決性能問題,研究人員將神經網絡訓練兩倍epochs,并在加拿大高級研究所(Canadian Institute for Advanced Research)的CIFAR10圖像數據集和斯坦福大學(Stanford)的ImageNet上測試了其中的兩個epochs——WRN-28-2和ResNet-50。
他們報告說,在模型大小相同的情況下,該方法比靜態方法獲得了更好的精度,同時所需的訓練也大大減少,而且它比以前的動態方法產生了更好的精度。
該論文的主要作者之一Hesham Mostafa寫道:“實驗表明,在訓練過程中探索網絡結構對于達到最佳準確度至關重要。如果構造一個靜態稀疏網絡,復制動態參數化方案發現的稀疏網絡的最終結構,那么這個靜態網絡將無法訓練到相同的精度。”









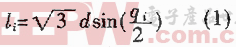


評論