為系統設計人員提供的DRAM控制器

即使滿足了這一要求,也還有其他問題。您必須對陣列預充電。預充電命令使得傳感放大器中的數據無效,提升陣列和傳感放大器輸入之間導線上的電壓,使得電壓值位于邏輯0和邏輯1電平之間。這種準備是必要的,比特單元電容上很小的電荷都會傳送到導線上,以某種方式提示傳感放大器。
對導線進行預充電之后,您必須向新行發送一個激活命令,等待操作完成,然后,您最終可以發送一個讀操作新命令。加上所有涉及到的延時后,即,讀取字節序列的最差情況,每一字節都來自不同的行,這要比讀取來自一個新行連續位置相同數量字節的時間慢十倍。
這種不同還只是部分問題。如圖2 所示,DDR DRAM有多個塊:與比特單元無關的陣列。DDR3 DRAM中有八個塊,每一塊都有自己排列成行的傳感放大器。因此,原理上,您可以通過激活每一個塊中的一行,讀寫較長的突發,然后,對每一激活后的行進行讀寫操作——實際上是對塊進行間插操作。唯一增加的延時是連接每一塊的傳感放大器和芯片內部總線的緩沖的切換時間。這一延時要比對相同塊中一個新行進行預充電和激活的時間短得多。
圖2.一個典型的DDR DRAM結構圖。一個DDR3器件會有8個塊,而不是4個。

這就是原理。實際中,您可以對塊進行間插處理,但是有一個限制,不是基于DRAM邏輯,而是芯片能夠承受的熱量。這種限制可以通過著名的“滾動四塊訪問窗口”,即,tRAW來表達:您一次能夠有四個激活塊的最長時間。這一規則實際上有例外,只要您從一個塊轉向下一塊之前,在一個塊上保持一定的時間,那么,您可以有連續激活的8個塊。但是您應該知道:這比較復雜。
建立一個控制器
與前面所述不同的是DRAM時序非常復雜,接近混沌。從DRAM芯片設計人員的角度看,這非常合理,但是,很難滿足多核SoC的需求。DRAM序列或者時序命令上看起來無關緊要的小改動會導致您訪問存儲器的帶寬的巨大變化。由于存儲器帶寬通常是關鍵任務的瓶頸所在,因此,帶寬的變化很快就會影響系統性能。然而,命令序列和時序來自應用程序和系統軟件之間,以及系統硬件各種單元之間復雜的交互——包括緩存控制器、存儲器管理器、直接存儲器訪問(DMA)控制器和加速器,以及DRAM控制器。
SoC的功能越來越強大,這種情況會更加復雜。目前,一個多核系統級IC會有同時運行的兩個甚至更多的多線程CPU,導致共享L2高速緩存來讀取指令線,隨機對數據線進行讀寫操作。同時,計算加速器以自己的方式遍歷數據結構。一個器件可以處理流視頻,另一個用于矩陣乘法預讀取,第三個執行路由表的隨機訪問。增加一個散射收集DMA控制器,處理光纖接口、硬盤和顯示器之間的數據,結果是,在DRAM控制器的系統側會有些不協調。
如果DRAM控制器只是按照系統接收順序進行操作,那么,優化DRAM操作的工作會同等落在規劃人員、設計人員和軟件開發人員上——這是很難做到的。Altera公司戰略市場經理Argy Krikelis提醒說:“特別是多核設計,規劃人員遇到定位和性能問題。”責任落在DRAM控制器上,那么,盡可能利用其信息消除這種不協調,轉換為經過優化的命令流。
深入了解DRAM控制器就會知道,這些模塊的設計人員怎樣處理這些難題。您可以認為一個現代DRAM控制器有三個主要模塊——物理接口、命令處理器以及事物處理器——如圖3 所示。
圖3.一個現代DRAM控制器涉及到事物處理器、命令處理器和物理接口。
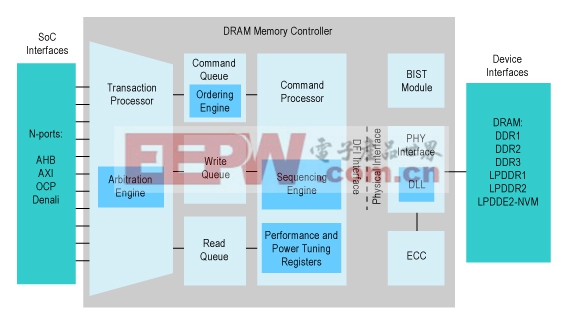
物理接口連接DRAM芯片或者存儲器模塊。它讀取來自命令處理器的一個命令流,將具有正確時序的命令發送至DRAM芯片,管理相關的數據字節流。接口收發器、命令和數據同步緩沖,以及產生正確命令和數據時序的狀態機都含在這一模塊中。而且,還有用于進行復雜的初始化操作的狀態機,校準DDR3 DRAM規范設定的序列,如圖1所示。此外,某些應用的物理接口還會包括自測試、診斷和誤碼探測以及糾錯硬件。當您改變DRAM的容量或者速率等級時,必須調整物理接口。








評論