基于TalusVortexFX的32/28納米節(jié)點(diǎn)設(shè)計(jì)方案

這種技術(shù)背后的概念是:對(duì)一個(gè)更大型的設(shè)計(jì)或模塊進(jìn)行智能分割、將設(shè)計(jì)分區(qū)分散到整個(gè)網(wǎng)絡(luò)的服務(wù)器上執(zhí)行設(shè)計(jì)實(shí)現(xiàn)、最后在主要流程階段自動(dòng)對(duì)這些設(shè)計(jì)實(shí)施重新同步。本質(zhì)上,這讓設(shè)計(jì)師能夠處理更大型設(shè)計(jì),同時(shí)仍可獲得與他們之前在規(guī)模更小得多的電路模塊上所實(shí)現(xiàn)的相同的吞吐量(即每天單元數(shù))。甚至在使用同等數(shù)量的內(nèi)核/線程的時(shí)候,這種分布式方案的處理速度也較最佳多線程扁平流程要快上2-3倍。
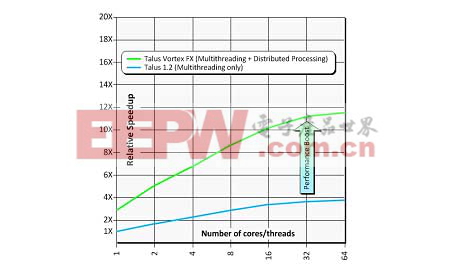
圖10.僅多線程vs.多線程+分布式處理
物理實(shí)現(xiàn)工程師的生產(chǎn)率一般是根據(jù)每天單元數(shù)來進(jìn)行衡量。使用最好的常規(guī)流程,可能獲得的最大生產(chǎn)率一般約為每天100萬個(gè)單元。相較之下,TalusVortexFX的分布式處理技術(shù)可將這一數(shù)字提高到每天200-500萬個(gè)單元,這種技術(shù)貫穿整個(gè)流程(對(duì)于只布局的門極電路而言,生產(chǎn)率可獲得更高的提升,這是一些用戶會(huì)關(guān)注的另一指標(biāo))。
還值得關(guān)注的是:TalusVortexFX為物理實(shí)現(xiàn)團(tuán)隊(duì)提供了在設(shè)計(jì)周期早期執(zhí)行快速的假設(shè)分析的能力,實(shí)現(xiàn)了最佳的面積、速度和功耗間折衷權(quán)衡。但還有一點(diǎn)也不容忽視:DistributedSmartSync技術(shù)完全增強(qiáng)了現(xiàn)有Talus1.2技術(shù),進(jìn)而促進(jìn)了這款產(chǎn)品的快速采用。
至于保留現(xiàn)有硬件資源的投資方面,DistributedSmartSync技術(shù)讓用戶現(xiàn)有的內(nèi)存為32GB和64GB的設(shè)備能夠得到充分利用。若未采用這項(xiàng)技術(shù)而轉(zhuǎn)向32/28納米節(jié)點(diǎn)設(shè)計(jì),那么將要求用戶的設(shè)備要升級(jí)為內(nèi)存128GB或256GB的設(shè)備,碰到大型服務(wù)器場(chǎng)的話這可能需耗費(fèi)幾百萬美元。
除了通過縮短設(shè)計(jì)周期、提高工程團(tuán)隊(duì)使用扁平方法的能力(在不必添加額外資源的前提下)、提高工程團(tuán)隊(duì)的生產(chǎn)率以外,TalusVortexFX的使用通過縮短上市時(shí)間(贏利時(shí)間)還解決了如何滿足日益緊張的開發(fā)時(shí)間表這一問題。
總結(jié)
進(jìn)行32/28納米及更小尺寸技術(shù)節(jié)點(diǎn)設(shè)計(jì)時(shí)會(huì)遇到許許多多的問題,包括低功耗設(shè)計(jì)、串?dāng)_效應(yīng)、工藝變異以及操作模式和角點(diǎn)數(shù)量的顯著增加。微捷碼的TalusVortex1.2物理實(shí)現(xiàn)環(huán)境完全解決了所有這些問題。
此外,32/28納米節(jié)點(diǎn)設(shè)計(jì)尺寸及復(fù)雜性的不斷提高還造成了工程資源(不擴(kuò)大團(tuán)隊(duì)規(guī)模而取得更大成果)、硬件資源(無需升級(jí)主板、增加內(nèi)存或購買全新設(shè)備,使用現(xiàn)有設(shè)備和服務(wù)器場(chǎng)來處理更大型設(shè)計(jì))和如何滿足日益緊張開發(fā)時(shí)間表等方面相關(guān)問題的增加。為了解決這些問題,通過TalusVortexFX創(chuàng)新性的DistributedSmartSync™(分布式智能同步)技術(shù),TalusVortex顯著地提高了其容量和性能。






評(píng)論