基于DSP的寬帶雷達多片流水分段脈壓處理平臺設計

1 引 言
本文引用地址:http://www.104case.com/article/87582.htm作為一種探測目標信息的工具,雷達在現代戰爭中發揮著舉足輕重的作用。在雷達回波信號處理中,通常利用線性調頻信號脈沖壓縮技術來獲得高的距離分辨率。他有效地解決了雷達作用距離與距離分辨率之間的矛盾,可以在保證雷達作用距離的情況下提高雷達的距離分辨力。數字脈沖壓縮就是利用數字信號處理的方法來實現雷達信號的脈沖壓縮,分為時域和頻域兩種實現方式。時域脈壓常用數字濾波器實現,而頻域脈壓常用專用的FFT芯片或DSP完成。一般而言,對于小時寬帶寬積信號,用時域脈壓較好;但對于大時寬帶寬積信號,用頻域脈壓較好。隨著通用DSP芯片本身處理能力的不斷提高,基于并行DSP芯片的雷達信號處理系統基本能夠滿足雷達脈沖壓縮信號處理實時性的需求。
本文針對雷達回波的實時脈沖壓縮處理,首先分析了頻域脈壓處理方法,介紹了分段脈壓原理。然后研究了基于DSP的多片流水分段脈壓設計,以某寬帶雷達回波為例,提出了基于4片ADSP-TS101芯片的高性能并行DSP硬件處理平臺設計。最后給出了硬件實現和實驗結果。
2 頻域脈壓實現分析
對接收到的信號作數字脈壓,等同于信號通過一個加權的匹配濾波器。從時域來說,輸出為信號與加權的匹配濾波器的線性卷積,等價于二者在頻域的乘積。需要注意的是兩離散信號頻率域相乘相當他們在時域作圓卷積,為使圓卷積與線性卷積等價,待處理的信號須加零延伸,避免圓卷積時發生混疊。
設輸入序列x(n)長度為L,系統沖擊響應h(n)長度為M(M<L),輸出y(n)。對于頻域處理,其運算為:
![]()
式(1)實際上是圓卷積運算,在運算時,x(n)和h(n)必須至少補零到L+M-1點,等到x(n)完全讀入后,開始脈壓運算,得到的y(n)有效輸出長度為L點。因此頻域脈壓處理時間大致分為數據塊讀入讀出時間和脈壓運算時間。總運算量包括L點x(n)數據輸入、L+M-1點復FFT,L+M-1點復點乘、L+M-1點復IFFT以及L點y(n)數據輸出。
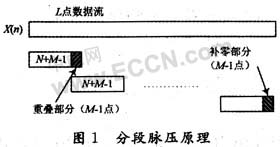
當輸入序列x(n)的長度L》M,直接做L+M-1點的脈壓不僅運算量大、存儲單元多,而且有很大的數據讀入讀出延遲。可以采用重疊保留法進行分段脈壓處理。設x(n)均勻分段,每段長度為N(滿足N≥M,N+M-1接近2的整數次冪),在每段后面再補上后一段的前M-1個輸入序列值,組成N+M-1點序列,若為最后一段,則補M-1個零。每個N+M-1點序列與h(n)脈壓后,輸出的結果取前N點為每段的有效輸出。這樣按順序拼接在一起即可得到輸入序列x(n)的脈壓輸出。其原理如圖1所示。
3 基于DSP的多片流水分段脈壓設計
當分段脈壓處理時,可以采用多個分段同時脈壓的并行處理技術來減少整個脈壓過程的處理時間。流水線技術(Pipeline)為并行處理系統設計中實現時間并行性提供了一種有效方法,他將輸入流水線的任務分為一串子任務,相繼的任務不斷流人流水線,利用子任務在執行時間上的重疊(Time Interleaving),使得每個子任務都處在整個操作流程不同的處理段中,且保持在不同的完成階段來達到操作級并行。
在忽略數據內部交換以及脈壓前的數據浮點化等運算時間的前提下,可以將每段脈壓任務大致分為數據輸入、數據脈壓和脈壓結果輸出三個子任務。若各段分段脈壓過程均采用流水線技術操作,相鄰兩段脈壓任務分別由不同的DSP完成。那么相鄰兩段脈壓過程進入流水的時間僅相差數據輸入的操作時間,流水操作如圖2所示。
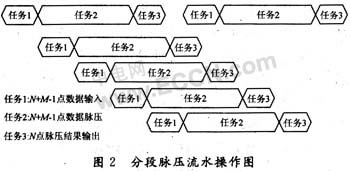
設輸入序列x(n)長度為L點,分段重疊點數為M-1,分段脈壓點數為d(為2的整數次冪)點,定義x(n)的分段總數為p,則p=[L/(d-(M-1))],[]表示不小于此值的最小正整數(下同)。定義每段的分段長度為N,則N=[L/p]。

下面以某寬帶雷達為例,在輸入序列點數和分段重疊點數確定的情況下,采用AD公司的高性能定/浮點ADSP-TS101芯片,分析各流水任務時間、流水操作時總的脈壓時間、分段數、任務時間比以及參與多片流水的DSP數量等與分段脈壓點數之間的關系。設雷達脈沖寬度為1 μs,脈沖重復周期(PRT)為1 ms,帶寬為200 MHz,脈壓距離范圍為10 km,采樣率為220 MHz,I,Q兩路合并輸出為16 b。相鄰兩分段的重疊數據在ADSP-TS101之間采用Link口傳輸。隨分段脈壓點數d的變化規律見圖3和圖4。
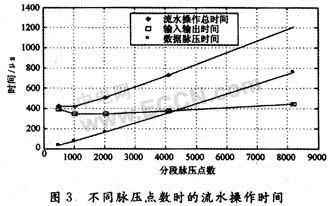
由圖3可以看出,流水操作時,隨分段脈壓點數d的增加,數據脈壓時間是快速增加的,數據輸入輸出時間是先遞減后緩慢增加的。總的脈壓時間Tpip是先遞減后快速增加的,這是因為,在d相對較小時,數據輸入輸出時間的減少量大于數據脈壓時間的增加量,總的脈壓時間Tpip的變化表現為減少;而隨著d的增加,數據脈壓時間的增加量明顯大于數據輸入輸出時間的增加量,總的脈壓時間Tpip的變化表現為快速增加,特別當d大于4 096點之后,數據脈壓時間更成為總的脈壓時間Tpip的主要部分。可以得出,分段脈壓點數d的遞減不一定總會帶來總的脈壓時間的減少,特別當d相對較小時,數據輸入輸出時間更成為制約總的脈壓時間Tpip的主要因素。
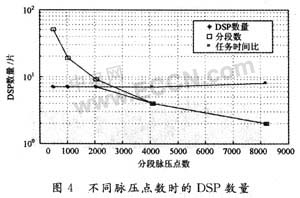
由圖4可以看出,隨分段脈壓點數d的增加,分段數反比于d,是快速遞減的。任務時間比是緩慢變化的,維持在7~8的水平,這是由ADSP-TS101本身的處理速度的決定的。在對應的分段脈壓點上,選擇分段數與任務時間比中相對較小的值,得到參與多片流水的DSP數量NDSP,其變化趨勢是遞減的。可以這樣理解,在d相對較小時,分段數較多,每個DSP可以完成多次分段脈壓任務,DSP的數量主要由任務時間比決定;而隨著d的增加,分段數快速遞減,直接減少了對DSP數量的需求。
為了評價基于DSP的多片流水分段脈壓設計的并行程度,在這里引用加速比(Accelerate Ratio)和并行效率的概念。可以定義NDSP個DSP處理器的加速比為:

可以看出,并行效率與加速比是密切相關的,Sp越接近于NDSP,Ep越接近于1。實際上,影響多片流水分段脈壓設計并行效率的因素是多方面的,我們應該綜合考慮流水操作時總的脈壓時間、參與多片流水的DSP數量、加速比以及并行效率等各項指標,以盡可能達到多片流水分段脈壓的最優設計。
根據式(2)~式(5),結合某寬帶雷達參數,給出不同分段脈壓點數d時的流水操作時總的脈壓時間Tpip、參與多片流水的ADSP-TS101數量NDSP,加速比Sp以及并行效率Ep等指標,詳見表1。
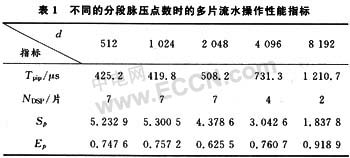
以上分析還沒有考慮單片ADSP-TS101的數據內部存取以及脈壓前的數據浮點化等運算時間。綜合各方面因素考慮,要在1 ms內完成該寬帶雷達回波的實時脈沖壓縮處理,我們選擇的分段脈壓點數為4 096點,據此設計了基于4片ADSP-TS101芯片的多片流水分段脈壓并行DSP硬件平臺,該平臺采用了共享總線并行結構和分布式并行結構相結合的方式,充分利用了并行總線的帶寬,以及Link口的靈活、方便及快速的特點。
4 硬件平臺設計實現
本文設計的實時脈壓處理硬件平臺是一塊由4片ADSP-Ts101構成的6U CPCI前面板,結構如圖5所示。DSP1,DSP2,DSP3,DSP4采用共享總線結構和MeshSP結構相結合的方式,構成板上的多片流水分段脈壓并行運算模塊。4片DSP在通過集成于芯片內部的發布式總線仲裁邏輯共享總線的同時,還通過Link口構成了兩兩互連的網格結構,這樣充分發揮ADSP-TS101芯片的并行處理能力的優勢。兩種并行計算結構的結合,既減少了處理器對總線的競爭,又大大增強了處理器問的數據交換能力。數據總線和地址總線上連接存放程序代碼的FLASH芯片和作為外部存儲的SDRAM芯片,能夠滿足系統對大批量數據的處理需求。
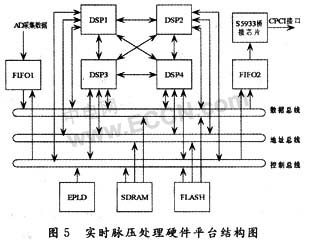
FIFO1和FIFO2作為數據的輸入輸出緩存,寬帶雷達的視頻回波數據首先在FIFO1中緩存。當FIFO1中寫入14 667點完整的目標回波數據后,由EPLD向DSP發出數據有效標志。當DSP檢測到數據有效標志后,將FIFO1中數據寫到DSP緩沖區。數據在DSP之間的傳輸主要通過Link口實現,當DSP將脈壓結果寫入FIFO2后,EPLD向CPCI接口芯片S5933發送數據有效標志。當S5933檢測數據有效標志后將FIFO2中數據寫到主機。實物圖如圖6所示。

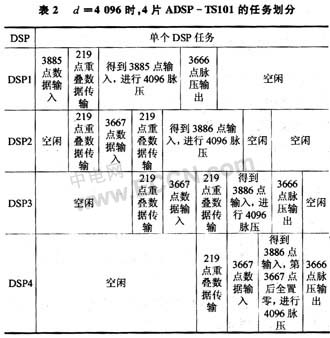
下面給出4片DSP的任務劃分,見表2,當d=4 096時,p=4,N=14 667/4,我們取各分段長度分別為3 666,3 667,3 667,3 667。
5 實驗結果及結論
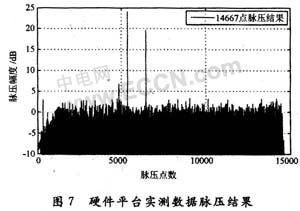
雷達回波數據經過脈壓處理之后,由CPCI總線接口傳輸給計算機,通過Matlab軟件將脈壓結果顯示如圖7所示。經過實測,整個脈壓處理過程從數據輸入到脈壓結果輸出共耗時約780μs。完全滿足脈沖重復周期(PRT)1 ms的要求。
在雷達回波的實時處理過程中,脈沖壓縮處理占有舉足輕重的地位。本文在進行基于DSP的多片流水分段脈壓設計時,做了兩個假設:第一個是將每段脈壓任務分為數據輸入、數據脈壓和數據輸出三個子任務,忽略其他的運算時間,進行流水設計,得出了總的脈壓時間;第二個是假設相鄰的子任務由不同的DSP完成,據此得出了參與多片流水的DSP數量。然后綜合考慮了總的脈壓時間、參與多片流水的DSP數量、加速比以及并行效率等因素,在輸入序列點數和分段重疊點數確定的情況下,研究了分段脈壓的分段長度設計,指導設計實現了基于4片ADSP-TS101芯片的高性能并行DSP硬件平臺。最后通過實測數據驗證了硬件平臺的設計。















評論