HBM 開發路線圖揭曉:2038 年將推出 HBM8,具有 16,384 位接口和嵌入式 NAND


韓國頂尖國家級研究機構 KAIST 發布了一份 371 頁的論文,詳細介紹了到 2038 年高帶寬內存(HBM)技術的演進,展示了帶寬、容量、I/O 寬度以及熱量的增加。該路線圖涵蓋了從 HBM4 到 HBM8 的發展,包括封裝、3D 堆疊、以內存為中心的架構以及嵌入 NAND 存儲,甚至基于機器學習的方法來控制功耗。
請記住,該文件是關于 HBM 技術假設演進的,基于當前行業和研究方向,而不是任何商業公司的實際路線圖。
(圖片來源:KAIST)
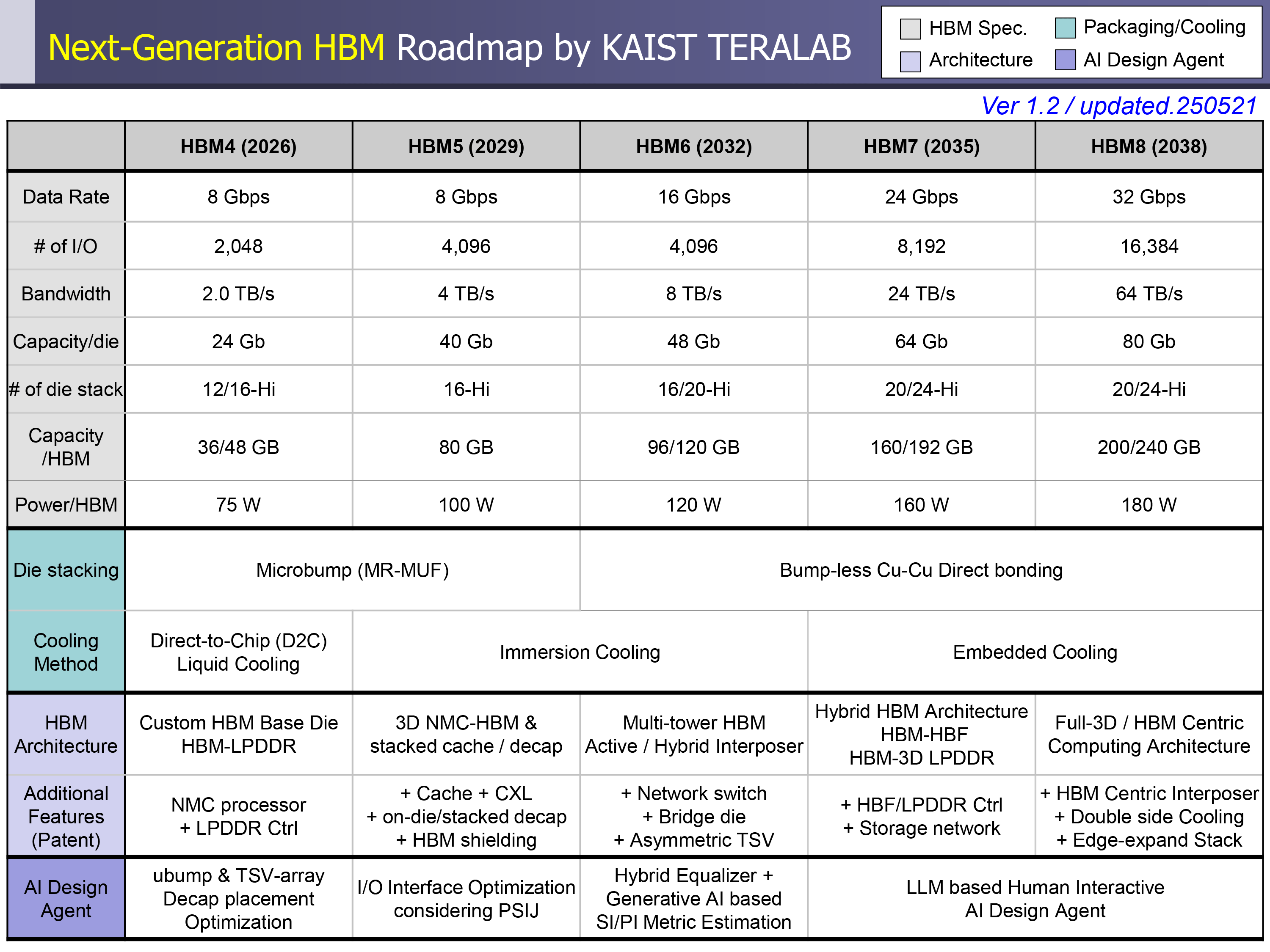
每堆疊的 HBM 容量將從 288GB 增加到 348GB(用于 HBM4),增加到 5,120GB 到 6,144GB(用于 HBM8)。同時,隨著性能的提升,功耗也將隨之增加,從使用 HBM4 時的每堆疊 75W 增加到使用 HBM8 時的 180W。
在 2026 年至 2038 年期間,內存帶寬預計將從 2TB/s 增長到 64TB/s,數據傳輸速率預計將從 8GT/s 增長到 32GT/s。每個 HBM 封裝的 I/O 寬度也將從目前的 HBM3E 的 1,024 位接口增加到 HBM4 的 2,048 位,然后一直增加到 HBM4 的 16,384 位。
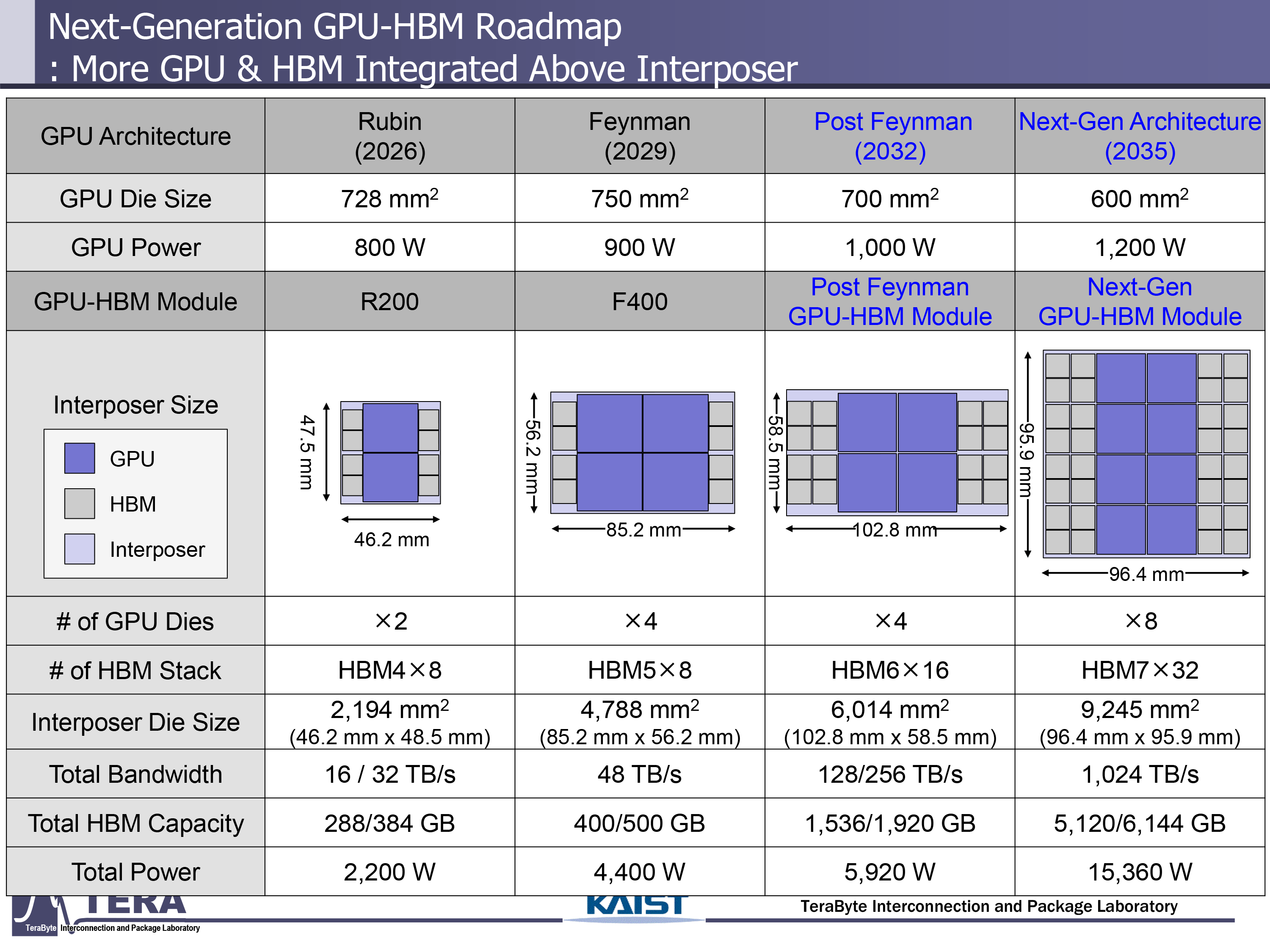
(圖片來源:KAIST)
我們已經對 HBM4 了如指掌,并且知道 HBM4E 將向基礎芯片添加可定制性 ,以使 HBM4E 更適合特定應用(人工智能、高性能計算、網絡等)。
預計這些功能將保留在 HBM5 中,HBM5 還將部署堆疊去耦電容器和 3D 緩存。隨著新的內存標準的到來,性能將得到提升,因此預計在 2029 年推出的 HBM5 將保持 HBM4 的數據傳輸速率,但預計將 I/O 數量增加到 4,096,從而將帶寬提高到 4 TB/s,并將每堆棧容量提高到 80 GB。
每堆棧功耗預計將增長到 100 W,這將需要更先進的冷卻方法。有趣的是,KAIST 預計 HBM5 將繼續使用微凸點技術(MR-MUF),盡管據報道行業已經開始考慮直接鍵合 與 HBM4。此外,HBM5 還將將在基礎芯片上集成 L3 緩存、LPDDR 和 CXL 接口,以及熱監控。KAIST 還預計人工智能工具將從優化物理布局和減少抖動等方面開始發揮作用,與 HBM5 代產品。
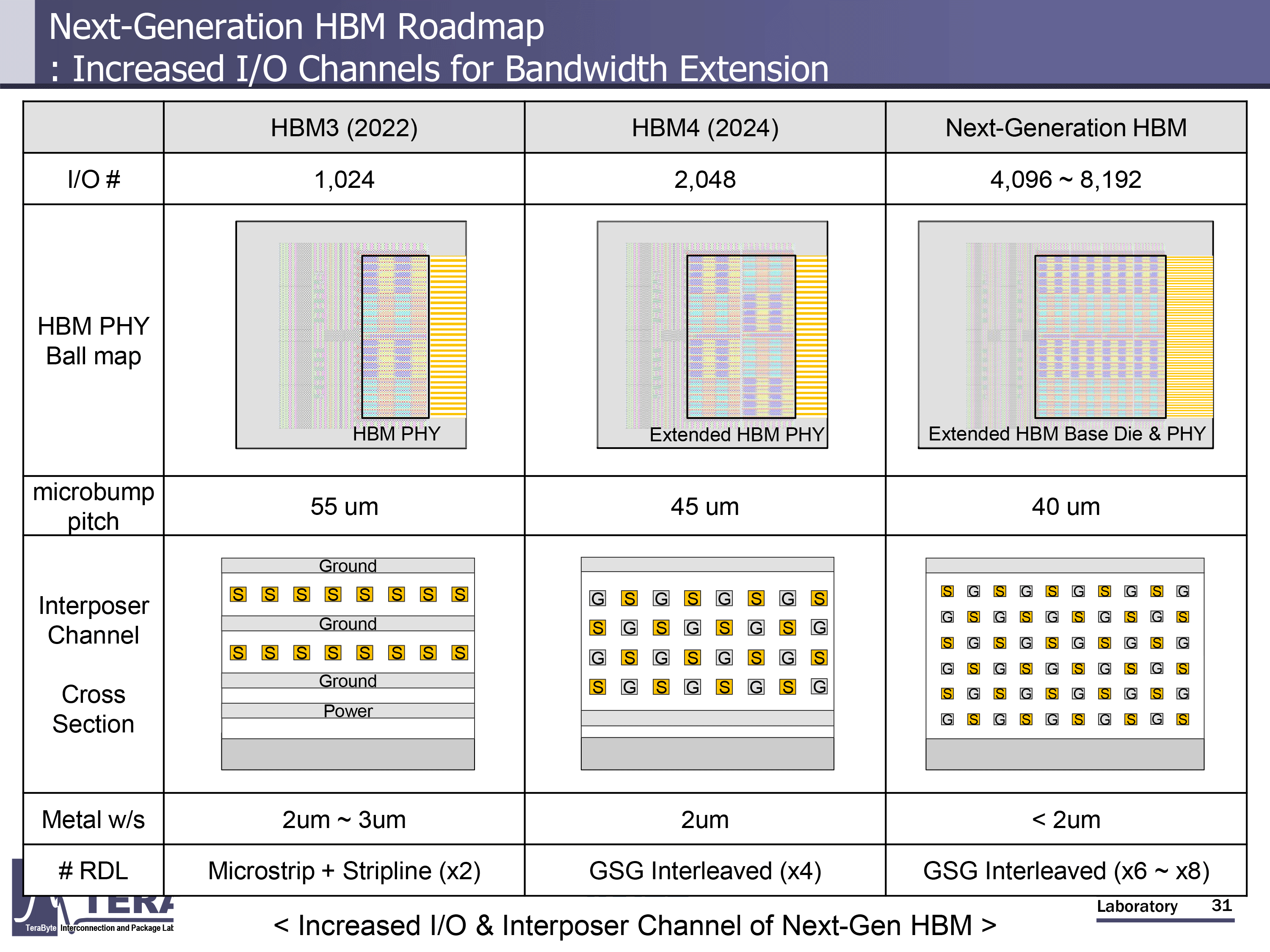
(圖片來源:KAIST)
HBM6 預計將在 2032 年接替,將傳輸速度提高到 16 GT/s,每堆棧帶寬提高到 8 TB/s。每堆棧的容量預計將達到 120 GB,功率上升到 120W。KAIST 的研究人員認為,HBM6 將采用無凸點的直接鍵合,以及結合硅和玻璃的混合中間層。架構變化包括多塔內存堆棧、內部網絡交換和廣泛的硅通孔(TSV)分布。AI 設計工具擴展范圍,結合用于信號和電源建模的生成方法。
保持技術前沿:訂閱 Tom's Hardware Newsletter
直接接收 Tom's Hardware 的最佳新聞和深入評測。
通過其他 Future 品牌與我聯系,獲取新聞和優惠信息接收我們代表我們信任的合作伙伴或贊助商發送的電子郵件
HBM7 和 HBM8 將更進一步,HBM8 將達到每堆棧 32 GT/s 和 64 TB/s。容量預計將擴展到 240 GB。封裝預計將采用全 3D 堆疊和雙面轉換器,并帶有嵌入式流體通道。
雖然 HBM7 和 HBM8 在形式上仍將屬于高帶寬內存解決方案系列,但它們的架構預計將與我們現在所知的 HBM 有巨大差異。HBM5 將增加 L3 緩存和用于 LPDDR 內存的接口,但這些代預計將集成 NAND 接口,從而實現從存儲到 HBM 的數據傳輸,而無需 CPU、GPU 或 ASIC 的過多參與。但這將以功耗為代價,預計每堆棧功耗為 180W。據 KAIST 稱,AI 代理將管理熱能、功耗和信號路徑的實時協同優化。
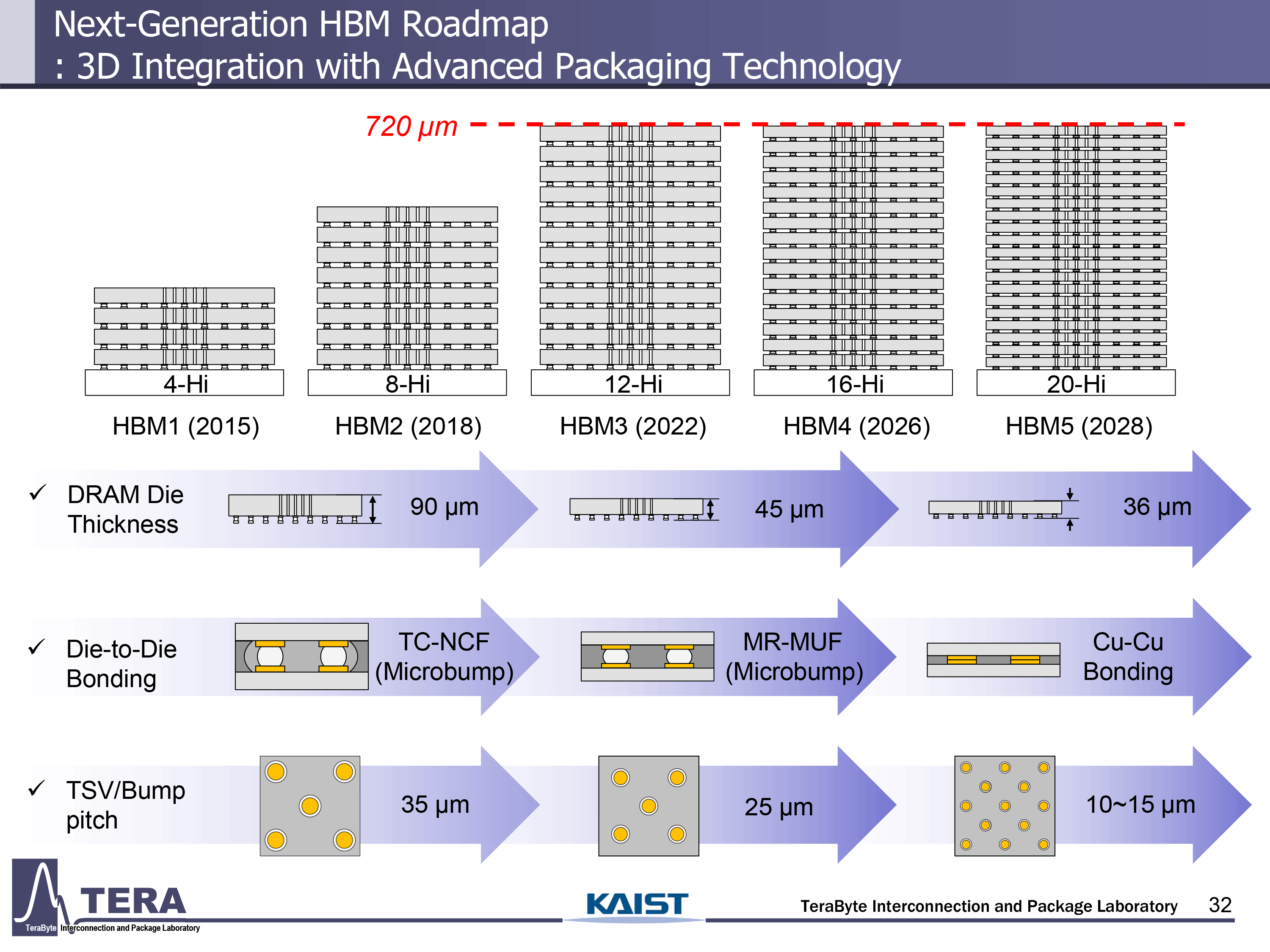
(圖片來源:KAIST)
請記住,KAIST 是一個研究機構,而不是一個有實際路線圖的公司,因此它幾乎無法根據今天所掌握的創新知識來模擬可能發生的事情。半導體行業中有其他值得尊敬的研究機構,包括比利時的 Imec、法國的 CEA-Leti、德國的 Fraunhofer 和美國的 MIT,僅舉幾例。這些機構就半導體工藝節點、芯片材料和其他相關主題發布了類似的預測。一些預測在今天看來可能不切實際,但行業往往會以意想不到的方式生產產品,因此許多預測成真,有時甚至被實際制造商,如英特爾或臺積電,超越。







評論