HBM新技術,橫空出世

AI 的火熱,令 HBM 也成了緊俏貨。
本文引用地址:http://www.104case.com/article/202503/468489.htm業界各處都在喊:HBM 缺貨!HBM 增產!把 DDR4/DDR3 產線轉向生產 DDR5/HBM 等先進產品。
數據顯示,未來 HBM 市場將以每年 42% 的速度增長,將從 2023 年的 40 億美元增長到 2033 年的 1300 億美元,這主要受工作負載擴大的 AI 計算推動。到 2033 年,HBM 將占據整個 DRAM 市場的一半以上。
可即便行業全力增產,HBM 供應缺口仍然很大,芯片巨頭也急的「抓耳撓腮」。
當下,存儲芯片巨頭主要有兩大行動方向。一方面,對 HBM 技術持續升級并加大現有 HBM 產品的產量;另一方面,分出部分精力,關注另一種形式的 HBM 產品。
HBM4,來了!
在 HBM 的技術升級中,SK 海力士總是那個「第一個吃螃蟹的人」。
3 月 19 日,SK 海力士宣布推出面向 AI 的超高性能 DRAM 新產品 12 層(12Hi)HBM4 內存,并在全球率先向主要客戶出樣了 12Hi HBM4。
SK 海力士在 12Hi HBM4 上采用了 24Gb DRAM 芯片,繼續使用了 Advanced MR-MUF 鍵合工藝,單封裝容量達 36GB,帶寬達 2TB/s,運行速度較 HBM3E 提升了 60% 以上。
SK 海力士強調,以引領 HBM 市場的技術競爭力和生產經驗為基礎,能夠比原計劃提早實現 12 層 HBM4 的樣品出貨,并已開始與客戶的驗證流程。公司將在下半年完成量產準備,由此鞏固在面向 AI 的新一代存儲器市場領導地位。
日前還有報道稱,SK 海力士預計將獨家供應英偉達 Blackwell Ultra 架構芯片第五代 12 層 HBM3E,預期與三星電子、美光的差距將進一步拉大。
反觀競爭對手三星這邊,HBM3E 此前一直未能獲得英偉達品質認證,而最新消息則是三星新 HBM3E 在日前英偉達的審核中獲得令人滿意的評分,預計最快 6 月初通過英偉達等的品質認證。
除此之外,這些存儲龍頭還在一些新興 HBM 技術上下足功夫。
移動 HBM,存儲巨頭下場了!
本文要談到的第一種新興技術,被稱為移動 HBM。
移動 HBM,即 LPW DRAM,也被稱為低延遲寬 I/O (LLW)。該技術是堆疊和連接 LPDDR DRAM 來增加內存帶寬,它與 HBM 類似,通過將常規 DRAM 堆疊 8 層或 12 層來提高數據吞吐量,并具有低功耗的優勢。
移動 HBM 和 LPDDR 最大的區別在于是否是「定制內存」。LPDDR 是通用型產品,一旦量產即可批量使用;而移動 HBM 是一個定制產品,反映了應用程序和客戶的要求。由于移動 HBM 與處理器連接的引腳位置不同,因此在批量生產之前需要針對每個客戶的產品進行優化設計。
HBM 是在 DRAM 中鉆微孔,并用電極連接上下層。移動 HBM 具有相同的堆疊概念,但正在推廣一種將其堆疊在樓梯中,然后用垂直電線將其連接到基板的方法。
三星和 SK 海力士均看中了移動 HBM 的潛力,但這兩家公司采取的技術路線各不相同。
三星開發「VCS」技術
三星正在開發名為「VCS」的技術,該技術將從晶圓上切割下來的 DRAM 芯片以臺階形狀堆疊起來,用環氧材料使其硬化,然后在其上鉆孔并用銅填充。堆疊形式可參照下圖右下角的呈現。

三星表示,VCS 先進封裝技術相較于傳統引線鍵合,I/O 密度和帶寬分別提升 8 倍和 2.6 倍;相比 VWB 垂直引線鍵合,VCS 技術生產效率提升 9 倍。
三星還為其新款 LPW DRAM 設定了高性能目標,與其尖端移動內存 LPDDR5X 相比,新款 LPW DRAM 的 I/O 速度預計將提高 166%。這比每秒 200GB 更快,同時功耗降低了 54%。
三星電子半導體暨裝置解決方案(DS)部門首席技術官宋在赫表示,搭載 LPW DRAM 內存的首款移動產品將在 2028 年上市。
近日,有業內人士表示,三星電子目前正與多個系統級芯片(SoC)客戶合作開發 LPW DRAM,已確認其中包括蘋果和三星電子的移動體驗(MX)業務部門。
SK 海力士開發「VFO」技術
SK 海力士正在開發名為「VFO」的技術,與三星的 VCS 不同,SK 海力士選擇的是銅線而非銅柱。DRAM 以階梯式方式堆疊,并通過垂直柱狀線/重新分布層連接到基板。堆疊形式可參照下圖。

它在連接元件和工藝順序方面與三星電子也不同,它使用銅線連接堆疊的 DRAM,然后將環氧樹脂注入空白處以使其硬化,來實現移動 DRAM 芯片的堆疊。
SK 海力士的 VFO 技術結合了 FOWLP(晶圓級封裝)和 DRAM 堆疊兩項技術,VFO 技術通過垂直連接,大幅縮短了電信號在多層 DRAM 間的傳輸路徑,將線路長度縮短至傳統內存的 1/4 以下,將能效提高 4.9%。這種方式雖然增加了 1.4% 的散熱量,但是封裝厚度卻減少了 27%。
至于為什么兩大存儲巨頭紛紛看上移動 HBM 這一賽道,主要源于設備上 AI 需求的推動,內存公司正在轉向 LPW DRAM 的開發。由于預計繼服務器領域之后,移動領域也將出現內存瓶頸,因此計劃積極推出高性能 DRAM。
cHBM,橫空出世
本文要談到的第二種新興技術,即 cHBM。
cHBM,即 Custom HBM,也就是定制高帶寬內存。其實上文提到的移動 HBM 也屬于 cHBM 的一種。
這個新型技術,由 Marvell 于去年 12 月推出。其與領先的內存制造商,如美光、三星和 SK 海力士等合作開發。
在 AI 算力芯片領域,GPU 廣為人知,是備受矚目的存在。然而,鑒于部分場景對定制化算力芯片需求更為強烈,ASIC 芯片應運而生。
如今,這一理念,也延續到了 HBM 領域。
那么,定制 HBM 與常規 HBM 有何不同?本文將用相對直白的闡述做一下介紹。
首先我們先來看一下常規的 HBM。據悉,HBM 已存在十多年,最初用于 AMD GPU 和 Xilinx FPGA,通過 1024 條以合理速度運行的數據線實現高帶寬,節省功耗但成本較高,限制了其應用范圍。
HBM 面臨的主要問題是容量限制,每個通道僅有一個堆棧,容量在 HBM3 之前有限,HBM4 雖有所增加,但根本問題在于 DRAM 密度和堆疊成本。
眾所周知,HBM 的原理像是利用 DRAM 在疊高高,這種辦法成本高昂,并且增加堆棧數量雖可部分解決容量問題,但會引發芯片邊緣空間限制、堆棧高度和經濟可行性等一系列新問題。由于引腳和走線需求,HBM 堆疊數量受芯片邊緣長度限制,通常每側最多 3-4 個堆疊,且受標線極限(約 800mm2)制約。
因此,盡管 HBM 有其優勢,但在容量和堆疊數量上仍面臨挑戰。
那么,cHBM 帶來了什么呢?
Marvell 的 cHBM 解決方案針對特定應用量身打造介面與堆疊,目標是減少標準 HBM 介面在處理器內部所占用的空間,釋放可用于運算和功能的空間。
在接口方面,可見下圖,HBM 是集成在 XPU 中的關鍵組件,使用先進的 2.5D 封裝技術和高速行業標準接口。然而,XPU 的擴展受到當前基于標準接口架構的限制。全新的 Marvell cHBM 計算架構引入定制接口,以優化特定 XPU 設計的性能、功耗、芯片尺寸和成本。
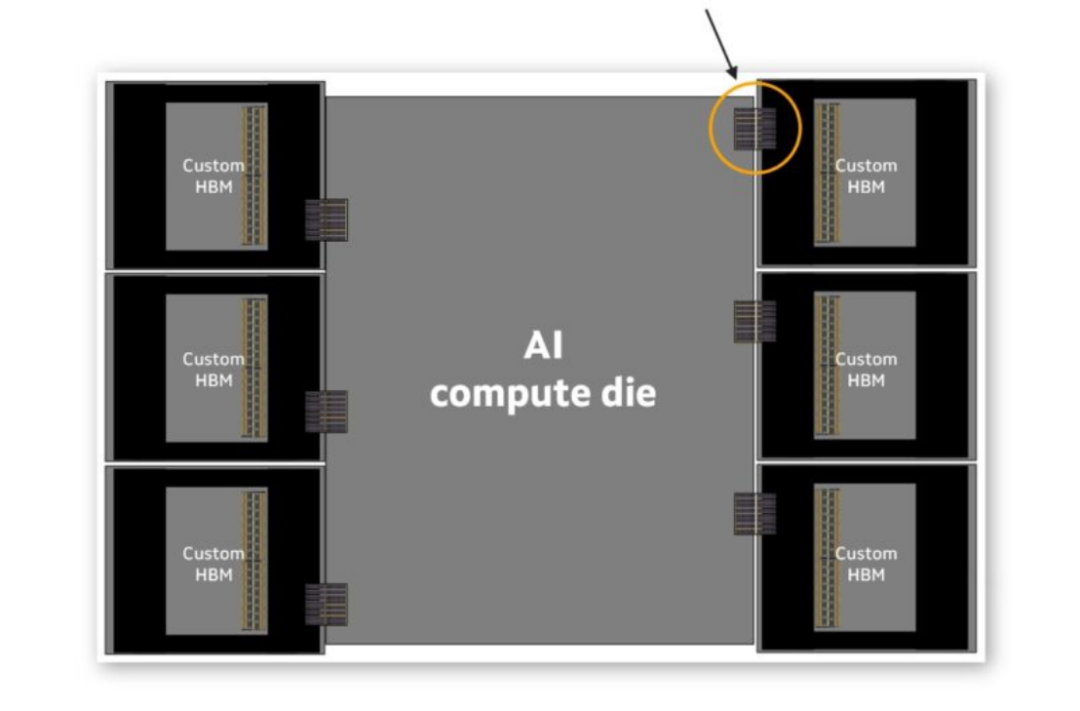
在性能提升方面,借由專屬 D2D(die-to-die)I/O,不僅能在定制化 XPU 中多裝 25% 邏輯芯片,也可在運算芯片旁多安裝 33%cHBM 存儲器封裝,增加處理器可用 DRAM 容量。預期可將存儲器介面功耗降低 70%。

在帶寬增加方面,新 Marvell D2D HBM 介面將擁有 20 Tbps/mm(每毫米 2.5TB/s)頻寬,比目前 HBM 提供的 5Tbps/mm(每毫米 625GB/s)多。此外,預期無緩沖存儲器的速度將達 50Tbps/mm(每毫米 6.25TB/s)。Marvell 沒透露 cHBM 介面的寬度及更多信息,僅表示通過序列化(serializing)與加速內部 AI 加速器芯片與 HBM 基礎芯片之間的 I/O 介面,來增強 XPU。
在硬件設計方面,由于 cHBM 并不依賴 JEDEC 標準,因此硬件部分需要全新的控制器和定制化實體介面、全新的 D2D 介面及改良的 HBM 基本芯片。與業界標準 HBM3E 或 HBM4 解決方案相比,cHBM 介面寬度較窄。
說簡單點,也就是 cHBM 可提供定制化接口以減少處理器內部空間占用,實現更高芯片裝載量、更低功耗、更高帶寬,并具備全新硬件設計。
關于應用,cHBM 的靈活性可以在不同類型的場景中帶來利好:
云提供商將其用于邊緣 AI 應用,其中成本和功耗是關鍵標準。
在基于 AI/ML 的復雜計算場中使用,其中容量和吞吐量被推到極限。
HBM 的應用場景,也在拓寬
除了技術的拓展,HBM 的應用場景也在不斷拓寬。
如上文所述,移動 HBM 主要應用于移動終端等設備,而 Marvell 的 cHBM 則主要適配 AI 領域的特殊需求。除了這兩點,HBM 產品還有這樣一種場景吸引人的注意力。即:HBM 上車。
HBM 在汽車中應用并不是一個新故事。
日前,SK 海力士副總裁 Kang Wook-sung 透露,SK 海力士 HBM2E 正用于 Waymo 自動駕駛汽車,并強調 SK 海力士是 Waymo 自動駕駛汽車這項先進內存技術的獨家供應商。
據悉,SK 海力士的車規級 HBM2E 產品展現了卓越性能:容量高達 8GB,傳輸速度達到 3.2Gbps,實現了驚人的 410GB/s 帶寬,為行業樹立了新標桿。以此為契機,SK 海力士正積極拓展與 NVIDIA、Tesla 等自動駕駛領域解決方案巨頭的合作網絡。
至于為什么汽車也要用上 HBM,筆者在此對汽車存儲的需求進行分析。
在面對智能座艙、車載信息娛樂系統、高級駕駛輔助系統日益火熱的當下,車用存儲芯片涉及 NOR Flash、eMMC、UFS、LPDDR、SSD 等品類。其中對內存的需求正在迅速擴大,當前主要產品是 LPDDR,以 LPDDR4 和 LPDDR5 為最多。
未來,只靠這些難以滿足汽車對存儲的全部需求。據測算,高端汽車在信息娛樂領域使用 24GB DRAM 和 64/128GB NAND,到 2028 年預計 DRAM 容量將超過 64GB,NAND 將達到 1TB 左右;對于 ADAS,預計當前 128GB DRAM 容量將增加到 384GB,NAND 將從 1TB 擴大到 4TB。
除此之外,在智能駕駛等應用場景的需求驅動下,存儲系統的功能已超越了單純的數據保存。它還必須實現高效的數據交換,例如,能夠迅速地將搜集到的各類信息進行即時傳遞與處理。
畢竟只有實現快速的數據交換,計算平臺才能及時對信息進行分析與處理,進而精準控制車輛的行駛速度、轉向角度等關鍵操作,保障智能駕駛的安全與流暢運行。
SK 海力士副總裁 Ryu Seong-su 透露,公司的 HBM 正受到全球企業的高度關注,蘋果、微軟、谷歌、亞馬遜、英偉達、Meta 和特斯拉等七巨頭都向 SK 海力士提出了定制 HBM 解決方案的要求。
定制 HBM,成為潮流
日前,三星在芯片代工論壇中提到,將從 HBM4 開始實現客戶定制化產品。業界消息人士透露,三星電子和 SK 海力士都在加速拓展「定制化內存」市場,即按照客戶所需形式制造和交貨 HBM。
據報道,為了應對定制化 HBM 需求,三星針對每位客戶性能需求開發優化產品,目前正與多家客戶討論詳細規格。
負責 PKG 產品開發的副總裁 Lee Kyu-jae 表示,能在 HBM 市場占主導地位的最大動力是在客戶需要的時間提供產品,公司計劃確保混合鍵合等新技術的同時,不斷推進先進的 MR-MUF 技術。
Lee Kyu-jae 強調開發下一代封裝技術的重要性,必須針對定制化產品需求增加入行回應,「預計今年下半年量產 HBM4,我們考慮從先進的 MR-MUF 和下一代混合鍵合方法」。
定制化 HBM 可能是解決內存市場供過于求疑慮的新解決方案。郭魯正指出,隨著公司超越 HBM4,定制化需求將增加,成為全球趨勢,并轉向以合約為基礎的性質,逐漸降低供過于求的風險。SK 海力士也將開發符合客戶需求的技術。
隨著 AI 興起,HBM 市場從「通用型市場」演進為「客戶定制化市場」,不管是三星在芯片代工論壇的發言,還是 SK 海力士與臺積電合作,都凸顯出為滿足客戶特定需求的策略。轉為定制化不僅解決供過于求問題,生產也能與客戶需求保持一致,確保 HBM 市場能更穩定發展。

評論