Xilinx UltraScale?:為您未來架構而打造的新一代架構

更為復雜的問題在于,通過大量的寬數據總線來擴展性能會帶來額外的代價,那就是需要顯著增加邏輯電路開銷用以支持寬總線的實施,從而進一步加大實現時序收斂的難度。
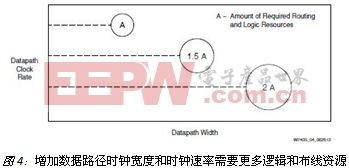
本文引用地址:http://www.104case.com/article/147542.htm以以太網數據包大小為例可以很好地說明這個情況。以太網的數據包最小為64字節(512位)。假設采用2048位寬的總線來實現400G的系統,那么總線最多容納4個數據包。
在2048位寬的總線中存在多種數據包組合形式,例如4個完整數據包或者1個、2個或3個完整或部分數據包,這樣需要使用大量邏輯來處理不同的情況與組合。需要大量復雜的重復邏輯來應對這些可能的組合。此外,如果總線要求對四個數據包進行同時處理并寫入到存儲器中,那么可能需要對邏輯的某些部分進行加速(或擴展性能)。可以考慮通過邏輯加速或用四個獨立的相同存儲器控制器來相繼處理多個數據包,但這些方式會進一步加大布線資源的壓力,迫使架構必須具備更多的高性能、低歪斜布線資源。參見圖4。
半導體工藝的擴展影響互連技術
隨著業界向20nm或更高級半導體工藝技術推進,在與銅線互連有關的RC延遲方面出現了新的挑戰,它會阻礙向新工藝節點演進所實現的性能提升效果。晶體管互連延遲的增加會直接影響所能實現的總體系統性能,因此更加需要所使用的布線架構能提供滿足新一代應用要求的性能等級。UltraScale布線架構在開發過程中充分考慮了新一代工藝技術的特點,而且能明顯減輕銅線互連的影響——如不進行妥善處理會成為系統性能瓶頸。
UltraScale互連架構:針對海量數據流進行優化
UltraScale新一代互連架構的推出體現了可編程邏輯布線技術的真正突破。賽靈思致力于滿足從多Gb智能包處理到多Tb數據路徑等新一代應用需求,即必須支持海量數據流。在實現寬總線邏輯模塊(將總線寬度擴展至512位、1024位甚至更高)的過程中,布線或互連擁塞問題一直是影響實現時序收斂和高質量結果的主要制約因素。過于擁堵的邏輯設計通常無法在早期器件架構中進行布線;即使工具能夠對擁塞的設計進行布線,最終設計也經常需要在低于預期的時鐘速率下運行。而UltraScale布線架構則能完全消除布線擁塞問題。結論很簡單:只要設計合理,就能進行布線。
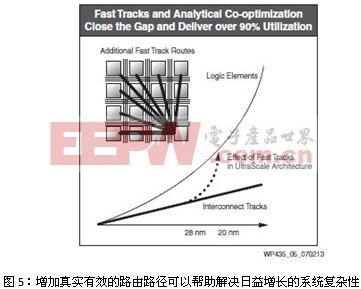
我們來做個類比。位于市中心的一個繁忙十字路口,交通流量的方向是從北到南,從南到北,從東到西,從西到東,有些車輛正試圖掉頭,所有交通車輛試圖同時移動。這樣通常就會造成大堵車。現在考慮一下將這樣的十字路口精心設計為現代化高速公路或主干道,情況又會如何。道路設計人員設計出了專用坡道(快行道),用以將交通流量從主要高速路口的一端順暢地疏導至另一端。交通流量可以從高速路的一端全速移動到另一端,不存在堵車現象。
賽靈思為UltraScale架構加入了類似的快行道。這些新增的快行道可供附近的邏輯元件之間傳輸數據,盡管這些元件并不一定相鄰,但它們仍通過特定的設計實現邏輯上的連接。這樣,UltraScale架構所能管理的數據量就會呈指數級上升,如圖5所示。
UltraScale架構堆疊硅片互聯技術全面強化所有功能
很少有開發的技術能夠像堆疊硅片互聯(SSI)技術集成那樣對器件容量和性能產生如此重大的影響,這已得到了賽靈思第一代基于7系列All Programmable器件的3D IC產品的驗證。集成SSI技術后,設計人員可以構建出工藝技術領先行業標準整整一代水平的更大型器件。而且該技術在賽靈思第二代基于UltraScale架構的3D IC產品中也同樣會達到這種效果。
由于3D IC中硅片間通信連接比獨立封裝的硅片間通信連接更密集、更快速,因此硅片間的通信所需功耗更低(假設硅片無需驅動硅片到封裝間互連以及板級互連的附加阻抗)。所以,與獨立封裝的硅片相比,SSI技術的集成能夠在顯著擴大容量和性能的同時降低功耗。此外,由于無法輕易訪問電路板層面的硅片間通信,這樣系統安全性也得到了加強。

存儲器相關文章:存儲器原理




評論