ASIC市場,越來越大了

這一點早已達成業內共識。但令人意外的是,ASIC 增長的速度實在是太快了。摩根士丹利預計,AI ASIC 市場規模將從 2024 年的 120 億美元增長至 2027 年的 300 億美元,年復合增長率達到 34%。
本文引用地址:http://www.104case.com/article/202506/471150.htm要知道 2023 年—2029 年,高性能計算 GPU 市場的年復合增長率是 25%,而 CPU 和 APU 的增長率僅為 5% 和 8%。
ASIC 市場,蛋糕膨脹
TrendForce 的最新研究報告指出,隨著人工智能服務器需求的迅猛增長,美國主要的云計算服務提供商(CSP)正加快內部開發專用集成電路(ASIC)芯片的步伐,平均每 1 至 2 年便推出新一代產品。在中國,人工智能服務器市場正逐步適應美國自 2025 年 4 月起實施的新出口管制政策。據預測,這些措施將導致 2025 年進口芯片(如 NVIDIA 和 AMD 產品)的市場份額從 2024 年的 63% 下降至約 42%。
與此同時,在政府積極推動國產人工智能處理器的政策扶持下,預計中國本土芯片制造商的市場份額將提升至 40%,與進口芯片的市場份額幾乎持平。
定制芯片是一種經濟選擇,而不是技術選擇。ASIC 蛋糕增長最重要的驅動力只有一個:錢。
從當前來看,GPU 服務器依然是最終用戶的首要選擇,但由于部分 GPU 產品受供應的限制,導致出現了算力缺口。很多頭部的互聯網企業,為了降低成本以及更好地適配自身業務場景,也增大了自研 ASIC 芯片服務器的部署數量。
比如在同等預算下,AWS 的 Trainium 2(ASIC 芯片)可以比英偉達的 H100 GPU 更快速完成推理任務,且性價比提高了 30%~40%。明年計劃推出的 Trainium3,計算性能更是提高了 2 倍,能效提高 40%。
云解決方案提供商正在優先考慮 ASIC 開發,以減少對 NVIDIA 和 AMD 的依賴,更好地控制成本和性能,并增強供應鏈靈活性。這種轉變對于管理不斷增長的 AI 工作負載和優化長期運營支出至關重要。
此外,如果芯片可以帶來戰略優勢,那么 ASIC 就是有意義的。蘋果就是一個很典型的例子,當然也有谷歌。
ASIC 的典型代表:TPU
廠商對能效比和成本的追求是永無止境的,國外大廠中谷歌、亞馬遜、Meta、OpenAI 等大型云計算和大模型廠商均加速布局定制化 ASIC。國內企業中寒武紀、達摩院、百度、騰訊等都在推出自己的 ASIC 芯片。
市場主流的 ASIC 芯片有 TPU、NPU、VPU 芯片。
谷歌的 TPU 作為 ASIC 已經非常典型的代表了。這是谷歌在 2016 年推出的首款產品,目標是為了高效地處理張量運算。
最新的 TPU 在今年 4 月發布,谷歌已經推出了第七代張量處理單元(TPU)Ironwood。谷歌稱,在大規模部署的情況下,這款 AI 加速器的計算能力能達到全球最快超級計算機的 24 倍以上。
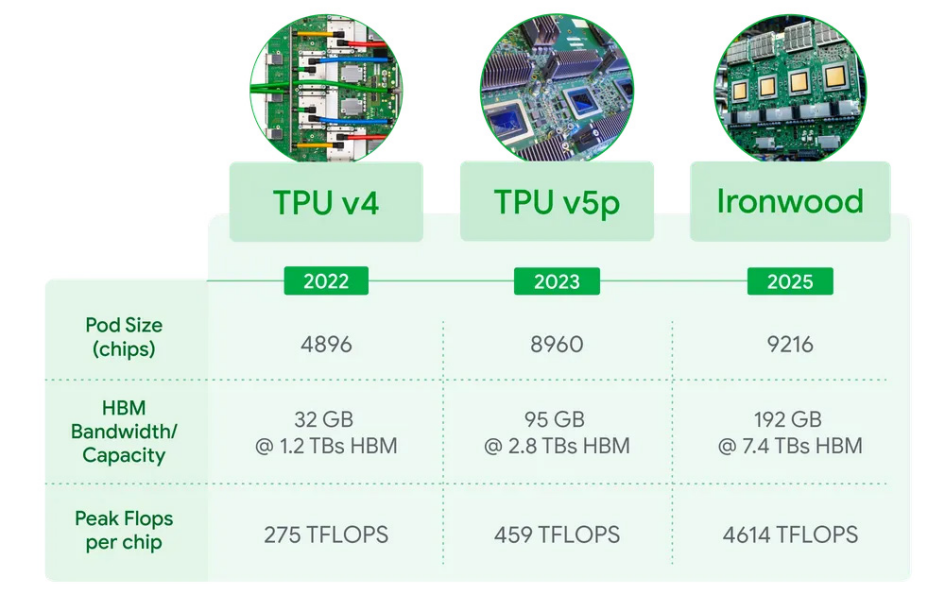
Ironwood 擁有超模的技術規格,當每個 pod 擴展至 9216 塊芯片時,它可提供 42.5 exaflops 的 AI 算力,遠超目前全球最快的超級計算機 El Capitan 的 1.7 exaflops。每塊 Ironwood 芯片的峰值計算能力可達 4614 TFLOPs。
在單芯片規格上,Ironwood 顯著提升了內存和帶寬,每塊芯片配備 192GB 高帶寬內存(HBM),是去年發布的上一代 TPU Trillium 的六倍。每塊芯片的內存帶寬達到 7.2 terabits/s,是 Trillium 的 4.5 倍。
目前,TPU 芯片已經成為全球第三大數據中心芯片設計廠商,據產業鏈相關人士透露,谷歌 TPU 芯片去年的生產量已經達到 280 萬~300 萬片之間。
國內這邊布局 TPU 芯片的企業是中昊芯英。創始人楊龔軼凡曾在谷歌 TPU 核心研發團隊參與過 TPU v2/3/4 的設計與研發工作。
2024 年,中昊芯英創始人及 CEO 就曾對外透露,2023 年中昊芯英成功實現了全自研的專為 AI 訓練而生的中國首枚高性能 TPU 訓練芯片「剎那」的量產交付。
據悉,「剎那」作為一款全自研的 GPTPU 架構 AI 訓練芯片,擁有完全自主可控的 IP 核、全自研指令集與計算平臺。在處理大規模 AI 模型訓練和推理任務時,「剎那」的計算性能超越英偉達 A100,系統集群性能更是十倍于傳統 GPU,在完成相同訓練任務量時的能耗僅是傳統 GPU 的一半。相比國外產品,「剎那」芯片的單位算力成本僅為其 42%。
ASIC,競爭不斷
在 ASIC 市場,目前博通以 55%~60% 的份額位居第一,Marvell 以 13%~15% 的份額位列第二。
博通在 AI 芯片領域的核心優勢在于定制化 ASIC 芯片和高速數據交換芯片,其解決方案廣泛應用于數據中心、云計算、HPC(高性能計算)和 5G 基礎設施等領域。
最新的財報來看,博通 2025 財年第一季度財報顯示,其營收達 149.16 億美元,同比增長 25%;非 GAAP 凈利潤 78.23 億美元,同比激增 49%。其中,AI 相關收入 41 億美元,同比增長 77%,占總營收的 28%,在半導體業務中占比更高達 50%。
博通的 ASIC 芯片業務已成為其核心增長點。財報披露,定制 AI 芯片(ASIC)銷售額預計占第二季度總 AI 半導體收入的 70%,達 308 億美元(約合 450 億美元)。
博通有兩個大合作備受關注:第一是 Meta 與博通已合作開發了前兩代 AI 訓練加速處理器,目前雙方正加速推進第三代 MTIA 芯片的研發,預計 2024 年下半年至 2025 年將取得重要進展。
第二是 OpenAI 已委托博通開發兩代 ASIC 芯片項目,計劃于 2026 年投產,將采用業界領先的 3nm/2nm 制程工藝并搭配 3D SOIC 先進封裝技術。與此同時,雖然蘋果目前仍在使用谷歌 TPU,但其自研 AI 芯片項目已在積極推進中。
Marvell 的定制芯片(ASIC)業務正成為其強勁增長的核心動力之一。Marvell 的具體業務中,數據中心業務占據 75% 左右,屬于高成長業務。這部分業務包括 SSD 控制器、高端以太網交換機(Innovium)及定制 ASIC 業務(亞馬遜 AWS 等定制化芯片),主要應用于云服務器、邊緣計算等場景。
Marvell 從 2018 年起陸續收購了 Cavium、Innovium 等公司,從而增強了公司 AISC 及數據中心的相關能力。
最新的財報顯示,Marvell 在 2026 財年第一季度的數據中心業務實現營收 14.4 億美元,環比增長 5.5%,符合市場預期(14.4 億美元)。
根據公司交流及產業鏈信息推測,Marvell 當前的 ASIC 收入主要來自亞馬遜的 Trainium 2 和谷歌的 Axion Arm CPU 處理器,而公司與亞馬遜合作的 Inferential ASIC 項目也將在 2025 年(即 2026 財年)開始量產。公司與微軟合作的 Microsoft Maia 項目,有望在 2026 年(即 2027 財年)。
但主要指出的是,不同于 NVIDIA 擁有諸如「主權 AI」、「創業公司爆發」等更具吸引力的故事,Marvell 的定制 AI 芯片依然局限于核心 CSP(云服務提供商)的投資節奏中。
鑒于本季度四大云廠商資本開支整體下滑的趨勢,即使 Marvell 通過競爭贏得了更多市場份額,但市場總量的縮減仍是不可忽視的事實。
國內企業也在積極研發 ASIC。
寒武紀科技還在擴展其思元(MLU)芯片系列(比如 7nm 工藝的思元 370、訓練芯片思元 290),以支持云端的 AI 訓練和推理。主要客戶包括:手機端(華為曾是其大客戶)、智算中心(政府訂單)、服務器廠商(浪潮、聯想)等。
同時,國內提供云服務的企業,實際上也推出了自研的 ASIC 芯片。
阿里巴巴推出了含光 800,作為一款云端 AI 推理芯片,峰值性能為 7.8 萬 IPS(每秒能處理 7.8 萬張照片),峰值能效達到 500IPS/W。在當時,阿里宣稱是全球最高性能的 AI 推理芯片,一塊含光 800 相當于 10 塊 GPU。
百度在量產昆侖芯二代后,又在今年宣布百度智能云成功點亮了首個自研萬卡集群。并且宣布是使用的昆侖芯三代 P800。P800 顯存規格優于同類主流 GPU20%~50%,對 MoE 架構更加友好,且率先支持 8bit 推理,單機 8 卡即可運行 671B 模型。正因如此,昆侖芯相較同類產品更加易于部署,同時可顯著降低運行成本,輕松完成 DeepSeek-V3/R1 全版本推理任務。自研的低成本,使得百度智能云平臺上,DeepSeek R1 和 V3 的官方價格直接低至五折和三折,基本實現全網最低。
騰訊除了自主研發的紫霄推理芯片外,還通過戰略投資,利用 Enflame 的 ASIC 解決方案。據了解,騰訊自研 AI 推理芯片「紫霄」,已經量產并在多個頭部業務落地,目前在騰訊會議實時字幕上已實現全量上線,單卡紫霄機器負載可達到 T4 的 4 倍,并將超時率從 0.005% 降低至 0。
結語
ASIC 市場的增長,也帶來了新的挑戰。
一個公司想要節省幾美元的供應商利潤,進行芯片自主設計。但現在芯片設計也并不是一個廉價的商品,尤其是先進芯片設計,已經變得非常昂貴。
臺積電 2nm 每片晶圓約 30,000 美元,到了 2nm 之后的 1.4nm 成本甚至達到 45,000 美元。
我們需要思考的是,我們真的每個公司都需要自己的 CPU 嗎?






評論