深度剖析多任務(wù)模型 QAT 策略

1.引言
為了節(jié)省端側(cè)計(jì)算資源以及簡化部署工作,目前智駕方案中多采用動(dòng)靜態(tài)任務(wù)融合網(wǎng)絡(luò),地平線也釋放了 Lidar-Camera 融合多任務(wù) BEVFusion 參考算法。這種多任務(wù)融合網(wǎng)絡(luò)的浮點(diǎn)訓(xùn)練策略可以簡述為:
然后,固定 backbone 的權(quán)重,分別接多個(gè) task head 進(jìn)行單獨(dú)的訓(xùn)練。
在這種浮點(diǎn)訓(xùn)練策略下,QAT(量化感知訓(xùn)練)里的 calibration(校準(zhǔn))和量化訓(xùn)練策略跟常規(guī)的單 task 模型差別較大。常規(guī)的單 task 模型一般就是用那種比較固定、普遍適用的訓(xùn)練辦法,不過碰到復(fù)雜多變又有特定需求的情況,它的局限性就慢慢顯現(xiàn)出來了。
這篇文章會(huì)結(jié)合具體的場景,對 calibration 和量化訓(xùn)練策略進(jìn)行分析,然后提出一些筆者個(gè)人獨(dú)特的看法,希望相關(guān)領(lǐng)域的研究和實(shí)踐提供點(diǎn)有用的參考和啟發(fā)。
2.量化訓(xùn)練策略本文將以具有兩個(gè)任務(wù)頭 task_head1 和 task_head_2 的多任務(wù)模型為例進(jìn)行描述。
2.1 步驟描述此步驟的前提是模型已完成**浮點(diǎn)訓(xùn)練。**
在進(jìn)行后續(xù)操作之前,必須確保模型已經(jīng)成功地完成了浮點(diǎn)訓(xùn)練。只有在這個(gè)前提條件得到滿足的情況下,才能保證后續(xù)的工作能夠順利進(jìn)行,并且得到準(zhǔn)確和可靠的結(jié)果。
step1:首先對骨干網(wǎng)絡(luò)(backbone)進(jìn)行校準(zhǔn)/量化感知訓(xùn)練(calibration/qat),在滿足量化精度要求后,保存校準(zhǔn)/量化感知訓(xùn)練的權(quán)重(calib/qat 權(quán)重)。
step2:驗(yàn)證 step1 中 backbone 在部署 head 上的精度,具體操作是對 backbone 進(jìn)行偽量化處理,而 task_head1 和 task_head2 保持浮點(diǎn)計(jì)算,然后在驗(yàn)證集上測試這兩個(gè) head 的精度。
step3:若 step2 驗(yàn)證出的 task_head1 精度不符合預(yù)期,則說明 backbone 的偽量化對 task_head1 的浮點(diǎn)精度不夠友好,所以需要對模型做以下調(diào)整,具體操作方案如下:
對部署的 task_head1 和 task_head2 做 finetune,從而使得 task_head1 和 task_head2 去適應(yīng) backbone,直到浮點(diǎn)精度符合預(yù)期;
固定 backbone,對 task_head1 做 calib 和 QAT(backbone 的 weight 和 scale 不更新)
固定 backbone,對 task_hea2 做 calib 和 QAT(backbone 的 weight 和 scale 不更新)
step4:固定 backbone 的 weight 和 scale 的方式見下文。
若 step2 驗(yàn)證出的 head 精度符合預(yù)期,則使用以下方案:
固定 backbone 的 weight 和 scale,然后分別對 task_head1 和 task_head2 做 calib/qat;
2.2 固定 weight 的方式固定 weight 采用 pytorch 的方法,包括固定 bn 和 stop 梯度更新這兩個(gè)操作,如下所示:
#固定bn` `model.eval()` `disable grad` `for param in model.parameters():` ` param.requires_grad = False2.3 Fix weight 和 activation scale 的方式
征程 6 工具鏈中具有多種 Fix scale 的方式,本文將介紹其中的一種。自定義固定weight和activation的激活 scale 的 qconfig,即配置"averaging_constant": 0,如下為自定義的int8 weight和int8/int16 activation固定 scale 的方式:
from horizon_plugin_pytorch.quantization.qconfig import get_default_qconfig2.4 示意圖
qat_8bit_fixed_weight_16bit_fixed_act_fake_quant_qconfig = (
get_default_qconfig(
weight_qkwargs={
"dtype": qint8,#weight采用int8量化
"averaging_constant": 0,#averaging_constant 置為 0 以固定 scale
},
activation_qkwargs={
"dtype": qint16,#采activation用int16量化
"averaging_constant": 0,#averaging_constant 置為 0 以固定 scale
},
)
)
qat_8bit_fixed_weight_8bit_fixed_act_fake_quant_qconfig = (
get_default_qconfig(
weight_qkwargs={
"dtype": qint8,
"averaging_constant": 0,
},
activation_qkwargs={
"dtype": qint8,
"averaging_constant": 0,
},
)
)
本節(jié)將會(huì)針對上述步驟展開詳盡且全面的圖文闡釋,通過清晰直觀的圖片和詳細(xì)準(zhǔn)確的文字說明,為您逐步剖析每個(gè)步驟的關(guān)鍵要點(diǎn)和操作細(xì)節(jié)。
2.4.1 驗(yàn)證 backbone 變化對 head 的影響此步驟的驗(yàn)證前提是 backbone 已經(jīng)完成了 calib/qat,并且偽量化精度已經(jīng)滿足預(yù)期,這里建議 backbone 的偽量化精度要達(dá)到浮點(diǎn)精度的 90% 以上。
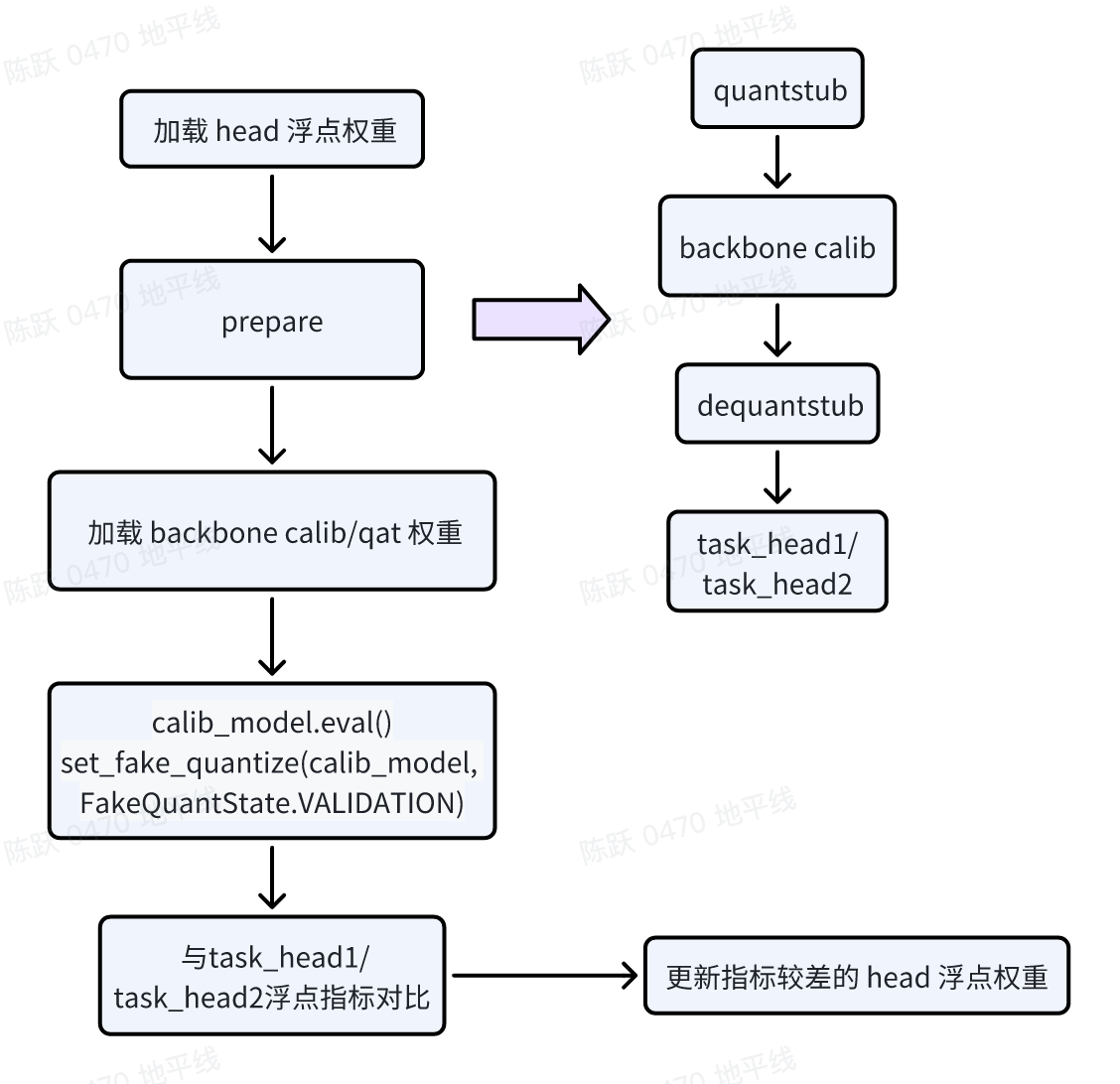
模型改造:在 backbone 的 forward 代碼的輸入端插入 Quanstub,輸出端插入 Dequanstub;
加載權(quán)重:在 prepare 之前加載 task_head1 或者 task_head2 的浮點(diǎn)權(quán)重, 在 prepare 之后加載 backbone 的 calib/qat 權(quán)重,這里要特別注意加載權(quán)重的順序;
calibration:配置模型狀態(tài)(如下圖),注意這里模型的狀態(tài)要配置為 VALIDATION,然后進(jìn)行偽量化的精度的驗(yàn)證;
如果某個(gè) head 的精度較差,那么將固定 backbone 的權(quán)重,對此 head 的權(quán)重進(jìn)行微調(diào)。
*博客內(nèi)容為網(wǎng)友個(gè)人發(fā)布,僅代表博主個(gè)人觀點(diǎn),如有侵權(quán)請聯(lián)系工作人員刪除。