視頻跟蹤算法在Davinci SOC上的實(shí)現(xiàn)與優(yōu)化

算法在Davinci SOC上的實(shí)現(xiàn)
本文引用地址:http://www.104case.com/article/269186.htmDSP平臺的選擇
DM6446采用ARM與DSP 雙核結(jié)構(gòu),其中ARM子系統(tǒng)搭載297 MHz主頻的ARM926 核,DSP部分則采用594 MHz的C64x+DSP核,外圍存儲(chǔ)均支持256 MB DDR2 RAM和各類存儲(chǔ)卡,另外使用了VPSS 子系統(tǒng)豐富的視頻前后處理功能,且都配備了完善的外設(shè)接口。目標(biāo)跟蹤算法需要做大量運(yùn)算,DM6446 DSP核強(qiáng)大的運(yùn)算處理能力保證了算法的實(shí)時(shí)處理。同時(shí)DM6446的ARM核可以進(jìn)行系統(tǒng)管理,數(shù)據(jù)讀寫,網(wǎng)絡(luò)傳輸?shù)忍幚怼?/p>
我們使用Spectrum Digital公司的DVEVM平臺進(jìn)行算法仿真、原型制作和軟件優(yōu)化。DVEVM?還可實(shí)現(xiàn)視頻輸入/輸出連接、網(wǎng)絡(luò)接口、存儲(chǔ)器接口以及標(biāo)準(zhǔn)的子卡連接等。
系統(tǒng)軟件框架
整個(gè)系統(tǒng)的軟件框架如圖2如示。DM6446的ARM核運(yùn)行基于Linux操作系統(tǒng)的應(yīng)用程序,所用的外圍設(shè)備都由ARM負(fù)責(zé)控制。ARM端的HTTP服務(wù)器通過Linux網(wǎng)絡(luò)協(xié)議棧來處理HTTP請求,并發(fā)送壓縮視頻數(shù)據(jù)。視頻跟蹤的應(yīng)用程序由五個(gè)POSIX線程組成,分別是視頻捕捉線程,視頻跟蹤線程,視頻壓縮線程,顯示線程,系統(tǒng)控制線程。視頻捕捉線程通過V4L2接口設(shè)備驅(qū)動(dòng)從攝像頭讀取原始視頻數(shù)據(jù)。視頻跟蹤線程把視頻數(shù)據(jù)送到ARM和DSP的共享緩沖內(nèi)存,并通知DSP執(zhí)行跟蹤算法。壓縮線程負(fù)責(zé)控制DSP側(cè)的壓縮算法并從共享內(nèi)存中讀取壓縮數(shù)據(jù)。視頻顯示線程從視頻緩存中讀取視頻數(shù)據(jù)幀,并疊加目標(biāo)跟蹤框,最后通過Frame Buffer設(shè)備驅(qū)動(dòng)輸出顯示。系統(tǒng)控制線程負(fù)責(zé)響應(yīng)遙控器和鼠標(biāo)并執(zhí)行相應(yīng)操作。
DM6446的DSP核上運(yùn)行DSP/BIOS實(shí)時(shí)操作系統(tǒng)和目標(biāo)檢測,跟蹤算法,視頻壓縮算法。所有的算法的接口都符合TI xDAIS標(biāo)準(zhǔn),由Codec Engine調(diào)用。除了算法,DSP核上還集成了管理內(nèi)存和DMA的Framework Component。
ARM核和DSP核的通信由TI提供的Codec Engine軟件框架負(fù)責(zé)。Codec Engine是介于應(yīng)用程序和具體算法之間的軟件模塊,其中的VISA API通過stub和skeleton訪問Engine SPI最終調(diào)用算法。ARM和DSP的所用共享緩沖內(nèi)存都是通過CMEM模塊在DDR中分配的,緩沖內(nèi)存地址連續(xù)且與DSP核Cache對齊。
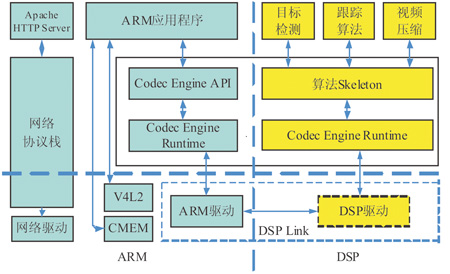
圖 2 軟件結(jié)構(gòu)圖
跟蹤算法在DSP上的優(yōu)化
為了充分發(fā)揮出Davinci SOC強(qiáng)大的視頻處理能力,滿足實(shí)時(shí)跟蹤的需要,我們通過算法優(yōu)化和編程優(yōu)化相結(jié)合的方法對Codec程序進(jìn)行了大量的優(yōu)化。
算法優(yōu)化
算法優(yōu)化是指在不降低算法性能的情況下,采用等效算法來降低計(jì)算量,我們的工作主要集中在“歸一化互相關(guān)系數(shù)”的計(jì)算例程的簡化上。根據(jù)均值和方差的性質(zhì),我們可以將(1)式化簡為:
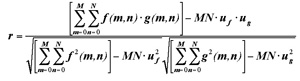
上式與式(1)比較,減少了大量的加減法計(jì)算,而且將方差和協(xié)方差的計(jì)算轉(zhuǎn)化為大量的乘加運(yùn)算,這為我們后面的編程優(yōu)化也提供了極大的便利。例如M=64, N=64時(shí),加法次數(shù)從36864減少到12288。
編程優(yōu)化
編程優(yōu)化是在計(jì)算量不變的情況下,根據(jù)Davinci處理器DSP核心的特點(diǎn),通過優(yōu)化存儲(chǔ)器的存取效率和提高程序的并行化程度來縮短程序運(yùn)行所需要的指令周期數(shù),以使程序運(yùn)行得更快。我們的編程優(yōu)化工作主要包含使用dsplib、使用線性匯編、使用內(nèi)聯(lián)函數(shù)以及循環(huán)展開等五個(gè)方面,下面將一一加以介紹。
* dsplib的使用
在優(yōu)化過程中,我們還采用了CCS中提供的庫函數(shù)來對代碼進(jìn)行優(yōu)化。CCS中針對c64x+ DSP提供了高度優(yōu)化的dsplib庫函數(shù)供用戶使用,這些庫函數(shù)提供了數(shù)字信號處理中常見的處理例程,而且由匯編語言寫成,具有極高效的代碼效率。特別是用于計(jì)算向量內(nèi)積的DSP_dotprod和DSP_vecsumsq函數(shù)正好滿足了我們的計(jì)算需求。在計(jì)算尺寸為32x32的“歸一化互相關(guān)系數(shù)”時(shí),優(yōu)化后計(jì)算
* 線性匯編
對于uf和ug的計(jì)算,如果使用for循環(huán)實(shí)現(xiàn),將會(huì)大大拖累整個(gè)“歸一化互相關(guān)系數(shù)”計(jì)算例程的執(zhí)行效率。我們用手工編寫線性匯編代碼的方式實(shí)現(xiàn)了dspsum函數(shù),利用C64x + DSP中的8個(gè)并行計(jì)算單元,在每個(gè)DSP時(shí)鐘周期內(nèi)同時(shí)進(jìn)行4個(gè)16位加16位的加法操作,對于尺寸為32x32的求和計(jì)算而言,該函數(shù)只需要258個(gè)DSP時(shí)鐘周期。













評論