AI芯片的過去和未來,看這篇文章就夠了

同樣在2016年,谷歌發布了加速深度學習的TPU(TensorProcessingUnit)芯片,并且之后升級為TPU2.0和TPU3.0。與英偉達的芯片不同,谷歌的TPU芯片設置在云端,就像文章在Alpha Go的例子中說的一樣,并且“只租不賣“,服務按小時收費。不過谷歌TPU的性能也十分強大,算力達到180萬億次每秒,并且功耗只有200w。
本文引用地址:http://www.104case.com/article/201811/393690.htm
谷歌TPU芯片 圖片來自網絡,版權屬于作者
關于各自AI芯片的性能,谷歌CEOSundarPichai和英偉達CEO黃仁勛之前還在網上產生過爭論。別看兩位大佬為自家產品撐腰,爭得不可開交,實際上不少網友指出,這兩款產品沒必要“硬做比較”,因為一個是在云端,一個是在終端。
除了大公司,初創企業也在激烈競爭ASIC芯片市場。那么初創企業在行業中該如何生存呢?對此,AI芯片初創企業 Novumind的中國區CEO周斌告訴小探:創新是初創企業的核心競爭力。
2017年,NovuMind推出了第一款自主設計的AI芯片:NovuTensor。這款芯片使用原生張量處理器(NativeTensorProcessor)作為內核構架,這種內核架構由NovuMind自主研發,并在短短一年內獲得美國專利。除此之外,NovuTensor芯片采用不同的異構計算模式來應對不同AI應用領域的三維張量計算。2018年下半年,Novumind剛推出了新一代NovuTensor芯片,這款芯片在做到15萬億次計算每秒的同時,全芯片功耗控制在15W左右,效率極高。

Novumind的NovuTensor芯片
盡管NovuTensor芯片的紙面算力不如英偉達的芯片,但是其計算延遲和功耗卻低得多,因此適合邊緣端AI計算,也就是服務于物聯網。雖然大家都在追求高算力,但實際上不是所有芯片都需要高算力的。比如用在手機、智能眼鏡上的芯片,雖然也對算力有一定要求,但更需要的是低能耗,否則你的手機、智能眼鏡等產品,用幾下就沒電了,也是很麻煩的一件事情。并且據EETimes的報道,在運行ResNet-18、ResNet-34、ResNet70、VGG16等業界標準神經網絡推理時,NovuTensor芯片的吞吐量和延遲都要優于英偉達的另一款高端芯片Xavier。
結合Novumind現階段的成功,我們不難看出:在云端市場目前被英偉達、谷歌等巨頭公司霸占,終端應用芯片群雄逐鹿的情形下,專注技術創新,在關鍵指標上大幅領先所有競爭對手,或許是AI芯片初創企業的生存之道。
類腦芯片
如文章開頭所說,目前所有電腦,包括以上談到的所有芯片,都基于馮·諾依曼架構。
然而這種架構并非十全十美。將CPU與內存分開的設計,反而會導致所謂的馮·諾伊曼瓶頸(von Neumann bottleneck):CPU與內存之間的資料傳輸率,與內存的容量和CPU的工作效率相比都非常小,因此當CPU需要在巨大的資料上執行一些簡單指令時,資料傳輸率就成了整體效率非常嚴重的限制。
既然要研制人工智能芯片,那么有的專家就回歸問題本身,開始模仿人腦的結構。
人腦內有上千億個神經元,而且每個神經元都通過成千上萬個突觸與其他神經元相連,形成超級龐大的神經元回路,以分布式和并發式的方式傳導信號,相當于超大規模的并行計算,因此算力極強。人腦的另一個特點是,不是大腦的每個部分都一直在工作,從而整體能耗很低。
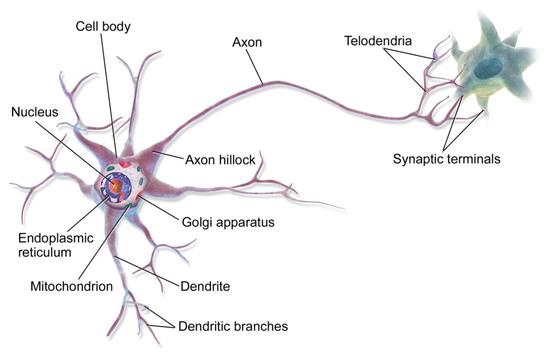
神經元結構 圖片來源:維基百科
這種類腦芯片跟傳統的馮·諾依曼架構不同,它的內存、CPU和通信部件是完全集成在一起,把數字處理器當作神經元,把內存作為突觸。除此之外,在類腦芯片上,信息的處理完全在本地進行,而且由于本地處理的數據量并不大,傳統計算機內存與CPU之間的瓶頸不復存在了。同時,神經元只要接收到其他神經元發過來的脈沖,這些神經元就會同時做動作,因此神經元之間可以方便快捷地相互溝通。
在類腦芯片的研發上,IBM是行業內的先行者。2014年IBM發布了TrueNorth類腦芯片,這款芯片在直徑只有幾厘米的方寸的空間里,集成了4096個內核、100萬個“神經元”和2.56億個“突觸”,能耗只有不到70毫瓦,可謂是高集成、低功耗的完美演繹。

裝有16個TrueNorth芯片的DARPASyNAPSE主板 圖片來自網絡,版權屬于作者
那么這款芯片的實戰表現如何呢?IBM研究小組曾經利用做過DARPA的NeoVision2Tower數據集做過演示。它能以30幀每秒速度,實時識別出街景視頻中的人、自行車、公交車、卡車等,準確率達到了80%。相比之下,一臺筆記本編程完成同樣的任務用時要慢100倍,能耗卻是IBM芯片的1萬倍。
然而目前類腦芯片研制的挑戰之一,是在硬件層面上模仿人腦中的神經突觸,換而言之就是設計完美的人造突觸。
在現有的類腦芯片中,通常用施加電壓的方式來模擬神經元中的信息傳輸。但存在的問題是,由于大多數由非晶材料制成的人造突觸中,離子通過的路徑有無限種可能,難以預測離子究竟走哪一條路,造成不同神經元電流輸出的差異。
針對這個問題,今年麻省理工的研究團隊制造了一種類腦芯片,其中的人造突觸由硅鍺制成,每個突觸約25納米。對每個突觸施加電壓時,所有突觸都表現出幾乎相同的離子流,突觸之間的差異約為4%。與無定形材料制成的突觸相比,其性能更為一致。
即便如此,類腦芯片距離人腦也還有相當大的距離,畢竟人腦里的神經元個數有上千億個,而現在最先進的類腦芯片中的神經元也只有幾百萬個,連人腦的萬分之一都不到。因此這類芯片的研究,離成為市場上可以大規模廣泛使用的成熟技術,還有很長的路要走,但是長期來看類腦芯片有可能會帶來計算體系的革命。
說了這么多,相信讀者們對AI芯片行業已經有了基本的認識。在未來,AI芯片是否會從云端向終端發展?行業中大小公司的激烈的競爭會催生出怎樣的創新和轉型?類腦芯片的研發又能取得哪些突破?關于這些問題,每個人都會有不同的見解,歡迎各位讀者在下面留言。









評論