使用多通道體系結構優化LPDDR4的性能和功耗

tRC定時會導致很多問題,尤其是在更快的器件中更是如此。在LPDDR4的最高速度下,tRC時間超過100時鐘周期。當在LPDDR4的最高速度下工作時,觸發Bank中的某一行后,至少在100時鐘周期內,tRC會阻止訪問該Bank中的其他行,這樣,就會在相當長的時間內禁止再次使用該Bank。如果具有更多的可用Bank,會降低訪問因tRC時間而鎖定的Bank中新行的訪問概率。
tRRD和tFAW會限制頻繁更換存儲體Bank的能力,設計團隊可能希望這樣做,以避開tRC定時參數。
圖12顯示了1個器件示例,它具有4個激活窗口tFAW,具有4倍的行行延遲tRRD。在LPDDR4-3200中,tRRD時間可達16個時鐘周期。
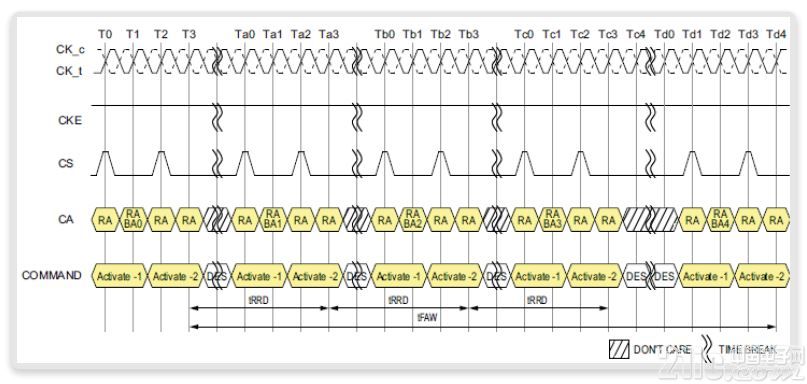
圖12:tFAW和tRRD時序
在圖13中,顯示了在并行實施方案下執行的連續傳輸序列。符號AC/BA0是Bank0觸發命令的代稱。與其相鄰的命令RD/BA4指的是對Bank4的讀取命令(假定Bank4已在較早時間觸發)。每一命令標記代表4時鐘周期,原因在于LPDDR4器件的4相尋址特性。在實際應用中,該序列會需要延長,這是因為在激活(Active)之后會接著讀取、激活、讀取、激活、讀取、激活、讀取。數據返回,完全占用DQ總線,總線處于滿狀態。并行訪問模式會利用100%的內存帶寬,但僅在800MHZ(DDR1600)下訪問器件時才能實現該點。
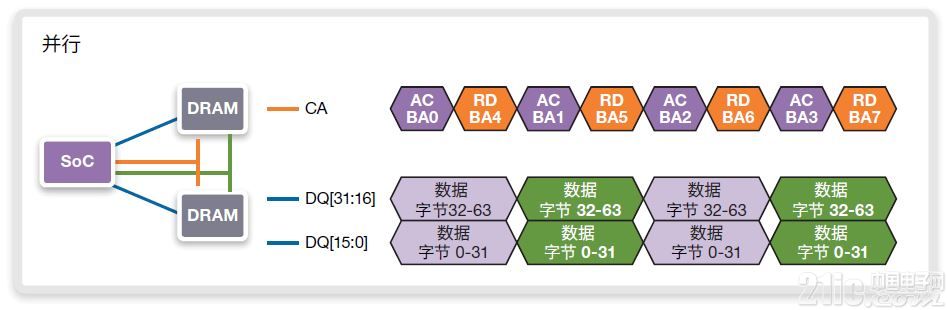
圖13:在BL16和800MHz/DDR1600上使用至旋轉地址的連續64字節讀取的并行實施
圖14中顯示了一種雙通道實施,其中執行了相同的序列,獨立使用每一命令地址通道。每一命令地址總線的訪問模式略有差異:激活、讀取、無操作、讀取、激活、讀取、無操作、讀取。命令通道中的空隙可用于其他方面,如設定的預充或按bank刷新,或簡單地留作空閑時鐘周期。圖中數據總線已被完全占用。
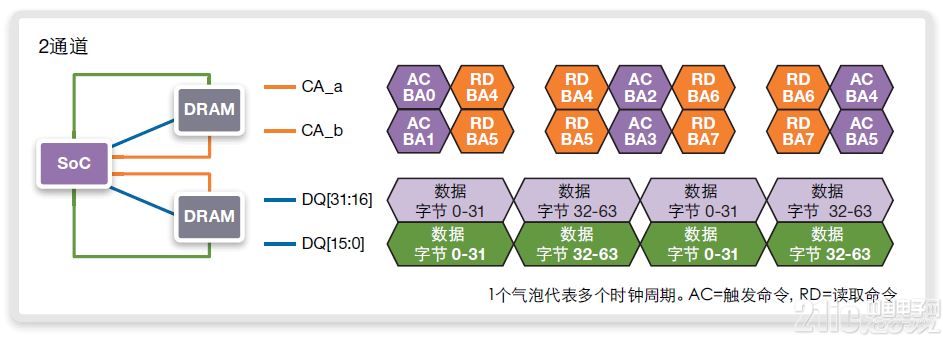
圖14:在BL16和800MHz/DDR1600上使用至循環地址的連續64字節讀取、獨立使用命令地址的雙通道實施
將頻率加倍至1600 MHz(DDR 3200操作)(圖15)時,tRRD時間會限制SOC的能力,允許在并行實施的上方示例中發送激活命令至LPDDR4器件。序列為:激活、讀取、無操作、無操作、激活、讀取、無操作、無操作。無操作周期可用于預充或刷新,但內存的激活速度不足以就每一傳輸向新rank發送連續的64-bank傳輸。
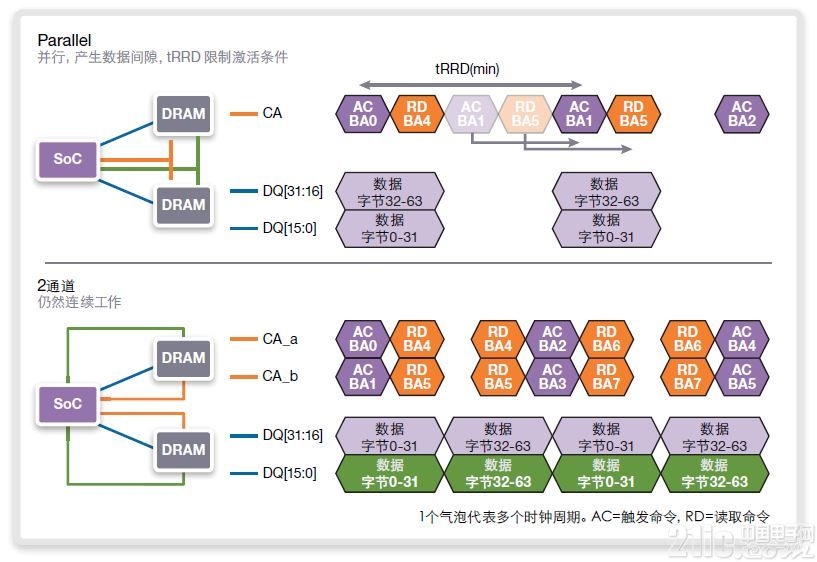
圖15:頻率加倍至1600MHZ/DDR3200
當沒有發向同一內存頁的另一64字節傳輸時,SOC必須等待,直至tRRD期滿并能再次在內存中觸發新頁為止。如果傳輸的時間不足以在移動至新bank之前對每一bank進行兩次讀取,該工作模式會將器件的最大性能限制在50%帶寬下。
與之相比,對于圖15下方的雙通道實施,由于“激活、讀取、無操作、讀取”模式,允許每一通道滿足tRRD的要求。即使在DDR 3200數據率下,總線帶寬也能工作在滿負荷下。
找出最小的塊提取大小
塊提取大小指的是可在一個DRAM事務(一次突發傳輸)中傳輸的最小字節數。由于LPDDR4的最小突發長度為16,采用LPDDR4的并行連接可能使SoC具有不優化的塊提取大小。
最佳方式是使提取大小與SOC匹配,不僅體現在通過總線傳輸的傳輸大小方面,也體現在器件的總帶寬方面。
對于很多SOC和CPU的緩存線,首選塊取大小是32字節。在偶爾情況下,一些較大的64位CPU使用64字節緩沖線。視頻和網絡傳輸通常需要32字節或更小的短字節傳輸。在理想情況下,多通道體系結構應與系統的提取大小匹配,以便將系統優化至系統所能使用的提取大小。
在圖16顯示的并行實施方案中,LPPDDR4最小突發長度為16,有64個的并行DQ引腳,塊提取大小為128字節,它實際上僅適合于至連續地址的長數據傳輸。對于每次以128字節為單位的訪問,并行實施方案能夠工作,然而,如果數據訪問小于128字節且需訪問隨機地址,那么并行實施方案的效率不高。
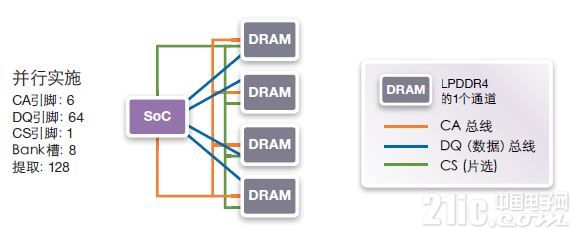
圖16:并行實施
對于64位并行實施方案,另一問題是SOC和DRAM裸片之間的物理連接。LPDDR4 PoP封裝的管腳分配是每一角一個通道,使得封裝包上有4個通道以容納2或4個裸片。每一通道位于器件的每一角。在理想情況下,SOC內存控制器和PHY布局應與LPDDR4的管腳分配匹配。采用該布局,允許將通道A映射到通道A,通道B映射到通道B,C到C,D到D,使得LPDDR4 PoP封裝內的路徑盡可能短,無交叉。該封裝布局還有助于并行4通道LPDDR4接口的物理實現。
用戶還應注意傳輸是否訪問內存中的不同頁,tRRD可能會限制較高頻率下的有效帶寬,如同前述部分中介紹的那樣。
正是由于這些原因,與4通道實施相比,設計者更傾向于選擇LPDDR4的多通道實施。
命令/地址總線
LPDDR4具有很窄的命令/地址總線(每通道僅6位寬,DDR4為20位或以上),因此,使用多個命令/地址通道的開銷低于使用其他DDR類型的開銷。在LPDDR4封裝包上獨立使用所有4個命令/地址總線,能夠提供最大的靈活性,可能還會為整個系統提供最高性能。
LPDDR4 PoP的SOC分割
有多種適用于LPDDR4的SOC分割方式。圖17顯示了最簡單的一種方式。這是一種同構CPU體系結構,它具有4個CPU和4個通道。每一CPU具有自己的方式以訪問自己的獨立通道。該體系結構具有下述優點:CPU不會彼此屏蔽,SOC總線更短。可關閉未使用通道以便節省功耗。
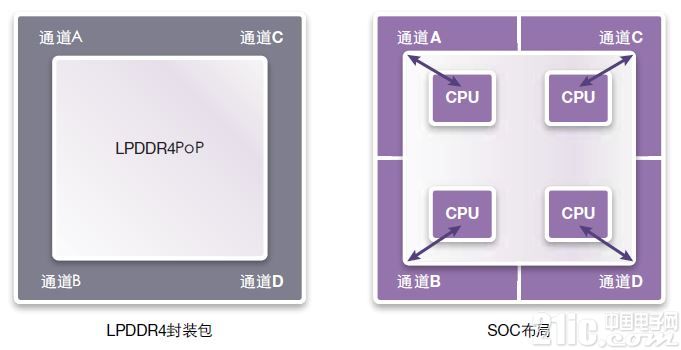
圖17:LPDDR4.PoP的最簡單SOC分割
然而,該體系結構不夠靈活。如果通道A需使用通道C中的一些數據,它無法將內存當作郵箱使用。必須通過SOC以某種方式傳輸數據。這還會使得CPU更難于執行與負載平衡相關的共享任務。
另一方法是使每一CPU共享每一內存(圖18)。這樣就能實現更加靈活的分割。對于異構處理,它的工作表現更好,CPU能夠對共享數據進行處理,但需要更多和更長的片上布線資源,這可能需要用到復雜的片上互聯系統。這樣就能更準確地反映實際芯片的工作方式,尤其是對具有不同CPU、GPU和其他處理單元的異構體系結構而言。
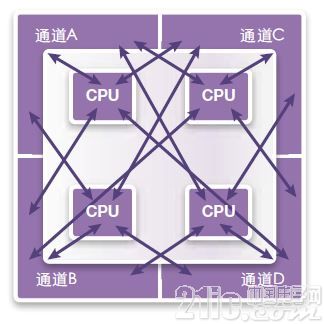
圖18:共享通道,所有CPU共享所有內存
邏輯至物理地址映射
多通道體系結構提供了多種控制邏輯至物理地址映射的選擇。考慮如圖19所示的雙通道體系結構。存在多種控制邏輯至物理地址映射的方式。最簡單的方式是,雙通道存儲器映射到不同的SoC地址空間(圖19)。
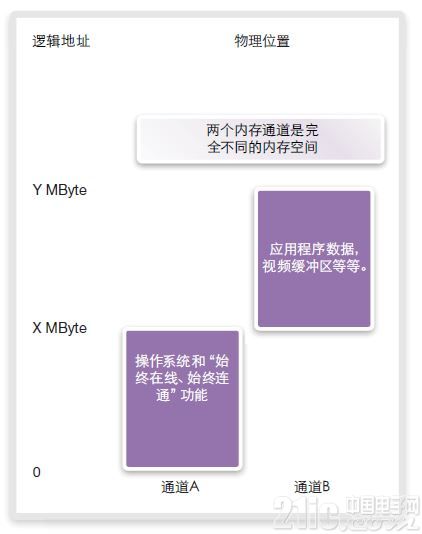
圖19:使用分區內存映射的邏輯至物理地址映射
例如,通道A可能會存放操作系統,并保持始終在線、始終連通的功能。通道B可能包含應用數據,視頻緩沖和類似數據。這兩個不同的地址空間獨立且分離。這有助于功耗控制,原因在于,通道B可在不使用時關閉。
另一方式是,采用較小的連續邏輯地址區訪問內存的不同通道(圖20),對內存映射進行交織處理。例如,通道A為字節0~63,通道B為字節64~127,以此類推,直至遍及整個內存空間。在整個內存上對邏輯空間進行交錯處理。該方法有助于在2個不同通道上實現負載平衡,可實現良好性能。然而,由于始終需要兩個通道,無法關閉任一通道以降低功耗。

圖20:交錯式內存映射
更進一步的實施方案是使用混合內存映射(圖21),其中,每一通道中的不同區可提供交織式訪問或非交織訪問。該混合方法可能包含一個始終在線、始終連接的內存區,以便獲得最高性能而在2個通道之間交織的內存區,以及用于程序存儲的高地址內存區,這類程序與高帶寬相關。
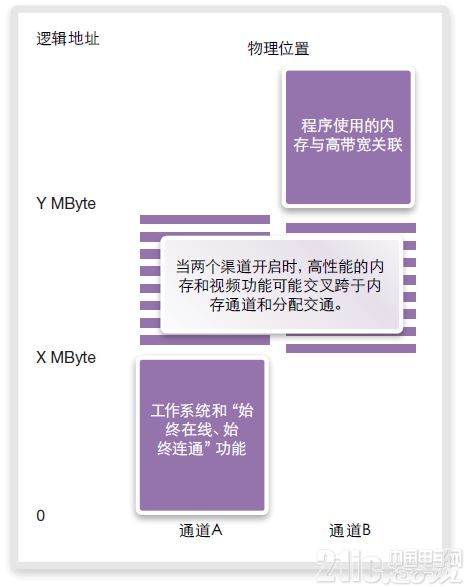
圖21:混合內存映射
針對高性能、低功耗移動SOC的Synopsys LPDDR4 IP解決方案
Synopsys完整的LPDDR4 IP解決方案包括1個內嵌I/O的LPDDR4 multiPHY,增強型通用DDR內存控制器(uMCTL2)和協議控制器(uPCTL2),驗證IP,建模工具,以及IP硬化和信號完整性分析服務。IP完全支持LPDDR4標準,并可靈活配置,以發揮上文所述的多通道體系結構的優點。
Synopsys DDR內存控制器包含uMCTL2內存控制器,它提供了與SOC的多端口或單端口連接。可用總線包括1~16端口的AXI3、AXI4或AHB。對于需要在內存控制器之外做內存傳輸調度的系統,我們提供了單端口協議控制器uPCTL2。
uMCTL2具有低延遲、高帶寬和強大的QOS特性,包括QOS驅動的仲裁和高性能內存調度算法。內存控制中的低功耗功能具有自動的特點,允許設計團隊將重心放在系統設計方面。他能夠支持包括DDR2、DDR3、DDR4、LPDDR2、LPDDR3和LPDDR4等多種內存標準。對于車載應用和其他高可靠性系統,IP提供了多種可靠性、可用性、可服務性(RAS)特性。
面向LPDDR4的uMCTL2內存控制器提供了一種基于CAM的調度架構,尤其針對2667-4266的數據率進行了優化,并支持多種地址映射機制,為不同使用模式和多內存類型的系統提供了高度靈活性。它具有自動斷電功能,自刷新功能以及快速頻率轉換功能,支持自動溫度監測和刷新率調節。
結論
LPDDR4多通道規范為新穎的系統設計提供了新的機會,尤其是多通道體系結構可以改善系統性能。設計團隊需要綜合考慮性能、功耗和設計復雜度來部署實施LPDDR4架構。





評論