看懂芯片后端報(bào)告 這篇文章最實(shí)用

對(duì)于動(dòng)態(tài)功耗,后端還可以定制晶體管的源極和漏極的長(zhǎng)度,越窄的電流越大,漏電越高,相應(yīng)的,最高頻率就可以沖的更高。所以我們有時(shí)候還能看到uLVT C16,LVT C24之類的參數(shù),這里的C就是指Channel Length。
本文引用地址:http://www.104case.com/article/201702/344323.htm接下去就是Memory,又作Memory Instance,也有人把它稱作FCI(Fast Cache Instance)。訪問(wèn)Memory有三個(gè)重要參數(shù),read,write和setup。這三個(gè)參數(shù)可以是同樣的時(shí)間,也可以不一樣。對(duì)于一級(jí)緩存來(lái)說(shuō)基本用的是同樣的時(shí)間,并且是一個(gè)時(shí)鐘周期,而且這當(dāng)中沒(méi)法流水化。從A73開(kāi)始,我看到后端的關(guān)鍵路徑都是卡在訪問(wèn)一級(jí)緩存上。也就是說(shuō),這段路徑能做多快,CPU就能跑到多快的頻率,而一級(jí)緩存的大小也決定了索引的大小,越大就越慢,頻率越低,所以ARM的高端CPU一級(jí)緩存都沒(méi)超過(guò)64KB,這和后端緊密相關(guān)。當(dāng)然,一級(jí)緩存增大帶來(lái)的收益本身也會(huì)非線性減小。之后的二三級(jí)緩存,可以使用多周期訪問(wèn),也可以使用多bank交替訪問(wèn),大小也因此可以放到幾百KB/幾MB。
邏輯和內(nèi)存統(tǒng)稱為Physical Library,物理庫(kù),它是根據(jù)工廠給的每個(gè)工藝節(jié)點(diǎn)的物理開(kāi)發(fā)包(PDK)設(shè)計(jì)的,而Library是一個(gè)Fabless芯片公司能做到的最底層。能夠定制自己的成熟物理庫(kù),是這家公司后端領(lǐng)先的標(biāo)志之一。
最后一行,Margin。這是指的工廠在生產(chǎn)過(guò)程中,肯定會(huì)產(chǎn)生偏差,而這行指標(biāo)定義了偏差的范圍。如下圖:
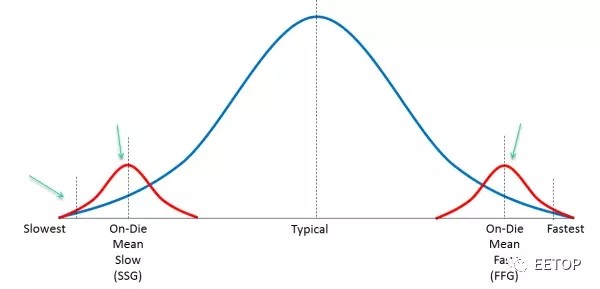
藍(lán)色表示我們剛才說(shuō)的一些Corner的分布,紅色表示生產(chǎn)偏差Variation。必須做一些測(cè)試芯片來(lái)矯正這些偏差。SB-OCV表示stage-based on-chip variation,和其他的幾個(gè)偏差加在一起,總共±7%,也就是說(shuō)會(huì)有7%的芯片不在后端設(shè)計(jì)結(jié)束時(shí)確定的結(jié)果之內(nèi)。
后面還有一些setup UC之類的,表示信號(hào)建立時(shí)間,保持時(shí)間的不確定性(Uncertainty),以及PLL的抖動(dòng)范圍。
至此,一張報(bào)告解讀完畢,我們?cè)倏纯磳?duì)應(yīng)的低功耗版實(shí)現(xiàn)版本:
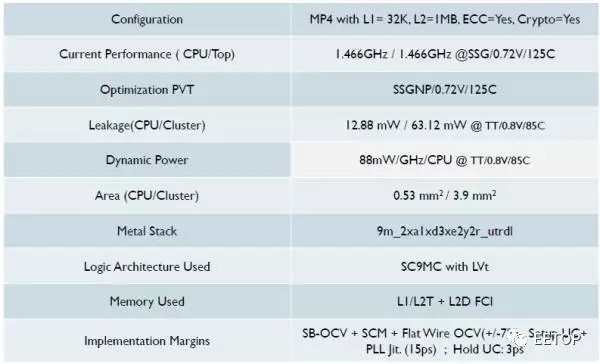
這里頻率降到1.5G左右,每Ghz動(dòng)態(tài)功耗少了10%,但是靜態(tài)降到了12.88mW,只有25%。我們可以看到,這里使用了LVT,沒(méi)有uLVT,這就是靜態(tài)能夠做低的原因之一。由于面積不是優(yōu)化目標(biāo),它基本沒(méi)變,這個(gè)也是可以理解的,因?yàn)镃hannel寬度沒(méi)變,邏輯的面積沒(méi)法變小。











評(píng)論