基于優化GDTW-SVM算法的聯機手寫識別

4 實驗結果與分析
本文主要針對阿拉伯數字樣本集和英文字母樣本集進行識別實驗,阿拉伯數字樣本集、英文小寫字母樣本集和英文大寫字母樣本集分開識別。實驗環境是Matlab R2010a,所使用的SVM工具包是Matlab SVM Toolbox。
分類實驗采用Leave-One-Out的交叉驗證策略:依次從樣本集中取出一個字符的訓練樣本標記為第一類,將剩余字符的訓練樣本標記為第二類,用標記后的訓練樣本訓練GDTW-SVM;使用樣本集中的所有測試樣本測試GDTW-SVM的識別率。
使用未優化GDTW-SVM重復分類識別10次,取10次實驗結果的平均值作為未優化GDTW-SVM的識別結果;其次,優化GDTW-SVM的參數(K,τ)分別取(0.2,0.5)、(0.2,0.2)和(0.5,0.5),分別重復分類識別10次且取10次識別結果的平均值作為使用該組參數的優化GDTW-SVM的識別結果,最終取三組識別結果中的最優識別結果作為優化GDTW-SVM的識別結果;以上實驗中,γ=1.9。本文引用地址:http://www.104case.com/article/193871.htm
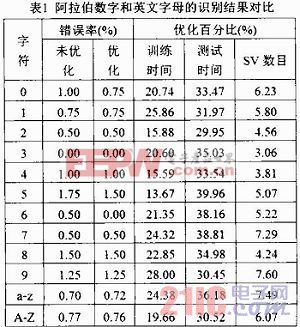
表1是阿拉伯數字和英文字母的識別結果對比。其中,英文字母數目較多,因此,僅給出平均識別結果。優化后的GDTW-SVM和未優化的GDTW-SVM的實驗結果對比顯示:參數k和τ的引入不僅使字符識別的錯誤率基本保持不變,同時,訓練時間減少13~25%、測試時間減少29~39%、支持向量的數目也減少3.0~7.6%。
5 結論
本文提出了在GDTW核函數中引入參數k和τ,約束GDTW最優對齊路徑的計算空間,然后構造GDTW-SVM分類器。實驗結果表明,優化后的GDTW-SVM分類器的識別率與未優化的分類器的識別率基本相同;同時,支持向量數目減少,計算時間有13%~39%的減少,有利于GDTW-SVM分類器的聯機手寫識別的應用和推廣。

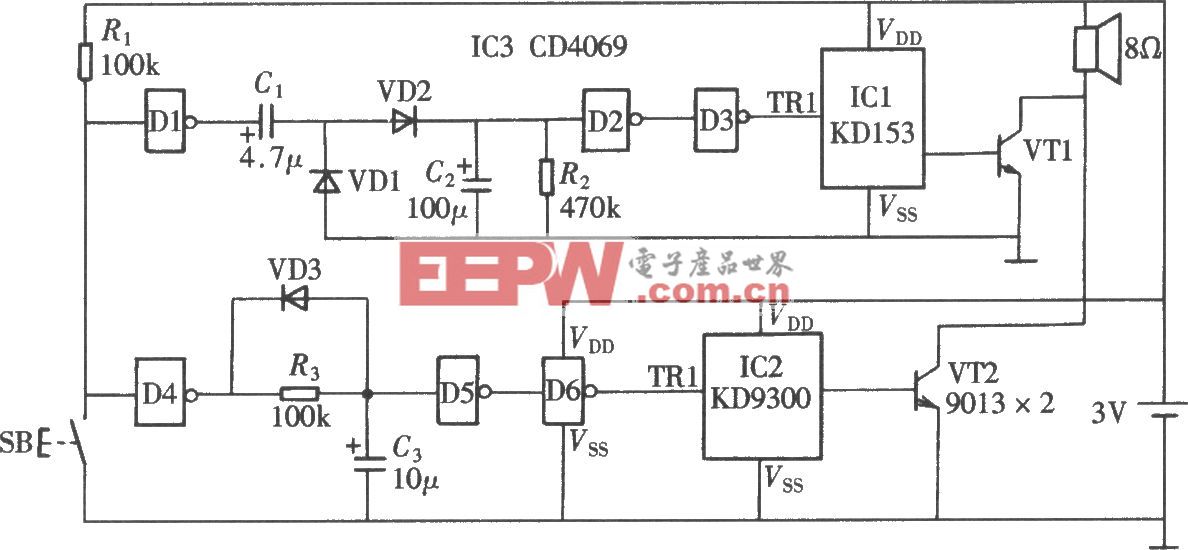

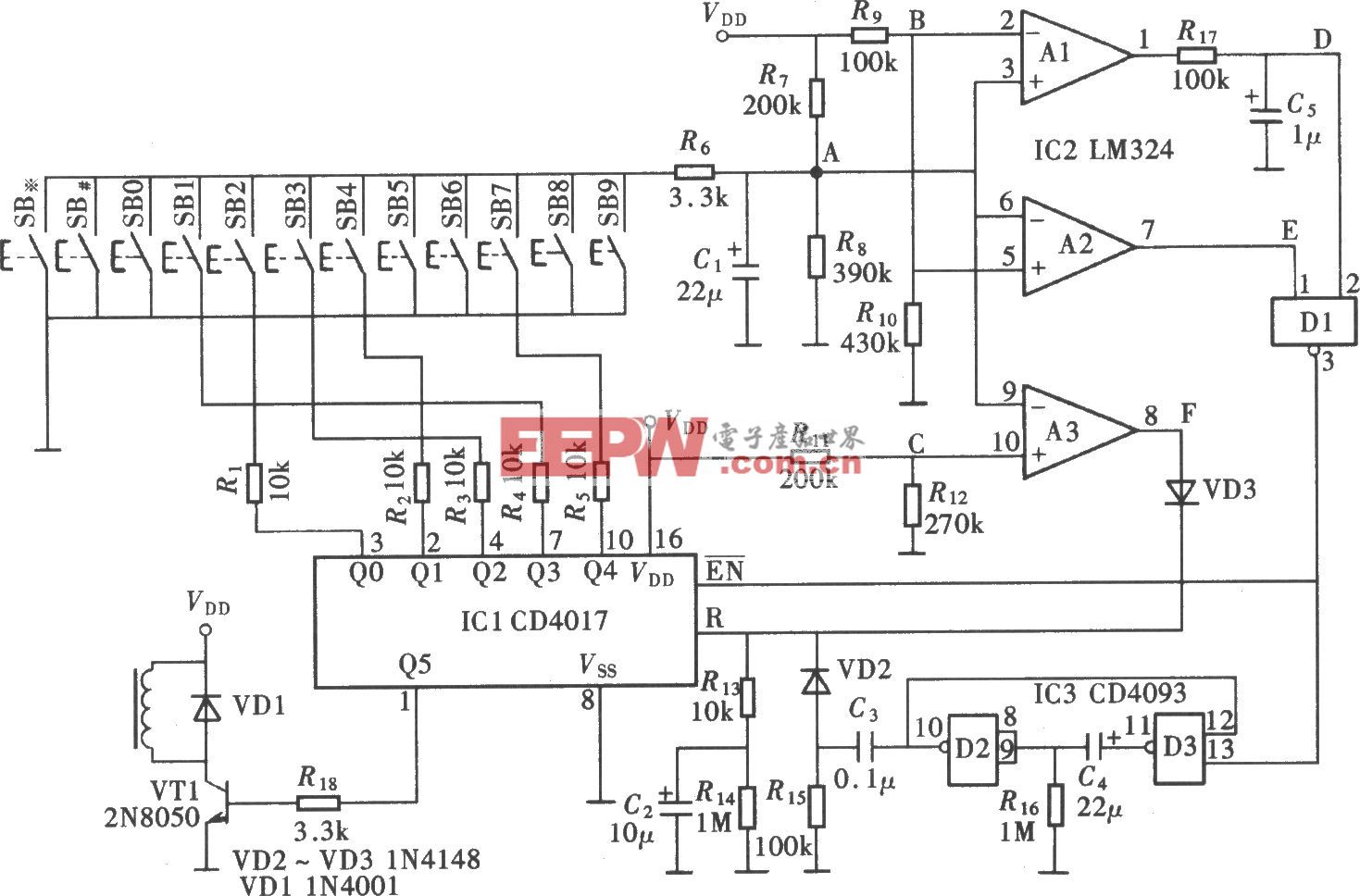
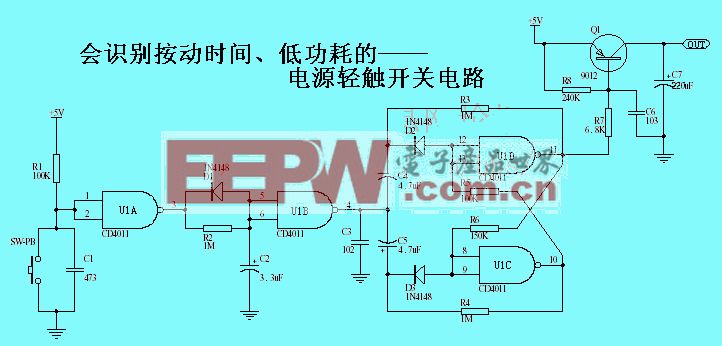
評論