20×18位符號(hào)定點(diǎn)乘法器的FPGA實(shí)現(xiàn)

2 32位浮點(diǎn)乘法器的實(shí)現(xiàn)與仿真測(cè)試
該模塊仿真實(shí)現(xiàn)用Mentor Graphics公司的Model-Sim SE 6.0d仿真軟件,圖5列出本設(shè)計(jì)的:FPGA仿真結(jié)果。圖5中in1是被乘數(shù)20 b。in2是乘數(shù)18 b。reset是復(fù)位清零信號(hào),低電平有效。booth_multiplier_out是用Booth編碼乘法器算出來的結(jié)果38 b。derect_multiplier_out是直接用乘號(hào)“×”得到的結(jié)果,也是18 b。兩者結(jié)果一致。round_out是舍入后的結(jié)果,20 b。eq是測(cè)試時(shí)加的一個(gè)1 b信號(hào),如果booth_multiplier_out和derect_multiplier_out相等為1,否則為0。
由于在測(cè)試時(shí),將輸入和輸出都用寄存器鎖存了一個(gè)時(shí)種clk,最后輸出結(jié)果延了2個(gè)時(shí)種clk,在圖5中,第一個(gè)時(shí)種clk,輸入乘數(shù)和被乘數(shù)分別為126 999,68 850;輸出結(jié)果為第3個(gè)時(shí)種clk的8 743 881 150。因?yàn)?26 999×68 850=8 743 881 150,故結(jié)果正確。在測(cè)試時(shí),因?qū)嶋H數(shù)據(jù)量比較大,in1從-219~219-1,ModelSim SE 6.0d仿真軟件需要運(yùn)行大概1 min,若in1從-219~219-1,in2從-217~217-1大概需要時(shí)間T=218min=4 369 h=182 day,因此在PC機(jī)上不能全測(cè),故在寫testbench時(shí),用random函數(shù)產(chǎn)生隨機(jī)數(shù)測(cè)試,該乘法器用ModelSim仿真軟件運(yùn)行12 h,eq信號(hào)始終為1,即乘法器算出的結(jié)果與直接乘的結(jié)果一致,認(rèn)為該方法完全可行。本文引用地址:http://www.104case.com/article/192021.htm

3 性能比較與創(chuàng)新
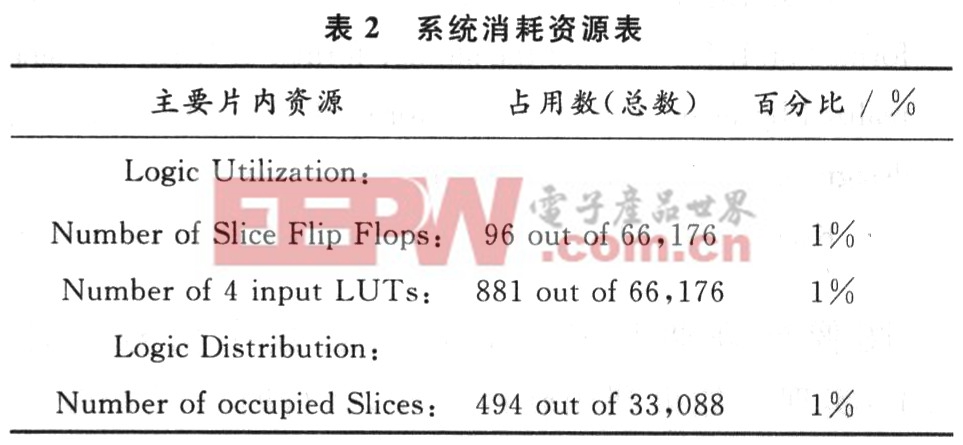
該模塊用Synplify Pro8.1綜合,用XilinxISE 7.1i實(shí)現(xiàn)布局布線。在Xilinx ISE中ImplementDesign下Map報(bào)告系統(tǒng)占用資源如表2所示。
而靜態(tài)時(shí)序分析報(bào)告顯示速度和延時(shí)分別為62.805 MHz,15.922 ns。
該設(shè)計(jì)采用高壓縮率的4―2壓縮算法,壓縮率為50%,而一般的3-2壓縮壓縮率為33%,并且采用先進(jìn)的集成電路制造工藝,使用SMIC公司O.18μm的標(biāo)準(zhǔn)單元庫,因此在提高了速度的同時(shí),能減少器件,該乘法器能在1個(gè)時(shí)鐘內(nèi)完成,不像采用流水線結(jié)構(gòu),雖然可以提高速度到105.38 MHz,但需3個(gè)時(shí)鐘,需要大量鎖存器,從而在增加器件的同時(shí)增加功耗,而且完成一次乘法運(yùn)算時(shí)間要24.30 ns。因國內(nèi)集成電路制造起步晚,目前中國80%的集成電路設(shè)計(jì)公司還在采用0.35/μm及以下工藝,國內(nèi)同類乘法器,采用上華0.5 μm的標(biāo)準(zhǔn)單元庫,完成1次乘法運(yùn)算時(shí)間接近30 ns,邏輯單元是1 914個(gè)。但該設(shè)計(jì)完成1次乘法運(yùn)算時(shí)間僅15.922 ns,器件只有494個(gè)Slices,性能明顯提高。
4 結(jié) 語
給出了20×18位符號(hào)定點(diǎn)乘法器的設(shè)計(jì),整個(gè)設(shè)計(jì)采用了Verilog HDL語言進(jìn)行結(jié)構(gòu)描述,采用的器件是xc2vp70-6ff1517。該設(shè)計(jì)采用基4 Booth編碼,4-2壓縮,以及采用SMIC0.18μm標(biāo)準(zhǔn)單元庫,使得該乘法器面積降低的同時(shí),延時(shí)也得到了減小,做到芯片性能和設(shè)計(jì)復(fù)雜度之間的良好折中,該設(shè)計(jì)應(yīng)用于中國地面數(shù)字電視廣播(DTMB)ASIC中3 780點(diǎn)FFT單元的20×18位符號(hào)定點(diǎn)乘法器,在60 MHz時(shí)工作良好,達(dá)到了預(yù)定的性能要求,具有一定的實(shí)用價(jià)值。








評(píng)論