片上多核處理器共享資源分配與調度策略研究綜述(三)

接上文
本文引用地址:http://www.104case.com/article/148026.htm3 聯合調度
前面兩章分別對于共享緩存和DRAM 提出了相應的調度算法,但這只是系統中眾多共享資源里最為重要的兩種。實際上在多線程環境下,線程還會對于其他包括系列總線和I/O 設備等共享資源進行爭奪,線程間互相干擾,對系統性能造成影響。
一方面,針對不同的共享資源獨立提出的調度算法間從效果上可能互相矛盾。例如,同一個線程在共享緩存和主存處分別表現出的訪存行為特征未必一致,再根據各自的調度策略,分別設定的優先級可能相反,使得調度失效。另一方面,從不同層面提出的調度策略之間也可能存在矛盾。例如,底層硬件層面的調度對線程的優化可能使得操作系統層面對于線程優先級的設定反轉。因此,從全局出發,綜合考慮所有共享資源,進行聯合調度是極有研究價值的。
Ebrahimi 等在文獻中為了解決線程的公平性問題,提出一個可以協調所有共享存儲資源的機制稱為公平性資源節源( fairness via sourcethrottling,FST),從而避免了需要為系統中每個共享存儲資源提出單獨的公平性機制。該機制使用前面在STFM中提到的線程減速比Mi=Tshd_i/Tsolo_i信息 , 用一組失效狀態信息寄存器(miss statusholding/informatiON registers,MSHRs)記錄各線程發向共享存儲系統的請求,請求得到服務后相應寄存器清空,當沒有可用的MSHRs 時,則禁止該線程向共享存儲系統發送請求。系統的不公平性通過下式衡量:
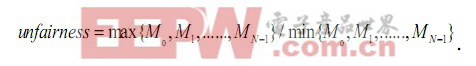
當unfairness 超過某個設定閾值時,表示有線程的性能降低程度已經嚴重影響到系統的公平性。可以通過調節可用MSHRs 數目來限制侵略性最強(或受影響最小)的線程向共享存儲系統發送訪存請求的速率,直到各線程的減速比基本保持一致水平,即unfairness 小于設定閾值,恢復受限制線程發送訪存請求的能力。這個方法從源頭上限制對共享存儲資源的不公平性使用,從而無需從單個共享存儲資源特別提出公平性的調度策略。
由于對DRAM 進行訪存的速度提升遠不及處理器速度的提升,訪存DRAM 所帶來的延遲常常是影響性能的一個關鍵因素。一個解決方案是,預測線程可能需要的數據,在處理器實際用到該數據之前就發送訪存請求從DRAM 取回數據。該技術稱之為預取(prefetching),已被證明確實能夠有效改善系統性能,并被用于大多數商業處理器中。
然而,各個線程發向DRAM 的預取請求,同樣存在對于系統資源的爭奪和線程間的干擾,從而抵消由于預取部件所帶來的性能改善。Ebrahimi 等人在文獻中提出了分層預取侵略性控制( hierarchical prefetcher aggressiveness control ,HPAC),類似于文獻[24]中的FST,HPAC 通過從源頭上限制預取請求的發送來改善系統的預取性能。
為了降低問題的復雜性,之前提出的調度策略都是針對沒有采用預取技術的情況。為了更好地改善系統性能,我們總是希望調度策略和預取技術能夠同時生效。然而,實驗發現,即使采用已被證明有效的調度策略,在加入預取技術之后,調度策略仍然可能失效,使系統的性能受到影響。因此,Ebrahimi 等人在文獻中的研究,解決了預取技術與調度策略的共存問題,并將文獻中提出的FST 和HPAC 相結合。該項研究的基本思想包括如下幾點:首先,預取請求涉及的通常只是處理器未來可能用到的數據,而非當前急需的數據,因此,除非某些預取請求有著和普通訪存請求同樣的重要性,預取請求的優先級應該低于普通的訪存請求;其次,在所有訪存請求中優先來自延遲敏感型線程的訪存請求;并且,對預取請求按重要性分配不同的優先級;最后,FST 中對于處理器發送請求的調節可能與HPAC 對于預取請求的調節存在矛盾,通過協同考慮處理器和預取部件,可以有效降低對系統性能的影響。
Ebrahimi 等人在文獻中的探索對于解決系統共享資源的聯合調度是很好的啟發。這些調度策略將所有共享資源抽象為一個整體,從源頭上解決系統的公平性問題,但是并沒有充分利用具體共享資源的訪存特點。若能夠將不同層次的調度策略有效結合起來,將會對對系統的性能有進一步的改善。
4. 研究展望
隨著處理器核規模的增長,多線程對于有限的共享資源的爭奪將愈發激烈,由此導致的對于系統性能的影響也將更加顯著。為了緩解乃至解決這一問題,除了增加可用共享資源外,一個能夠公平有效地在多線程間分配共享資源的調度算法也至關重要。學術界對此投入了大量的精力與時間。在各類共享資源中,對于系統性能有著最大影響的是共享緩存和DRAM 帶寬。已有的研究也大多基于此,并已經取得了大量研究成果。
在第1 節中,我們分別以系統吞吐量和公平性為優化目標介紹了一系列對共享緩存的分區調度算法,并針對緩存分區粒度過大的問題給出了相關解決方案;在第2 節中,從利用線程的訪存行為特征和借鑒網絡路由算法等多個角度介紹了DRAM 的調度算法,并研究了基于機器學習的自我強化的調度算法;在隨后的第3 節中,研究了從全局出發的聯合調度算法,以解決針對不同共享資源的調度算法間相互矛盾的問題。上述研究都在一定程度上解決了我們如今所面臨的問題,但是隨著眾核時代的來臨,一些調度算法的復雜度和相應的硬件開銷都可能大幅增長,導致這類調度算法失去實用性。針對調度算法在未來的系統中對共享資源的合理分配中所存在的應用潛力和面臨的問題,我們認為仍然有問題可以展開進一步的研究:
1)如前所述,制定有效的緩存分區策略需要知道各線程的緩存需求,以及各線程從分配的單位粒度的緩存空間取得的收益。為了獲取上述信息,Suh等人在文獻中提出了的MON,隨后,Qureshi等在此基礎上提出了改進的UMON[4].基于UMON的系列研究分別針對共享緩存的吞吐量和公平性做出了有效改進。在文獻中提出的zcache又解決了緩存分區粒度過大的問題,可以以較小的粒度將共享緩存分為數十個分區,使得緩存分區策略的可擴展性增強,能夠應用于更大規模的CMP系統中。但是由于利用UMON 獲取信息需要在每個核保留一份標簽目錄備份ATD.當核數較多且共享緩存較大時,會產生比很大的硬件開銷。另外,如圖1 所示,各個核將UMON 收集的信息送至一個緩存分區模塊,集中進行緩存分區策略的制定。這種全局式的做法在眾核時代會導致緩存分區模塊面臨過高的計算復雜度。
下一步研究,可以采用分布式的緩存分區策略:
由于共享數據的存在,先按照線程來源將共享緩存劃分為幾個子區,每個子區內的線程應該來自同一應用,共享某些數據;然后在各個子區內,根據不同線程的需求制定適當的緩存分區策略,每個子區還應該保留一部分緩存空間來存儲共享數據。分布式的緩存分區策略一方面可以大大降低計算復雜度,同時又充分利用了緩存分區以及共享數據的優點,將會更好地提高系統性能。
另外,設計一類新的緩存替換算法,使其能夠區分對待來自不用線程的不同請求,并執行適當的替換操作,也能夠有效緩解共享緩存的爭奪,并且避免了緩存分區所帶來的開銷。由于這種新的緩存替換算法需要更多的信息,可能需要在緩存的Tag中加入一些新的域,替換算法的復雜度也會增加。
2)對于DRAM 的調度策略,現有的研究方向可以主要分為兩類。一類研究大多從組成訪存請求的底層操作出發,充分利用DRAM 結構特點和線程的訪存行為特征,例如行緩存相關性,塊級并行性以及訪存密集度等;這類研究能夠有效利用DRAM帶寬,有助于提高系統吞吐量。另一類研究則從網絡公平調度算法得到啟發,以DRAM 系統的公平性為優化目標,其中以FQM和STFM等為代表;這類研究存在的問題是將訪存請求抽象為一個整體看待,沒有充分利用DRAM 的結構特點和線程的訪存行為,系統吞吐量往往不高。一個將這兩類研究的優點有機結合起來的算法,能夠同時做到改善系統公平性并保證吞吐量。
從另一角度看,如果能夠從源頭上減少訪存請求的行沖突,提高塊級并行性,將更有利于提高系統性能。因此,還可以從如下兩個思路進行研究:
DRAM 訪存由于不同線程訪存請求的交互執行帶來的行沖突是影響系統性能的一個重要因素,借鑒緩存分區的思想,通過操作系統地址映射使得不同線程的訪存請求訪問不同的DRAM 塊,可以降低行沖突,提高行命中率。
另外,改變DRAM 的邏輯結構(通過增加channel,rank 等概念),使得一個線程的不同訪存請求被映射到更多的塊,提高其塊級并行性,也可以有效提高性能。
3)系統中包括大量共享資源,之前的研究為了更有針對性以及降低研究的復雜度,通常只涉及其中一種共享資源的調度。但是實際上系統中的各類共享資源并非彼此獨立的,調度算法之間可能相互矛盾,使得調度失效。因此,從全局出發,綜合考慮所有共享資源提出調度算法是有必要的。在文獻中給出的調度算法,利用MSHRs 從源頭上控制各線程向共享存儲系統的發出訪存請求的頻率和數量,從而實現系統的公平性。這對于全局統一調度是很好的啟發。
隨著工藝發展,功耗管理已經成為一個不得不面對的問題。功耗管理需要要保證多核系統的總功耗不超過功耗預算(power budget),所以,功耗也是另一種重要的共享資源。調節功耗的主要手段之一是降低處理器核的頻率,則其產生訪存請求的頻率也將降低,實際上起到與MSHRs 類似的效果,同時還不需要帶來硬件開銷。通過調節頻率,使得多個訪存密集型線程訪問共享存儲系統的時間段錯開,可以有效減緩共享存儲系統的壓力。一個好的策略可以做到同時兼顧功耗管理和訪存調度兩方面的需求,實現全局的統一調度。
5 結束語
本文首先介紹了在CMP 系統中,由于線程間對于有限共享資源的爭奪,調度算法的必要性和重要性,然后根據不同的優化目的介紹了對于共享緩存的一系列緩存分區算法,同時從不同角度出發介紹了一些DRAM 訪存調度算法,接下來研究了綜合考慮共享資源的聯合調度算法,并對于未來的共享資源調度算法的研究進行了展望。
考慮到隨著將來CMP 系統中處理器數目規模會越來越大,對于共享資源的爭奪將更加激烈,設計調度算法的難度也將顯著增加,這項工作也將更具挑戰性。因此,設計公平有效的調度算法將更有必要。






評論