FAE講堂:如何加快處理器的正弦計算

我們使用一些Slice和乘法器,對這些硬件模塊中的兩個進行例化。兩個內核都要求4到5個周期的延遲,以匹配我們設計的時序要求。延遲在此不是什么問題,我們將在下面的步驟中進行討論。
本文引用地址:http://www.104case.com/article/119301.htm我們將最終的IP以MicroBlaze的快速單工鏈路 (FSL) IP 的形式進行實現。對時序的第一次估算結果表明:
• 將數據從MicroBlaze傳輸到FSL總線需用一個時鐘周期
• 將數據從FSL總線傳輸至FSL IP(當正弦計算的自變量從FSL總線讀出時,將立即從BRAM讀取數據,因而無需時鐘周期)需用一個時鐘周期
• 完成MUL運算 (cos(x)*sin(d)) 需用四個時鐘周期
• 將方程的結果存儲到寄存器中需用一個時鐘周期
• 完成ADD運算需用四個時鐘周期
• 將數據發送回FSL總線需用一個時鐘周期
• MicroBlaze從FSL IP讀取數據需用一個時鐘周期。
請注意,在沒有使用任何額外流水線(我們將在下一步驟中討論這一點)的情況下,自變量數據在整個過程中必須保持穩定。這就意味著MicroBlaze僅能請求一次正弦計算,且必須讀取該值,然后至少要等上13個時鐘周期,才能請求下一次計算。
因此,我們估計進行該實現需要13個時鐘周期。當然,要處理軟件上的函數調用以及某些其他運算,還需要更多的時鐘周期。
我們簡單地把一些標準時鐘組合在一起,不到一天就實現了該IP,隨即在硬件中對該算法進行測量。整個算法(軟硬件混合)耗用了360個時鐘周期(包括所有的函數調用)。雖然這已是顯著的進步,但是仍不足以充分滿足客戶的需求。
在我們的加速器IP處理所有數據之前,我們使用一個SRL16來延遲信號的寫入。
雖然該算法現在可與我們的MicroBlaze并行運行,但它每次只能計算一個值。
步驟六:添加流水線和適配客戶代碼
設計到了這一步,我們就可以開始向我們的內核添加流水線。浮點ADD和浮點MUL的CORE Generator模塊已采用流水線實現,因而我們在此無需再做什么。第一個版本的算法要求自變量保持恒定,直至計算完成。在開始新計算之前(自變量數據到達FSL IP內部),立刻讀取兩個BRAM并執行浮點MUL。運算的結果在數個時鐘周期后生效。
我們的 sin(xi) 的自變量 xi 是一個20位寬的整數,它分為 x 和 d 兩個部分。因此,我們必須對自變量 xi的MSB部分 x 進行幾個時鐘周期的延遲,以讀取 BRAM 的內容,存儲自變量xi,并將其與MUL運算的結果相匹配。
我們為我們的10位寬數值使用了少量SRL16元件(總共 10 個),共占用了10個LUT(但由于Spartan-6具有LUT組合功能,如果采用該器件較寬的LUT6結構,則僅需 5 個 LUT 即可)。
最后的工作量相當小。在圖4中已對增加的SRL16x10位用紅圈進行了標注。
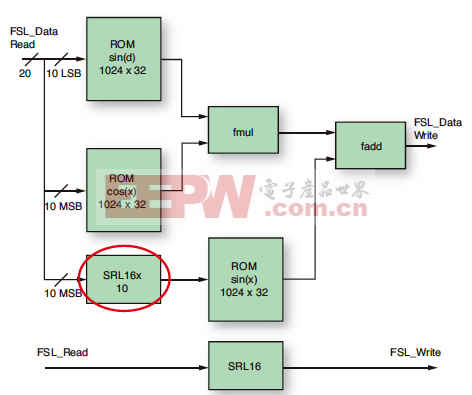
然后我們使用EDK向導來修改我們的FSL總線FIFO,以便存儲多個值(我們確定能夠存儲8個值就足以達到我們的目的,但可根據需要輕松增加更多)。
這就意味著我們的客戶甚至在請求第一個結果之前即能獲得多達8個值。這足以滿足我們客戶當前的需求,但如果想請求更多正弦值的話,則可以輕松將FIFO緩沖參數擴展為較大的值。
我們在與客戶討論這種新的方案時,發現可將正弦計算進一步劃分為兩個部分:
1. 請求正弦計算(fslput 運算)
2. 請求正弦計算的結果(fslget運算)
由于我們在運算中有一個固定時延,所以如果這兩個運算依次銜接、緊密地按順序執行,那么MicroBlaze將停頓,并等待FSL IP完成對請求的處理。如果能夠將這兩組運算分開(這在客戶的算法中是可以的),那么我們即可進一步提
升運算的總體速度。通過增加流水線, 在MicroBlaze上執行的最終代碼如下:
putfsl(arg1,fsl1_id);
putfsl(arg2,fsl1_id);
putfsl(arg3,fsl1_id);
putfsl(arg4,fsl1_id);
putfsl(arg5,fsl1_id);
putfsl(arg6,fsl1_id);
putfsl(arg7,fsl1_id);
putfsl(arg8,fsl1_id);
...
getfsl(result1,fsl1_id);
getfsl(result2,fsl1_id);
getfsl(result3,fsl1_id);
getfsl(result4,fsl1_id);
getfsl(result5,fsl1_id);
getfsl(result6,fsl1_id);
getfsl(result7,fsl1_id);
getfsl(result8,fsl1_id);
這給我們帶來了顯著的優勢。內核不僅可完全實現流水線功能,而且還能夠將正弦計算的兩個調用分開。IP核的時延依然存在,但不再明顯。MicroBlaze也不再發生停頓和等待未完成的IP計算的情況,從而提高了整體性能。
客戶同意對代碼進行相應調整,這對客戶來說只是小量工作。通過使用C語言的宏命令取代函數調用,我們就能夠把所有要求的調用插入代碼庫中。







評論