性能好于臺積電3納米!英特爾公布Intel 4工藝技術細節

關注公眾號,點擊公眾號主頁右上角“ · · · ”,設置星標,實時關注半導體行業最新資訊
來源:EETOP
英特爾將在 VLSI 技術會議上展示他們的Intel 4工藝。近期,來自英特爾的 Bernhard Sell (Ben) 向媒體簡要介紹了Intel 4這一工藝,并為我們提供了早期訪問該論文的機會。
“Intel 4 CMOS 技術采用先進的 FinFET 晶體管,針對高密度和高性能計算進行了優化。”
該論文包括判斷工藝密度所需的關鍵間距,性能數據顯示在具有實際單位的圖上,并且討論提供了有關工藝的有用信息。英特爾已經公布了未來四個節點(Intel 4、3、20A 和 18A)的路線圖,其中包含日期、設備類型和性能改進目標。他們現在正在提供有關Intel 4的更多詳細信息。相比之下,三星面臨著從 3nm 開始的風險,并且已經披露了 PPA(功率、性能和面積)目標,但沒有其他細節,對于 2nm,他們已經披露這將是他們的第三個新一代 Gate All Around (GAA) 技術將于 2025 年到期,但沒有性能目標。臺積電已經披露了目前處于風險啟動中的 3nm 的 PPA,對于 2nm,風險啟動日期已經披露,但沒有關于性能或設備類型的信息。在深入了解 Intel 4 的細節之前,我想評論一下這個制程的目標。當我們仔細研究細節時,很明顯這個過程是針對英特爾內部用于制造計算塊(compute tiles)的,它不是一個通用的代工工藝。Intel 4 將于今年晚些時候發布,Intel 3 將于明年發布;Intel 3 是英特爾代工服務的重點。具體來說,Intel 4 沒有I/O Fin,因為在僅與基板上的其他芯片通信的計算塊上,這毫無用處。并且Intel 4 僅提供高性能單元并且沒有高密度單元。Intel 3 將提供 I/O Fin和高密度單元,以及更多的 EUV 使用和更好的晶體管和互連。Intel 3 旨在成為Intel 4 的簡單端口。Intel 4 使用目標在深入了解 Intel 4 的細節之前,我想評論一下這個工藝制程的目標。當我們了解細節時,很明顯這個過程是針對英特爾內部用于制造計算塊(compute tiles)的,它不是一個通用的代工工藝。Intel 4將于今年晚些時候發布,Intel 3將于明年發布;Intel 3是英特爾代工服務的重點。具體來說,Intel 4沒有 I/O 鰭,因為它們不需要在僅與基板上的其他芯片通信的計算塊上,并且Intel 4僅提供高性能單元并且沒有高密度單元。Intel 3 將提供 I/O 鰭片和高密度單元,以及更多的 EUV 使用和更好的晶體管和互連。工藝密度任何讀過我以前的文章和比較的人都知道我非常強調密度。在 Intel 4 論文的圖 1 中,他們披露了 Intel 4 的關鍵間距并將其與 Intel 7 進行比較,見圖 1。
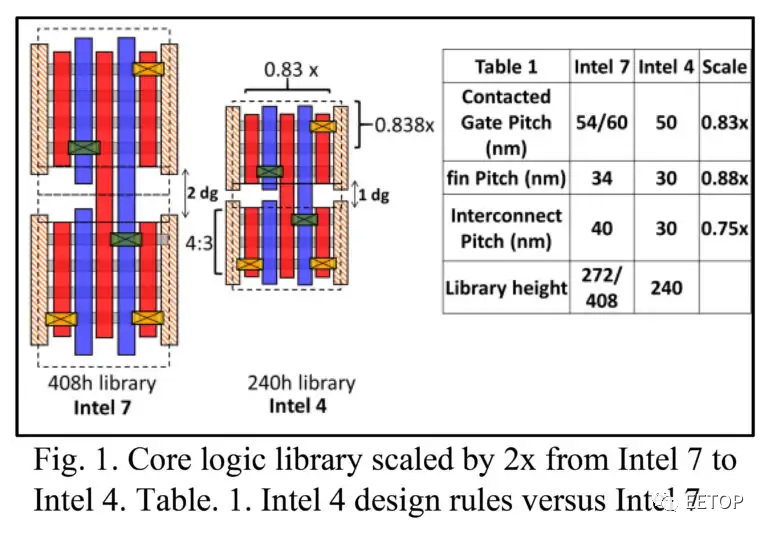
圖 1. Intel 4 與 7 間距
Intel 7的高性能單元高度 (CH) 為 408 納米,Intel 4為 240 納米。Intel 7 的 Contacted Poly Pitch (CPP) 為 60,Intel 4 為 50,Intel 7 的 CH 和 CPP 的乘積為 24,480nm 2,Intel 4 為12,000nm 2,為高性能提供了約 2 倍的密度提升單元。與 Intel 7 相比,Intel 4 的每wall性能提高了 20%,高密度 SRAM 擴展了 0.77 倍。為了更好地了解英特爾最近的工藝進展是有用的。我們給出了四代英特爾 10nm 工藝總結,如圖2。
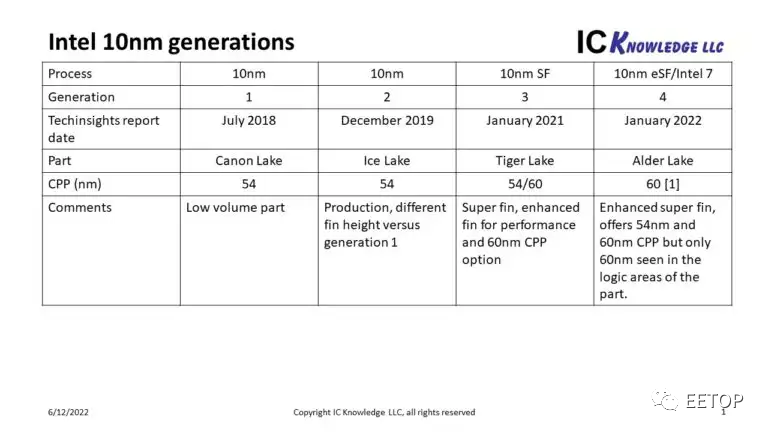
圖 2. Intel 10nm
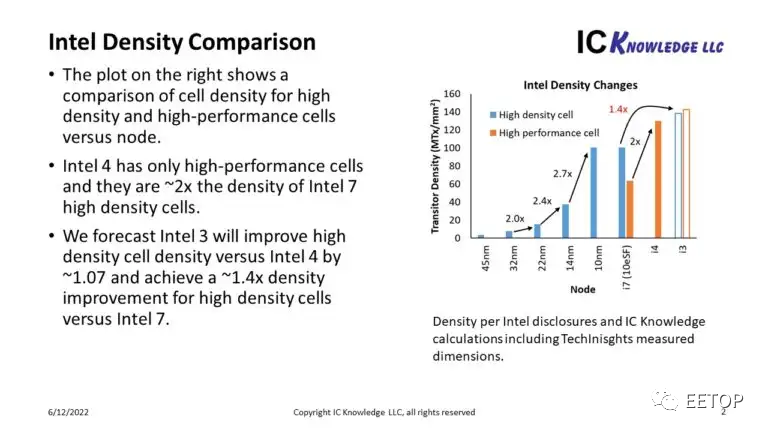
TechInsights 于 2018 年 7 月首次分析了英特爾 10nm,并將其稱為第 1 代, TechInsights 于 2019 年 12 月完成的另一次 10nm 分析,發現相同的密度但不同的鰭片結構,我們將其稱為第 2 代。2021 年 1 月,TechInsights 分析了 10nm Super Fin 部件提供 60nm CPP 選項以提高性能以及原始 54nm CPP(第 3 代)。最終在 2022 年 1 月,TechInsights 分析了 10nm 增強型 Super Fin 部件,英特爾現在稱之為Intel 7(10nm 第 4 代)。關于Intel 7分析結果的一件有趣的事情是 TechInsights 僅在邏輯區域發現 60nm CPP,沒有 54nm CPP 和更高的單元。我描述工藝密度的政策是以工藝上可用的最密集的單元為基礎。對Intel 7來說,高272納米的54納米CPP單元是 "可用的",但沒有使用,而高408納米的單元與60納米的CPP產生的晶體管密度為每平方毫米約6500萬個晶體管(Mtx/mm2)。因此,我們如何將英特爾4號與前幾代工藝和即將推出的英特爾3號工藝相比較,見圖3。我表征工藝密度的策略是基于工藝中可用的最密集單元。對于 Intel 7,272nm 高的 54nm CPP 單元“可用”但未使用,而 408nm 高單元和 60nm CPP 產生的晶體管密度為每平方毫米約 6500 萬個晶體管,而前幾代約為 100 MTx/mm2。那么我們如何將Intel 4與上一代工藝和即將推出的Intel 3工藝進行對比,見圖 3。
另一個有趣的比較是Intel 4 高性能單元尺寸與 TSMC 5nm 和 3nm 的高性能單元尺寸,見圖 4。
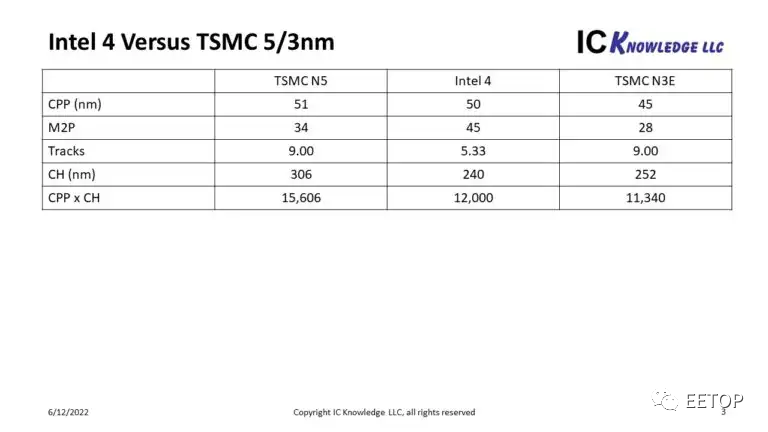
對于 Intel 4,CPP 為 50nm,M2P 為 45nm(在簡報中披露,但未在論文中),對于引用的 240nm CH 和 CPP x CH 為 12,000nm2,這產生的軌道高度僅為 5.33. 這些值與 4 名稱一致,因為它位于領先的代工公司臺積電的 N5 和 N3 之間,想比臺積電 N5 ,Intel 4更接近臺積電 N3。我們也相信 Intel 4 的性能會略好于臺積電 N3。
令我驚訝的是,英特爾的高性能單元的高度剛好超過 5 條軌道,但這是公開的單元高度和 M2P 的數學計算。
DTCO從設計-技術-協同優化 (DTCO) 的角度來看,Intel 4比Intel 7有 3 項改進:
- Contact Over Active Gate 針對 Intel 4 進行了優化。
去除偽柵極的擴散中斷過去需要兩個偽柵極(雙擴散中斷),Intel 7 變為 1(單擴散中斷)。
n 到 p 間距曾經是兩個鰭片間距,現在是 1 個鰭片間距。當我們在 M2P 和軌道方面談論 CH 時,很容易忘記設備必須適應相同的高度,圖 5 說明了 n 到 p 間距如何影響單元高度。

性能表現Intel 10/7 提供 2 個閾值電壓(2 個 PMOS 和 2 個 NMOS = 總共 4 個)和 3 個閾值電壓(3 個 PMOS 和 3 個 NMOS = 總共 6 個)版本。Intel 4 提供 4 個閾值電壓(4 個 PMOS 和 3 個 NMOS = 8 個)。這導致功耗降低約 40%,性能提高約 20%。
我相信簡報中提到的驅動電流值對于 PMOS 是 2mA/μm,對于 NMOS是 2.5mA/μm。
EUV 使用EUV 用于工藝的后端和前端。英特爾將 EUV 的使用重點放在了單次 EUV 曝光可以取代多次浸沒式曝光的地方。盡管 EUV 曝光比浸入式曝光更昂貴,但用相關的沉積和蝕刻步驟代替多次浸入式曝光可以節省成本,提高周期時間和產量。事實上,Ben 提到單次 EUV 曝光導致 EUV 取代的部分中的步驟減少了 3-5 倍。Intel 7到Intel 4看到掩碼和步數減少。在生產線的前端,EUV 專注于替換復雜的切割、柵極或接觸。英特爾沒有明確披露 EUV 用于鰭片圖案化,但我們認為Intel 7片鰭片圖案化涉及一個心軸掩模(英特爾稱其為光柵掩模)和 3 個切割掩模(英特爾稱這些掩模掩模)。對于 Intel 4,這可以很容易地轉換為 4 cut mask。沒有提到用單個 EUV 掩模替換 4 個切割掩模的層,我們相信這可能就是發生這種情況的地方。
在論文中,英特爾提到 M0 是四重圖案。對于英特爾 10/7,英特爾還披露了四重圖案化,TechInsights 分析表明需要 3 個塊掩模。Intel 4可能需要 4 個用于 M0 的塊掩模,這可能是 EUV 消除 4 個切割/塊掩模的另一個地方。
網格布局用于互連以提高產量和性能。
我們相信在這個過程中使用了大約 12 次 EUV 曝光,但英特爾沒有透露這一點。
互連眾所周知,英特爾在 10nm 時為 M0 和 M1 選擇了鈷 (Co)。Co 提供比銅 (Cu) 更好的電遷移電阻,但電阻更高(作者指出,金屬的電遷移電阻與熔點成正比)。對于英特爾 4,英特爾采用了“增強型”銅方案,其中純銅被包裹在鈷中(過去英特爾摻雜銅)。將 Cu 封裝在 Co 中的典型流程是用 Co 層放置阻擋層,作為電鍍的種子。一旦電鍍完成并平坦化以形成互連,Cu 就會被 Co 覆蓋。該過程導致電遷移電阻與 Co 相比略有下降,但仍高于 10 年壽命目標,并且線路的電阻降低。事實上,即使 Intel 4 的互連線比 Intel 7 的互連線更窄,RC 值仍然保持不變。
該工藝有 5 個增強銅層、2 個巨型金屬層和 11 個“標準”金屬層,共 18 層。
MIM caps隨著電力傳輸的重要性日益增加,金屬-絕緣體-金屬 (MIM) 電容器被用于減少功率波動,并不斷得到改進。對于英特爾的 14nm 工藝,實現了 37 fF/μm 2,10nm 提高到 141 fF/μm 2 ,Intel 7提高到193 fF/μm 2 ,現在Intel 4提高了約 2 倍,達到 376 fF/μm 2。更高的值使 MIM 電容器具有更大的電容,從而提高功率穩定性,而不會占用過多的空間。
生產基地在問答環節中,Ben 還被問及生產地點。他說,最初的生產將在Hillsboro,然后是愛爾蘭。他說他們沒有透露除此之外的其他生產計劃。
我們相信英特爾目前擁有約 10 到 12 個 EUV 設備,直到最近它們都在 Hillsboro。其中一個設備現已移至愛爾蘭的 Fab 34,我們相信,隨著英特爾今年收到更多 EUV設備,他們將能夠擴大 Fab 34。今年晚些時候,我們預計以色列的 Fab 38 將開始加速生產,我們相信這將成為下一個英特爾 4/3 生產基地。隨后在 2023 年下半年,亞利桑那州的 Fab 52 和 62 應該開始接收 EUV設備。
產量和準備情況在整個簡報中,我們聽到的關于產量的一切都是“健康的”和“按計劃進行的”。Meteor Lake 計算塊已啟動并在進程中運行。該工藝已準備好在明年下半年生產。結論我對這個過程印象深刻。我越是將它與臺積電和三星的產品進行比較,我的印象就越深刻。在 2000 年代和 2010 年代初,英特爾是邏輯處理技術的領導者,之后三星和臺積電以卓越的執行力領先。如果英特爾繼續走上正軌并在明年發布Intel 3,他們將擁有一個在密度上具有競爭力并且可能在性能上處于領先地位的代工工藝。英特爾還制定了 2024 年英特爾 20A 和 18A 的路線圖。三星和臺積電都將在 2024/2025 年推出 2nm 工藝,它們需要在 3nm 工藝上進行重大改進,以跟上英特爾的步伐。
*博客內容為網友個人發布,僅代表博主個人觀點,如有侵權請聯系工作人員刪除。


