TI:使用CLT工具優化C6000代碼

摘要
本文引用地址:http://www.104case.com/article/274177.htm在C6000 DSP的開發過程中,優化是必不可少的一個環節,根據對象不同可以分為系統,算法,代碼以及內存優化。通常,開發者熟悉自己的代碼,會從前三個方面修改以獲得整體性能的提升,但是對于內存尤其是緩存(Cache)的優化,因為其涉及到芯片本身的架構,Cache的維護由DSP自動完成,用戶通常不能干預,所以似乎無從著手;考慮到這些實際的問題,從TI的7.0系列編譯器開始支持使用緩存優化工具(Cache Layout Tools)對C6000代碼進行優化,通過這一系列的工具,可以很輕松的完成L1P Cache性能的提升,本文詳細介紹了該工具的使用方法。
1.引言
目前,使用TI DSP的用戶越來越多,在C6000系列DSP中,包含了C64x, C64x+, C66x等。在C6000 DSP的開發過程中,為了充分利用DSP的計算資源,需要對用戶程序進行優化的工作,根據對象不同可以分為系統,算法,代碼以及內存優化。通常,開發者熟悉自己的系統和代碼,可以比較方便的從前三個方面修改以獲得整體性能的提升,但是對于內存尤其是緩存(Cache)的優化,因為其涉及到芯片本身的架構,Cache的維護由DSP自動完成,用戶通常不能干預,所以似乎無從著手;考慮到這些實際的問題,從TI 的7.0 系列編譯器開始支持使用緩存優化工具(Cache Layout Tools)對C6000代碼進行優化,通過這一系列的工具,可以很輕松的完成L1P Cache性能的提升,本文詳細介紹了該工具的使用方法。
2.C6000 DSP內核緩存機制
C6000系統的存儲器結構如下圖所示。
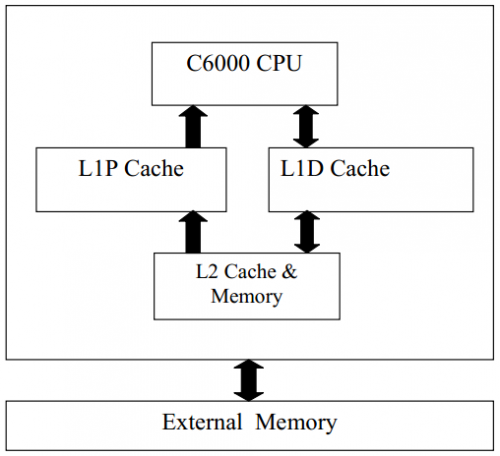
Figure 1.C6000存儲器結構
存儲器分成三級:第一級是L1,包括數據存儲器(L1D)和代碼存儲器(L1P);第二級是代碼和數據共用存儲器(L2以及MSMC SRAM);第三級是外部存儲器,主要是DDR存儲器。L1P、L1D和L2的Cache功能分別由相應的L1P 控制器、L1D控制器和L2控制器完成。
在C6000 DSP中通常我們會把L1P全部配置成Cache,當CPU發出取指命令,首先會從L1P里查找,如果L1P找不到,則到下一級Cache或者Memory里查找,當找到需要的地址,則將其讀入L1P里,CPU從中讀取執行。
因為L1P Cache的大小是有限的(本文以32KB為例),而用戶內存空間一般大于32KB,必須采取一種映射的方式使得所有地址都能被L1P緩存;在C6000 DSP中,L1P Cache使用地址直接映射,所有DSP 核可訪問的地址對L1P Cache大小(32K)取模就能得到該地址在L1P Cache的偏移值。
如果用戶代碼在內存排布不合理,可能會在L1P Cache中發生反復的內容替換,下圖中的例子是一個極端情況。
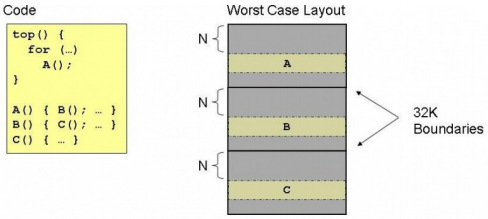
Figure 2. 函數的不正確排布
TOP函數中FOR循環反復調用A 函數,而A,B,C三個函數在內存地址的分布上,與32KB邊界的偏移地址是一樣的,因此,A,B,C將對應L1P里同一個CACHE位置;其運行流程如下
當執行A時,CPU需要把A函數調入到Cache偏移值N的位置上;
A調用B,此時調入B到Cache偏移值N 的位置上,覆蓋A的代碼;
B調用C,此時調入C到Cache偏移值N 的位置上,覆蓋B的代碼;
C返回,下一次循環調入A到Cache中覆蓋C的代碼。
DSP核對L1P,L2,DDR的訪問速度差異很大,對L1P的訪問通常在1 個時鐘周期內完成,而L2平均需要3-5個周期,DDR訪問需要的時間更多,因此我們應該盡量避免上述這種反復重寫Cache的情況,盡可能的減少函數在Cache中的置換。
如何解決該問題?最好的解決方法則是將A,B,C在內存中連續排放,這樣對Cache的操作次數將降到最低,能夠有效的提高執行效率,如下圖所示,只要A,B,C總的大小不超過32KB,它們在Cache中的偏移值就是連續的,不會發生覆蓋的現象,即使其總和大于32KB,發生置換的也僅僅是超過32K的部分。
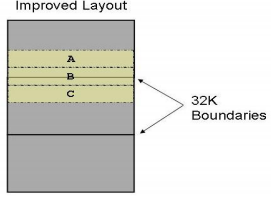
Figure 3. 函數的正確排布
3.內存優化工具
通過上述機制可以看到,對于L1P Cache的優化主要通過分析函數調用關系和其在內存的分布。由于用戶代碼日益復雜,人工分析代碼調用關系和地址排布需要花費大量的時間。因此,從7.0系列編譯工具開始,TI提供了一套內存優化工具(Cache Layout Tools)來幫助用戶輕松快捷地解決該問題。
該工具的原理是在用戶進行程序編譯時打開生成分析信息選項,編譯器會自動加入分析記錄代碼到用戶程序里,之后用戶在TI DSP simulator或者DSP芯片上運行該可執行文件,內置的分析代碼會自動記錄用戶的函數調用關系及調用次數。運行的案例越多,記錄的信息會更詳細,優化的效果也就越好。
在得到函數運行時信息以后,就可以使用編譯器工具對其進行分析,生成函數排布的順序,最后將此排布順序輸入到編譯器里重新編譯原代碼,生成的可執行文件就已經優化過內存排布,具體的操作可以參照以下實例。
4.實例教程
該實例主要由三個C文件組成,

實例中使用DSP計數器TSCL來統計cycle數,子函數放在sub目錄下。
使用實例的步驟如下,
1.編譯代碼
使用TI編譯器對該實例進行編譯,為了產生用于profile的信息,需要在編譯時增加--gen_profile_info選項。如果使用命令還形式,命令行下運行Compile.bat文件,cl6x的具體參數可以參考spru186和spru187兩篇文檔,一般可以在編譯器的安裝目錄下找到他們,如C:Program Files(x86)Texas InstrumentsC6000 Code Generation Tools 7.3.9doc。

同時在目錄下生成OBJ和ASM文件,這個和我們的實驗關系不大,可以不用關注。out文件是一會需要下載到芯片里運行的可執行文件,而map文件用于幫助我們定位profile信息存放的內存地址。
如果用戶使用CCS編譯工具,則需要在Build的屬性里指定Feedback選項,然后正常編譯即可生成攜帶分析代碼的可執行文件。
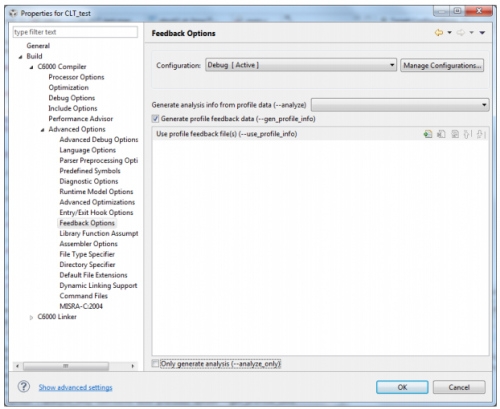
Figure 4. CCS初編譯的選項

存儲器相關文章:存儲器原理
塵埃粒子計數器相關文章:塵埃粒子計數器原理




評論