新舊GPU對決:Blackwell憑啥更能打?

本周,亞馬遜網(wǎng)絡(luò)服務(wù)宣布推出其首款基于 Nvidia 的「Grace」CG100 CPU 和「Blackwell」B200 GPU 的 UltraServer 預(yù)配置超級計算機,稱為 GB200 NVL72 共享 GPU 內(nèi)存配置。這些機器被稱為 U-P6e 實例,實際上有全機架和半機架配置,它們補充了去年 12 月在 re:Invent 2024 會議上推出的現(xiàn)有 P6-B200 實例。
在 P6 和 P6e 實例的情況下,GPU 和 NVLink Switch 4 GPU 內(nèi)存共享交換機上的 NVLink 5 端口用于將 GPU 組整合到大型共享內(nèi)存計算復(fù)合體中,類似于 CPU 服務(wù)器存在了 25 多年的 NUMA 集群。其他非 NUMA 共享內(nèi)存架構(gòu)比非統(tǒng)一內(nèi)存訪問技術(shù)更古老,如對稱多處理或 SMP,但沒有像 NUMA 在 CPU 上的擴(kuò)展,在單核處理器時代,NUMA 在共享內(nèi)存集群中推到了 128 和 256 個 CPU。
基于 Nvidia NVL72 設(shè)計的 P6e 實例,我們在這里詳細(xì)介紹了這些設(shè)計,GPU 內(nèi)存域橫跨 72 個 GPU 插槽,Blackwell 芯片每個插槽有兩個 GPU 芯片,因此內(nèi)存域?qū)嶋H上是單個機架中的 144 個設(shè)備。AWS 正在銷售具有 72 或 36 個 Blackwell B200 插槽的 UltraServers 作為內(nèi)存域,估計這是虛擬完成的,而不是物理完成的,因此可以即時配置實例大小。這些機器每兩個 Blackwell B200 GPU 配對一個 Grace CPU,整個 shebang 是液冷的,這也是 B200 GPU 超頻 11% 的原因之一,并為人工智能工作負(fù)載提供更多的原始計算性能。
P6 實例使用更標(biāo)準(zhǔn)的 HGX-B200 服務(wù)器節(jié)點,這些節(jié)點沒有超頻,并創(chuàng)建了一個跨越八個套接字的 GPU 內(nèi)存域。P6 實例使用英特爾至強 6 處理器作為其主機計算引擎,每八個 Blackwell B200 GPU 有兩個 CPU,產(chǎn)生的計算復(fù)合體密度是 GB200 NVL72 系統(tǒng)的一半,因此仍然可以風(fēng)冷。
隨著這兩個 Blackwell 系統(tǒng)現(xiàn)在在 AWS 云上可用,并且價格信息可用,現(xiàn)在是對 Blackwell 實例進(jìn)行一些價格/性能分析的最佳時機,與前幾代「Hopper」H100 和 H200 GPU 以及基于「Ampere」A100 和「Volta」V100 GPU 的早期實例進(jìn)行一些價格/性能分析,這些實例仍然可以在 AWS 云上租用。
我們檢查的實例和 UltraServer 機架規(guī)模配置是在 AWS 所謂的 EC2 容量塊下出售的,顧名思義,這是預(yù)訂和購買預(yù)配置的 UltraClusters 的一種方式,其大小從一個實例或 UltraServer 到多達(dá) 64 個實例或機架,期限長達(dá)六個月,最多在您需要容量的八周前。這是一個預(yù)留實例的時髦版本,以更大的塊狀形式作為單個單元出售。
只是為了好玩,我們采取了 EC2 容量塊配置,還找到了按需定價的設(shè)置,看看這些在成本上如何比較,一直到基于 Nvidia Volta GPU 的 P2 實例和基于 Ampere GPU 的 P3 實例。
因此,未來不假說,這是 EC2 容量塊的所有電子表格的母體,價格顯示在全球可用的地區(qū),包括 Nvidia GPU 實例以及 AWS Trainium1 和 Trainium2 實例:
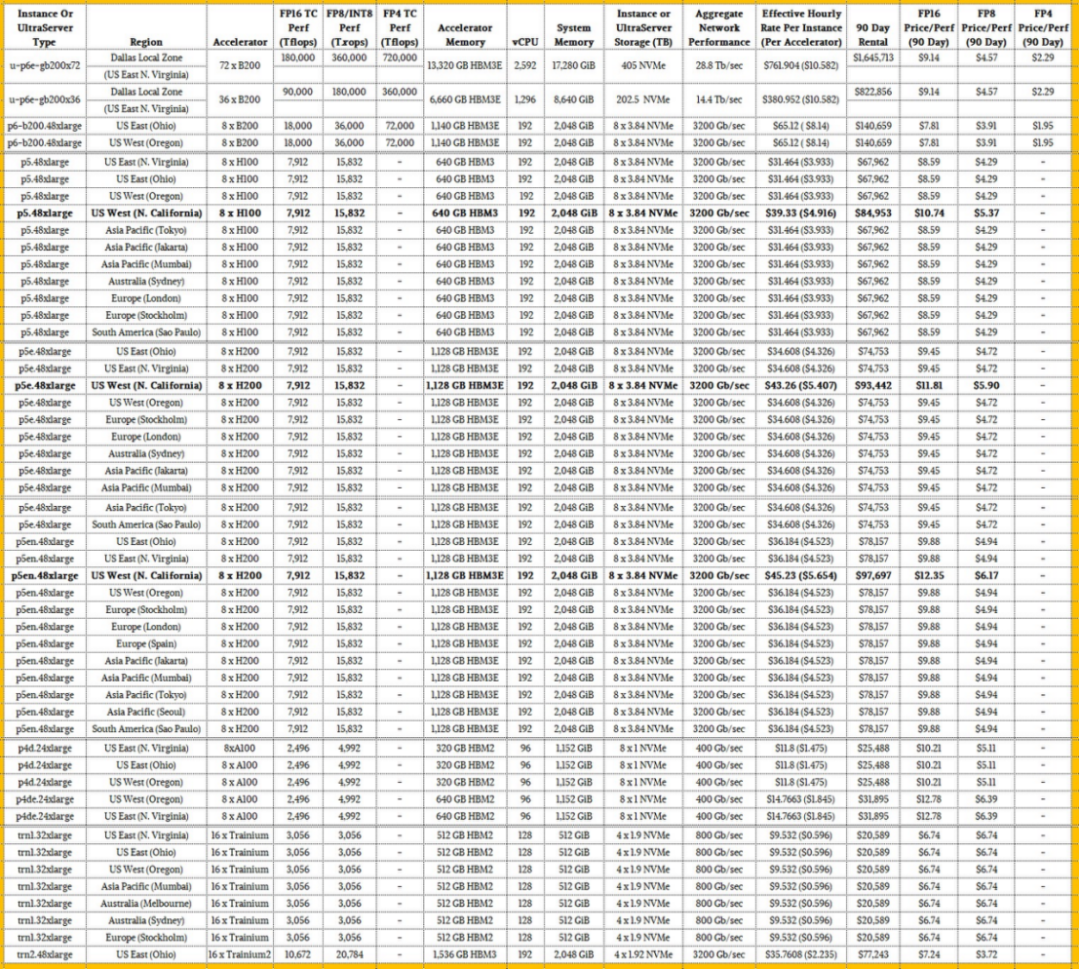
那里有很多東西需要接受。為了了解價格/性能是如何疊加的,我們添加了 FP16、FP8 或 INT8 和 FP4 精度的峰值理論性能。為了進(jìn)行比較,我們忽略了 FP64 和 FP32 精度,充分意識到有時更高的精度計算用于人工智能模型,當(dāng)然也用于 HPC 模擬。這些性能評級適用于密集數(shù)學(xué),而不是稀疏矩陣,這可以使設(shè)備的有效數(shù)值吞吐量翻倍。
我們決定,90 天的租賃代表了訓(xùn)練一個相當(dāng)大的模型需要什么,但沒什么瘋狂的。這種實例成本的規(guī)模產(chǎn)生了一個很好的紅利,其中除數(shù)將它切成太浮點運算的性能。
很多東西都跳出這個怪物表,但我們看到的第一個,我們用粗體強調(diào)的是,AWS 對基于美國西北加州地區(qū)提供的 Hopper H100 和 H200 GPU 的 GPU 實例收取 25% 的溢價。在硅谷很難獲得電力和數(shù)據(jù)中心空間,這就是為什么你看到美國西部地區(qū)的俄勒岡州地區(qū)安裝了這么多新設(shè)備。美國東部地區(qū)錨定在弗吉尼亞州阿什本周圍,它仍然首先獲得許多好東西,包括基于 GB200 NVL72 設(shè)計的 UltraServer P6e 機架系統(tǒng)。正如你所看到的,俄亥俄州的美國東部地區(qū)也獲得了新東西的份額,包括 Trainium1 和 Trainium2 集群。
我們認(rèn)為 FP16 性能是人工智能加速器的基線,然后 FP8 和 FP4 精度是模型的重要進(jìn)一步加速器,這些模型可以使用較低分辨率的數(shù)據(jù)進(jìn)行訓(xùn)練,并且仍然不會犧牲模型的準(zhǔn)確性。
如果你看一下機架式 GB200 NVL72 系統(tǒng)的 FP16 性能與 HGX-B200 系統(tǒng)相比,后者的擴(kuò)展幅度沒有那么大,機架式機——需要液體冷卻,安裝有點像野獸——與 AWS 租用的方式相比,單位性能僅提高了 17%。這其實并不是什么溢價,考慮到系統(tǒng)的密度以及 GB200 NVL72 的密度導(dǎo)致的電源和冷卻問題,這符合您的預(yù)期。
您將看到的另一件事是,H100 和 H200 設(shè)備具有相同的峰值理論性能,但 AWS 安裝的 H100 是較早的,只有 80 GB 的 HBM3 容量,而 H200 具有 141 GB 的 HBM3 容量。AWS 正在為該內(nèi)存和附帶的更高帶寬收取 10% 的溢價。帶有 80 GB HBM3 的 H100 帶寬為 3.35 TB/秒,而帶有 141 GB HBM3E 的 H200 提供 4.8 TB/秒的帶寬。對于許多工作負(fù)載,這種額外的內(nèi)存容量和帶寬幾乎可以使人工智能培訓(xùn)的實際性能增加一倍。您可能期望 AWS 對 H200 實例收取比它更多的溢價。
EC2 容量塊仍然可以使用 Ampere A100 GPU 加速器獲得,有趣的是,按 GPU 計算,H200 比 A100 貴 3.07 倍,但它每個 GPU 的 FP16 性能高 3.17 倍。當(dāng)你計算時,通過容量塊租用具有 40GB HBM2 內(nèi)存的 A100 90 天,每兆浮點運算的成本為 10.21 美元,而 H100 的每兆浮點運算成本為 9.88 美元。只有當(dāng)你無法獲得 H100s、H200s 或 B200s 時,你才會這樣做。帶有 80GB HBM2 內(nèi)存的 A100 每 TBflops 售價為 12.78 美元。(所有這些價格都適用于北加州以外的地區(qū)。)
在 FP16 精度下,P6e 實例中的全尺寸 NVL72 機器,配有 72 個 Blackwell B200 GPU,以及帶有 36 個 Blackwell B200 的半機架,每兆浮點運算成本為 9.14 美元,租金為 90 天,這三個月將分別花費 165 萬美元和 822,856 美元。具有較小內(nèi)存域的 P6-B200 實例在 FP16 精度下,在 90 天內(nèi)每兆浮點運算花費 7.81 美元,鑒于這些實例是空氣冷卻的,內(nèi)存域較小,這是有道理的。神奇的是,液冷 GB200 NVL72 機器的價格并不高。
如果你看一下 FP8 的性能,每太浮點運算的所有成本都減半了,而 Blackwells,以 FP4 格式計算的能力將一億浮點運算的成本再次減半。最終結(jié)果是,如果您更改模型以利用 FP4 性能,您可以租用四分之一的機器以四分之一的成本完成相同的工作,或者您可以花費相同的錢來訓(xùn)練一個大四倍的模型。
現(xiàn)在看看桌子的底部和 Trainium。在原始 FP16 吞吐量方面,需要兩倍于 AWS 設(shè)計的 Trainium1 人工智能加速器才能擊敗 Nvidia A100 約 22%。使用 Trainium2,F(xiàn)P16 的性能提高了 3.5 倍,F(xiàn)P8 的性能提高了 6.8 倍,而 HBM 容量提高了 3 倍,但在 FP16 分辨率下,每兆浮點運算的成本僅提高了 7.4%。增加 FP8 將 FP8 精度的太浮點運算的價格降低到僅 3.72 美元,這低于 AWS 租用的 HGX-B200 節(jié)點作為 P6 實例的每兆浮點運算 3.91 美元,甚至低于 AWS 為 GB200 NVL72 實例收取的每兆浮點運算 4.57 美元。Trainium2 不支持 FP4,這意味著在原始成本方面,Nvidia 對那些可以以 FP4 分辨率運行且不會失去準(zhǔn)確性的人工智能應(yīng)用程序具有優(yōu)勢。
現(xiàn)在,如果您查看 AWS 上的按需定價,Trainium1 芯片仍然可用,而且它們比按需租用的 Blackwell B200 實例要貴得多。看一看:
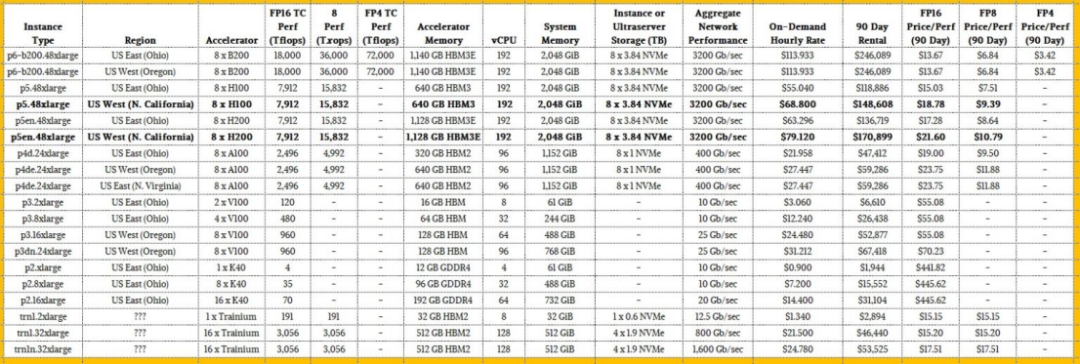
本表中顯而易見的是,基于 K40、V100 和 A100 GPU 的古代加速器實例成本非常低,因此資本支出非常低,這看起來很有吸引力,但如果你看一下 FP16 ooph 的太浮點運算成本,這些在經(jīng)濟(jì)意義上是可怕的,并且與 EC2 容量塊計劃下出售的新鐵的差距要大得多。如果您將這些在 FP16 模式下運行的古老 GPU 與在 FP4 模式下運行的 Blackwells 進(jìn)行比較,除了在絕對緊急情況下,否則考慮使用這種舊的熨斗是徹頭徹尾的愚蠢。
顯然,如果您需要按需租用實例,請租用 Blackwells 并在 FP4 模式下運行。如果你這樣做,F(xiàn)P16 性能的成本會降低 9%,通過精密兩檔的降檔,你可以將性能提高 4 倍,將性價比提高 4.4 倍。
摩爾定律只有在縮小精度的幌子下才真正存在,而不是在縮小晶體管的幌子上。FP2 有人嗎?正如一些人所說,F(xiàn)P1 中沒有意義。










評論