DeepSeek本地部署體驗 比想象中有趣

DeepSeek興起以后,本地部署AI大模型逐漸走進了大眾視野,對比云端版本,本地部署的優勢很明顯,不需要聯網,告別遇到“服務器繁忙,請稍后再試”這種問題,而且數據庫存在本地,同時具有隱私性,保護數據安全。
本文引用地址:http://www.104case.com/article/202503/468546.htm因為DeepSeek顯著降低了部署成本,使得不少消費級電腦都能輕松玩轉,變成超級私人AI助理。不過畢竟需要依靠自身硬件來跑AI大模型,雖然成本降低了不少, 但也不是沒有門檻,只不過相對較低一些。
目前DeepSeek開源特性,開發者跑出了五花八門的模型,專業名詞叫蒸餾模型,這些蒸餾模型有些專門為低配電腦訓練,讓入門級硬件也能跑本地部署AI大模型,不過在運行的精度方面肯定沒有那些高配滿血版高了,可以說將一分錢一分貨的理論發揮的淋漓盡致。
目前DeepSeek R1完整版模型為671B,此外它還有70B、c、14B、8B、7B、1.5B六個原始蒸餾模型,而六個原始蒸餾還被個人開發者訓練除了各種量化版本,以滿足不同平臺、行業用戶的需求。
1.5B是原始最小的模型,搭載一般4G顯存和8GB內存的顯卡游戲本就能跑。而使用單張顯卡不考慮魔改和多卡的話,一般消費級電腦的頂點在32B、70B的蒸餾模型,需要20GB以上顯卡搭配64GB以上內存。其實從數字也能看出來高配版和低配版蒸餾模型的差異,1.5B和32B、70B不在一個量級。
我們這次來玩一玩DeepSeek本地部署,給大家出一套簡易版本部署教程,首先準備了一套電腦平臺,配置如下:

這次我們使用了了AMD 銳龍9 9950X3D這款最新發布的處理器,兼具游戲以及生產力,目前在這雙端都做到了業界領先。
為了能讓這款處理器可以跑滿性能,我們搭配技嘉X870 A ELITE WE7 ICE主板,這是一款純白主板,擁有16+2+2相供電模組,配備全覆蓋式散熱裝甲,足夠AMD 銳龍9 9950X3D發揮出全部實力。
同時這款主板拓展能力不俗,不僅提供PCIe 5.0顯卡插槽以及M.2插槽,還在I/O區域板載12個USB接口,包括兩個最新的USB 4接口。目前這款轉還提供4年質保以及1年換新服務,售后無憂。
顯卡為AORUS GeForce RTX 5090 D MASTER ICE 32G,這款顯卡采用GB202核心,使用與上一代相同的TSMC 4nm定制工藝(TSMC 4nm 4N NVIDIA CustomProcess),芯片面積750mm2。擁有21760個CUDA,Boost頻率為2655MHz。 采用32GB GDDR7顯存,位寬為512bit,顯存帶寬達到了1792 GB/s,光柵單元和紋理單元為176和680。
顯示器為技嘉FO32U2P OLED顯示器,這是一款4K頂級桌面顯示器,采用QD-OLED面板,擁有240Hz刷新率以及0.03ms響應時間,還經過ClearMR 13000認證以及HDR400認證,提供了更加真實的畫面表現。
在部署之前,我們首先要確定使用的容器,也就是啟動器,玩過Stable Diffusion對此應該不會陌生,大名鼎鼎的秋葉啟動器就是一種容器。目前很多支持DeepSeek的容器,根據自己的需求搜索容器官網去下載即可,我們這次先使用的是LM Studio。
LM Studio對于新手還是非常友好的,界面簡潔干凈,邏輯清晰,我們安裝打開點擊下方齒輪設置,可以調節成簡體中文,不過目前中文僅限于一些基礎界面和功能調節。
來到正式界面,與大家網頁端看到的樣式其實差不多,頂部是加載模型的地方,我們下載了一個32B版本的模型,加載后直接對話即可。
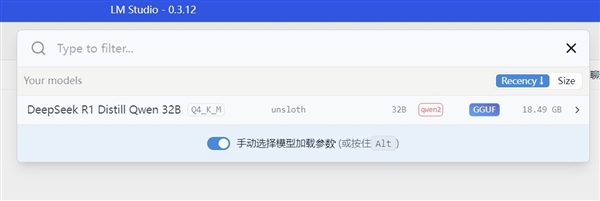
加載模型時能設置一些細節,比如字數、CPU步進之類的,底部種子玩過Stable Diffusion都知道是什么,用來跑出和其他人接近的生成結果。
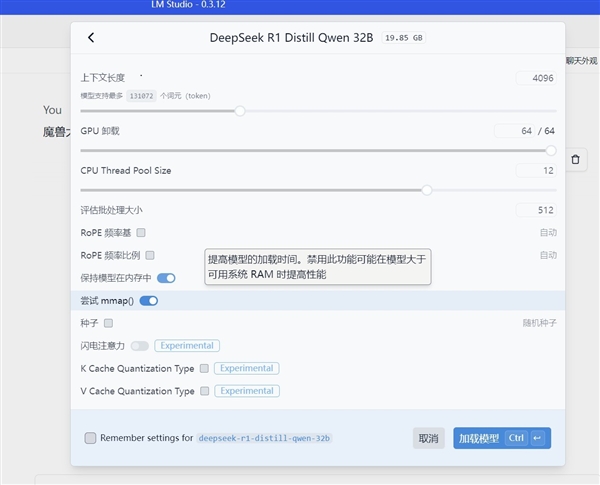
左側放大鏡圖標里是LM Studio的模型庫,里面提供一些蒸餾后的DeepSeek R1,可以看到很多版本,有27B、12B、4B等訓練好的模型,可以根據需求下載,模型越高級需求的容量也就越大,比如我們使用的32B版本就需要18個GB以上。
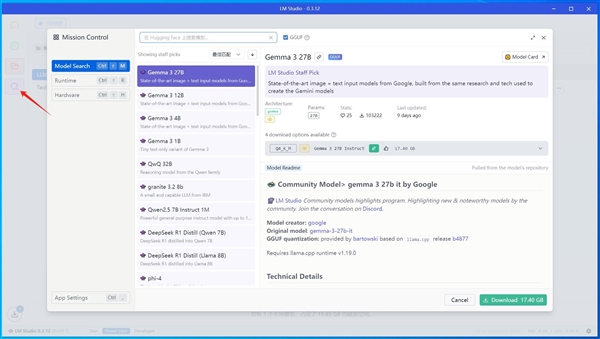
如果不使用LM Studio里面的模型而是下載了獨立的模型也沒問題,找到左側圖表中的文件見慘淡,頂部會給出模型目錄,將模型拷貝進去即可,就可以在第一步的加載模型頂部欄中找到它去使用。
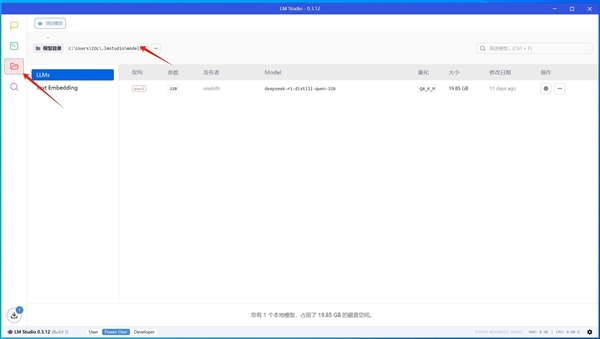
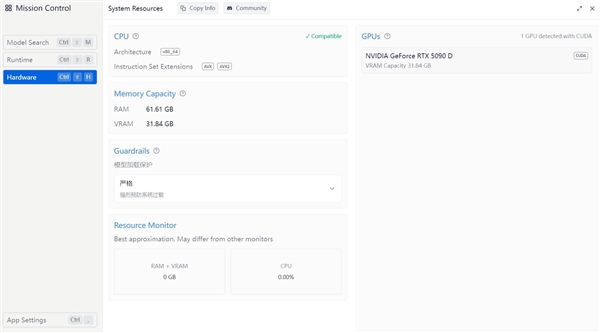
我們這里使用了這個32B模型進行了對話,響應速度極快,整個對話內容生成不到幾秒鐘。這得益于整個平臺性能確實很強大,在跑這個模型時,顯存使用了21.5GB左右,內存利用了9GB左右。
對于這種大語言模型,顯存和內存的容量很關鍵,這套技嘉平臺,AORUS GeForce RTX 5090 D MASTER ICE 32G有32GB大顯存,內存容量高達64GB,沒有達到上限,就可以讓這寫硬件本身性能發揮出來,所以很輕松就能讓本地32B模型快速響應。
注意如果你的模型太過高級,需求量超出你的顯存和內存容量,記得不要強行跑,因為生成的速度會很慢,1分鐘可能都生成不了幾個字,比如降低一下蒸餾版本,選擇合適自己的模型。
AMD 銳龍9 9950X3D占用率也只有10%,這樣在生成時閑暇之余也可以做些別的日常,比如看視頻,玩一玩顯存足夠的游戲。
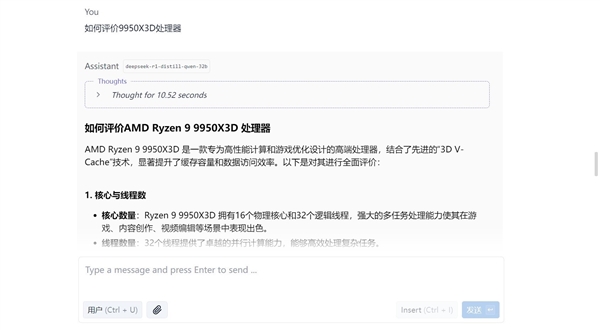
不過本地模型也有局限性,那就是信息取決于模型,如果你的模型數據庫里沒有包含相應的信息,它就不會給你想要的答案。比如我們這個模型模型庫的時間在2024年,所以我下面問的這個關于AMD 銳龍9 9950X3D的問題它就沒有準確回應,而是用錯誤數據填充了答案。因此在涉及數據相關的內容時,還是需要謹慎一些,AI目前畢竟只是輔助工具。

總結來看,DeepSeek確實降低了AI大語言類本地部署的門檻,目前消費級電腦是可以去盡心體驗的,相較于云端響應速度更快,只服務于你一人,也能針對性下載相應的模型來滿足自身定制需求。缺點則是依舊有一定門檻,并且吐過不常更新模型數據庫信息的話,不能實時解答熱點問題,整體操作也確實沒有云端簡單,畢竟現在很多人連壓縮包都解不明白,那確實不太好上手。
對于硬件而言,我們這套技嘉X870 A ELITE WE7 ICE主板+AMD 銳龍9 9950X3D+AORUS GeForce RTX 5090 D MASTER ICE 32G+64GB的組合玩轉DeepSeek是沒有任何壓力的,消費級這樣的平臺也基本都到頭了,頂多可能將內存升到128GB,那就有可能挑戰更大規模的模型,總體而言頂級消費級平臺體驗本地部署會非常舒服,建議有能力的用戶去嘗試一下。





評論