AI“大躍進”,芯片還夠嗎?

在ChatGPT帶來的AI熱潮中,繼百度之后,360、華為、騰訊、阿里甚至是科大訊飛、商湯、創維等企業均表示將推出自己的大語言模型。
本文引用地址:http://www.104case.com/article/202304/445808.htm盡管ChatGPT及一眾主流大模型背后的芯片主力仍是GPU,但嚴峻的挑戰已經擺到眼前:生成式AI所需計算量不斷增加,而算力增長空間卻即將觸頂。
4月5日,OpenAI暫停ChatGPT Plus的注冊,隨后又重新恢復,其中原因是算力需求量超載。此前,ChatGPT還因訪問量過大而大規模封號,并禁止使用亞洲節點登錄,主要還是算力不足造成的。
盡管OpenAI踩下“剎車”,但大洋彼岸的A股算力概念股依舊掀起巨浪,一時間炙手可熱。業內稱,如今AI的“iPhone時刻”已經來臨,作為人工智能時代的底層基座,誰掌握了算力資源,誰就擁有了引領數字經濟發展的“終極武器”。在這個歷史性的變革時刻,中國不能缺席。
AI模型開啟算力軍備競賽
作為人工智能三大核心要素(數據、算法、算力)之一,算力被譽為人工智能“發動機”。在AI風暴的催化下,浪潮中的AI大算力芯片公司面臨著摩爾定律瀕臨極限之外的技術挑戰:以更低的系統成本、更少的能源消耗,支撐起龐大且持續增加的參數量所帶動的高算力需求。
根據OpenAI測算,自2012年以來全球頭部AI模型訓練算力需求每3-4個月翻一番,每年頭部訓練模型所需算力增幅高達10倍。AI深度學習正在逼近現有芯片的算力極限,也對芯片設計廠商提出了更高要求。
在技術架構層面,AI芯片可分為GPU(圖形處理器)、ASIC(專業集成電路)、FPGA(現場可編程門陣列)和類腦芯片。隨著現象級AI產品ChatGPT的走紅,以大型語言模型為代表的前沿AI技術走向聚光燈之下,這類模型所需的數據量、計算量龐大,成本高昂。
例如,目前采購一片英偉達頂級GPU成本為8萬元,GPU服務器成本超過40萬元。對于ChatGPT而言,支撐其算力基礎設施至少需要上萬顆英偉達GPU A100,一次模型訓練成本超過1200萬美元。
根據浙商證券研報,ChatGPT背后的算力支撐主要來自GPU或CPU+FPGA。由于具備并行計算能力,可兼容訓練和推理,GPU目前被廣泛應用。
除了GPU以外,CPU+FPGA的方案也能夠滿足AI龐大的算力需求。FPGA全稱為現場可編程門陣列,是一種可以重構電路的芯片。作為可編程芯片,FPGA芯片可以針對特定功能進行擴展。通過與CPU結合,FPGA能夠實現深度學習功能,兩者共同應用于深度學習模型。
近期,英特爾透露,計劃將在今年推出15款新FPGA,這將刷新英特爾該品類的年度推新紀錄。其實在3月初,英特爾就發布了Agilex7 FPGA F-Tile,并配備FPGA收發器,其每個通道的帶寬都較上一代提升了一倍,在給產品提供更高的數據流量的同時也降低了功耗。
目前,FPGA領域的本土化程度較低。中國市場主要由賽靈思Xilinx(現已被AMD收購)和英特爾兩大廠商主導,占據了超過70%的市場份額。國內廠商安路科技、紫光國微、復旦微電等總份額約為15%。
寒武紀作為科創板AI芯片第一股,是全球少數全面掌握AI芯片技術的企業之一。其產品矩陣涉及云端產品、邊緣產品和IP授權及軟件,前兩者對標英偉達、AMD,IP授權則對應英國的ARM。云端芯片就是目前大語言模型最為需要的動能來源,在該領域,英偉達A100、H100系列占據金字塔頂尖位置。
作為追趕者,寒武紀推出了思元系列,思元290、思元370等已經進入浪潮、聯想、阿里云等多家頭部客戶。去年3月,寒武紀正式發布新款訓練加速卡“MLU370-X8”,其搭載了思元370,主要面向AI訓練任務。
差距懸殊,彎道難以超車
作為當前唯一可以實際處理ChatGPT的GPU供應商,英偉達是當之無愧的“AI算力王者”。
6年前,黃仁勛親自向OpenAI交付了第一臺搭載A100芯片的超級計算機,幫助后者創造ChatGPT,并成為AI時代的引領者。
在2023年3月22日召開的GTC大會上,黃仁勛又展示了速度比現有技術快10倍的英偉達HGX A100,可將大語言模型的處理成本降低一個數量級。
目前,英偉達市值飆升到6678億美元(約合4.6萬億人民幣),幾乎是傳統芯片巨頭英特爾市值的五倍,成為全球最大市值的芯片企業。英偉達在PC的GPU市場上占據了近70%的份額,在獨顯市場的份額更是高達70%-80%。
據TrendForce分析,運行1800億參數的GPT-3.5大型模型需要2萬顆GPU芯片,大模型商業化的GPT則需要超過3萬顆。
然而,根據相關報道,國內目前擁有超1萬顆GPU的企業不超過5家,擁有1萬顆英偉達A100芯片的可能最多只有一家,絕大部分中國公司都只能采購英偉達的中低端性能產品。
即使國內頭部公司,從算力上跟美國的英偉達等公司相比,差距也非常明顯。
就GPU細分賽道而言,國內自研GPU的領軍企業主要包括景嘉微、壁仞科技、芯動科技等。其中,其中,景嘉微是成立最早的一家,自2006年開始研發擁有自主知識產權的GPU產品,現在已經推出了一系列產品線,且均采用國內成熟制程工藝和自主架構。
景嘉微的主打產品是JH920獨立顯卡。根據行業專家的評測,從性能參數上來看,JH920的性能與英偉達2016年發布的GTX 1050相當,雖然兩者僅相差6年,但由于GTX 1050是英偉達10系列顯卡中的入門級產品,無法代表當時的整體水平。
要想找到與GTX 1050性能相當的英偉達產品,需要回溯到2010年推出的GTX 580,這意味著景嘉微JH920基本上達到了英偉達12年前的水平。
所以整體而言國產GPU的現狀并不算樂觀,雖然在特殊領域能夠自給自足,但在中高端領域依舊捉襟見肘。
與此同時,中美地緣關系的博弈氣息日漸濃厚,這給高度依賴先進制程的AI芯片創業公司提出了技術之外的新難題。
去年,在美國總統拜登正式簽署芯片法案(《CHIPS and Science Act》)一個月之后,美國政府對華實施了高端GPU芯片的出口禁令。同時,國內GPU設計商壁仞科技的GPU芯片BR100在臺積電的試產也被迫叫停并主動修改設計,以滿足出口禁令的要求。
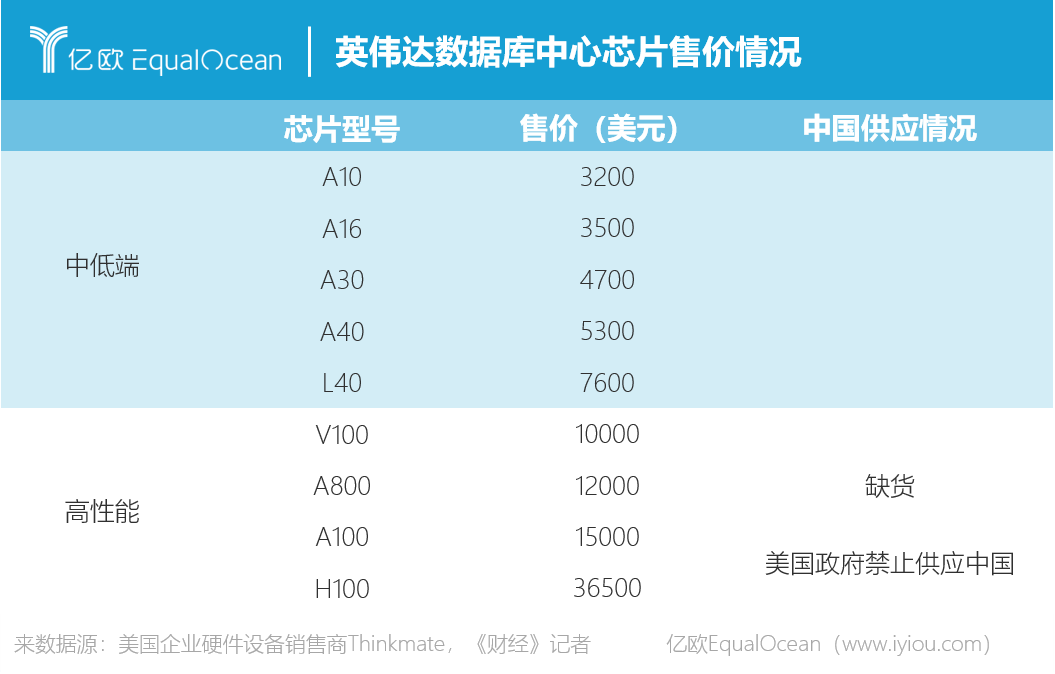
A100和H100被禁止后,中國企業只能奢望其替代品A800和H800。2022年11月7日,英偉達向中國的供應商提供其重新封裝的A800芯片。據稱,國內幾家頭部互聯網企業都向英偉達下了1.5萬左右的A800和H800訂單。但即使是最佳替代品A800,也只是A100的“閹割版”,其傳輸速度和運算性能較A100下降了50%。
被美國等國聯合封堵的我們,或許在較長時間內都無法制造出比肩英偉達等國際頂級公司的高水準AI芯片。面對一個新的時代,我們又該如何破局?
換道行駛,續命摩爾定律
一直以來,頭部廠商通過不斷提升制程工藝和擴大芯片面積推出算力更高的芯片產品。雖然GPU、CPU+FPGA等芯片已經對現有模型構成底層算力支撐,在應對生成式AI及大模型對算力基礎設施提出的新要求,都多少顯得有些捉襟見肘。
伴隨著摩爾定律逼近物理極限,制程升級和芯片面積擴大帶來的收益邊際遞減,架構創新或成為提升芯片算力另辟蹊徑的選擇。
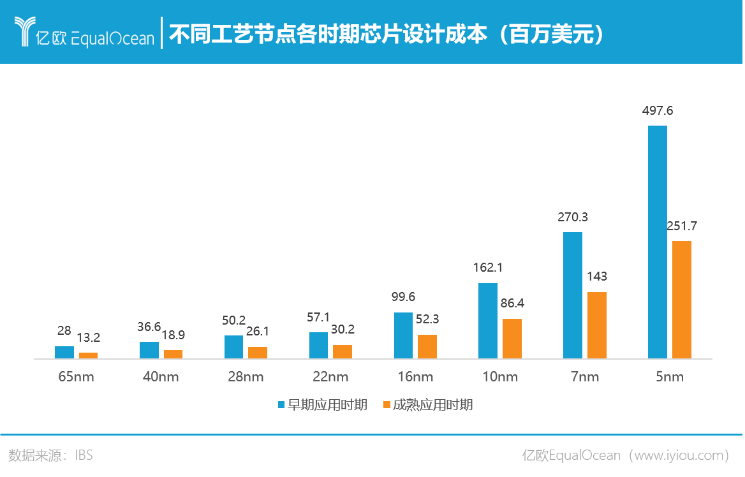
Chiplet及先進封裝方案能夠彌補先進制程落后的劣勢,通過將來自不同生產廠商、不同制程工藝的芯片組件“混搭”,降低實現目標性能所需的成本。研究數據顯示,當5nm芯片的面積達到200㎜2以上,采用5Chiplet方案成本將低于單顆SoC,并將大幅降低因面積增加帶來的良率損失。
除了成本和良率端的優勢,Chiplet技術帶來高速的Die to Die互連,使多顆計算芯粒得以集成在一顆芯片中,實現算力的大幅提升。
臺積電是Chiplet工藝的領軍者,目前其技術平臺下有CoWoS、InFO、SoIC三種封裝工藝。其中,早在2016年英偉達Tesla P100 AI數據中心GPU就已經應用CoWoS工藝,AMD的最新GPU、CPU也廣泛采用了該工藝。此外,三星、Intel等龍頭廠商亦推出了各自用于Chiplet的封裝技術,如三星I-Cube(2.5D封裝),X-Cube(3D封裝),英特爾EMIB(2.5D封裝),英特爾Foveros(3D封裝)。
不止在國際,近幾年Chiplet在中國大陸也非常火爆,特別是美國開始打壓中國半導體業以來。Chiplet既能減少先進制程用量,同時又能帶來先進制程的好處,這為國內芯片企業提供“換道行駛”的機會。
目前國內封測巨頭相關技術積累已初顯成效。例如長電科技的XDFOI Chiplet高密度多維異構集成系列工藝已進入穩定量產階段;通富微電與AMD密切合作,已大規模生產7nm Chiplet產品;華天科技的Chiplet系列工藝也實現量產。
Chiplet設計主要用于大型CPU和GPU等處理器。雖然當下國產CPU特別是大芯片與國際大廠存在明顯差距,但華為海思、寒武紀科技等少數企業正重點研發并采用7nm及更先進制程的服務器芯片和AI芯片。
在GPU方面,英偉達等國際GPU龍頭企業已經構建了牢固的專利墻。無論是老牌企業如景嘉微和海光,還是新興創業公司,如芯動科技、壁仞科技、摩爾線程、沐曦集成電路、天數智芯等,大多還處于發展初期,且所設計的芯片規模有限,采用Chiplet設計的還不多。
不過,一些GPU企業,特別是創業公司,雖然短期內難以在大芯片領域形成規模,但長期發展前景仍值得期待。例如,近幾年天數智芯在云端GPGPU方面異軍突起,其推出的7nm制程云端訓練和推理GPGPU,能夠為云端AI訓練和HPC通用計算提供高算力和高能效比。類似這樣的芯片成為中國本土Chiplet技術發展的希望。
近期,中國成立了自己的Chiplet聯盟,由多家芯片設計、IP、以及封裝、測試和組裝服務公司組成,并推出相應的互連接口標準ACC 1.0。這一聯盟的成立,頗有與由AMD、Arm、英特爾、臺積電等主導的UCIe聯盟分庭抗禮的意味,也反映出中國相關企事業單位要從底層做起,發展本土Chiplet的愿望。
通過標準的設立,可以將自己生產的芯片變成Chiplet企業使用的“標準產品”,被不斷地集成到各種終端應用中,從而為芯片行業開辟出一片新天地。
結尾
算力的每一次提升,都掀起技術與產業變革的浪潮:CPU帶領人類進入PC時代,移動芯片掀起移動互聯網浪潮,而AI芯片打破了AI產業此前長達數十年的算力瓶頸。如今,“人工智能的iPhone時刻”已經來臨,走向下一個時代的路,或許早已擺在我們眼前。
正如阿里巴巴集團董事會主席張勇所言,面向AI時代,所有產品都值得用大模型重新升級。過去一年消費電子的低迷使得一些GPU公司的產品找不到應用場景。但隨著ChatGPT出現,相關芯片的應用場景開始增加,并發展成AI基礎研究和產業化落地的一大趨勢。
AI往前發展,超高算力需求毋庸置疑AI大算力芯片技術提供了一種可行的解決方案。未來幾年,中美兩國將成為大模型的主要誕生地,并不計成本地帶動對算力芯片的需求。不管是彎道超車還是換道行駛,在這場AI的征途中,中國算力企業萬象競逐的畫卷才剛剛展開。






評論