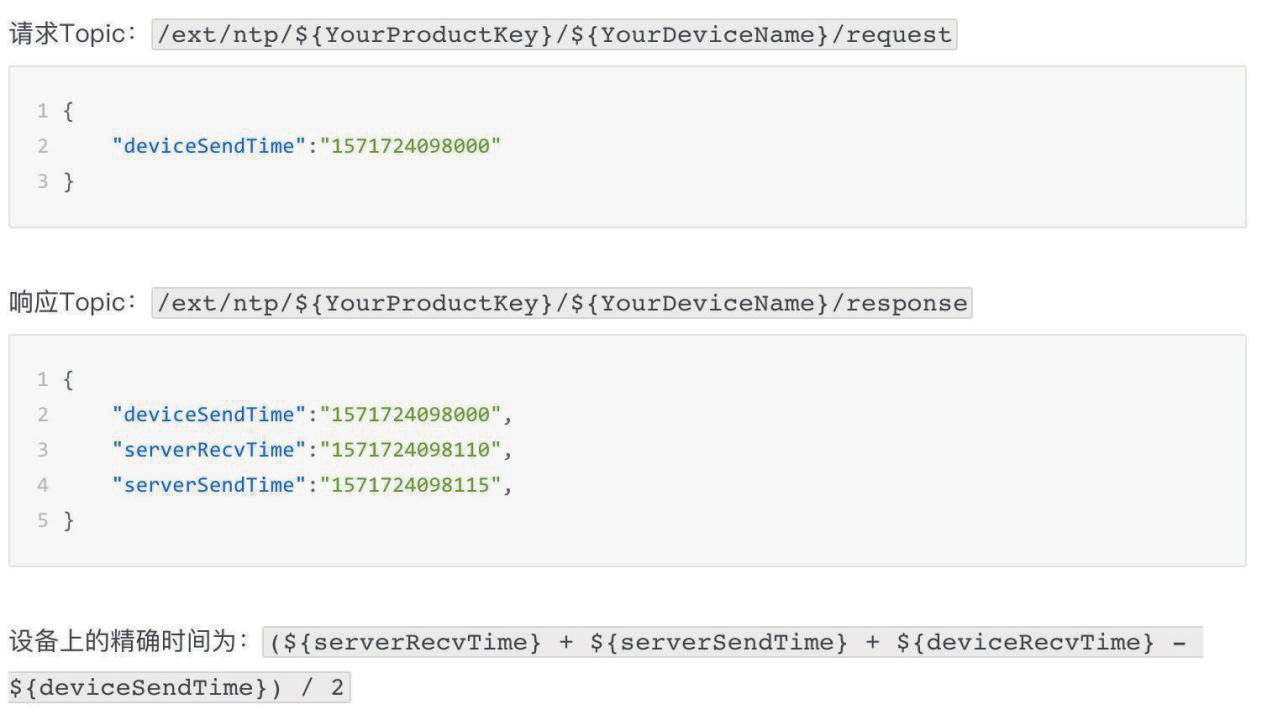
一種改進的YOLOv4-tiny車輛目標檢測方法*
 加入技術交流群
加入技術交流群

掃碼加入
和技術大咖面對面交流
海量資料庫查詢
*基金項目:湖南省省市聯合基金(2019JJ60060),多功能機組絕緣故障診斷關鍵技術研究
本文引用地址:http://www.104case.com/article/202109/428434.htm作者簡介:趙家琪(1996—),男,河南,碩士研究生,主要研究方向為機器學習、深度學習、計算機視覺。E-mail:1262085026@qq.com。
高貴(1981—),男,湖南,西南交通大學地球科學與環(huán)境工程學院教授,博士生導師,國家優(yōu)秀青年科學基金獲得者,主要研究方向為攝影測量與遙感、雷達信號處理等。
摘要:伴隨深度學習的不斷發(fā)展,深度學習的目標檢測方法被廣泛應用。基于特征融合的思想,本文提出了一種改進的YOLOv4-tiny目標檢測方法,通過添加卷積模塊及調整部分超參數對其網絡架構進行優(yōu)化,以實現對道路車輛目標的快速檢測、識別和定位。首先為了改善YOLOv4-tiny網絡對小目標類型檢測精度差的問題,基于特征金字塔網絡對第二標度輸出層的最后一個CBL輸出特征與網絡中第二個CSP輸出特征進行融合,并在原有網絡的基礎上增加52×52的標度輸出;其次,利用遷移學習權重在自己采集的數據集上進行實驗,訓練得出合適的權重進行測試。實驗結果表明,與YOLOv4-tiny相比,改進后的網絡結構相對YOLOv4-tiny的AP提升4.4%、召回率(Recall)提升4.6%、準確率(Precision)提升8.4%,且可以準確檢測并定位車輛的位置。
0 引言
伴隨近幾年人工智能的快速發(fā)展,以及深度學習技術的不斷突破創(chuàng)新,智能交通系統已經成為社會的發(fā)展趨勢。國家要實現交通系統的智能化和自動化運行,就要將大量的交通信息利用計算機視覺技術進行處理,例如車牌識別、車輛識別與流量統計、無人駕駛等[1]。目前,深度學習技術被廣泛運用到目標檢測領域。為了提高駕駛的便捷性和安全性,自動駕駛技術被廣泛重視并推向了商業(yè)化,高級駕駛輔助系統(ADAS)得到了廣泛的應用,ADAS 可以實現道路檢測與車輛目標檢測等多種功能。因此,高效準確的車輛目標檢測技術對智慧交通系統的發(fā)展起到了至關重要的作用。目前,基于計算機視覺的目標檢測算法分為傳統的目標檢測算法和基于深度學習的目標檢測算法[2]。傳統的目標檢測算法是基于機器學習的分類器與人工提取的局部特征相結合的算法,主要包括提取特征和分類兩個方面,提取的特征通常是梯度方向直方圖或類harr 特征,結合支持向量機或AdaBoost 進行目標檢測。使用傳統的基于機器學習的方法提取特征需要人為設計特征,容易損失信息從而造成誤差,不能滿足高精度和高檢測速度的場景。與傳統的目標檢測算法相比,基于深度學習的目標檢測算法具有更高的準確率、更快的檢測速度和更強的魯棒性。因此,越來越多的深度學習方法被不斷應用到目標檢測領域[3-6]。基于深度學習的目標檢測方法包括兩階段(Two stage)目標檢測算法[7] 和單階段(One stage)目標檢測算法[8],兩階段算法是對圖像生成可能包含目標的候選區(qū)域(region)用卷積神經網絡(CNN)對候選區(qū)域進行分類,精度很高,但速度方面欠佳。兩階段目標檢測算法包括R-CNN、Fast R-CN、Faster R-CNN、基于區(qū)域的全卷積網絡(R-FCN) 等,雖然兩階段法比一階段法具有更高的精度,但一階段法比兩階段法具有更快的檢測速度[9-10]。單階段檢測算法目標檢測以整張圖作為輸入,在特征層輸出邊框位置和所屬的類別,從而轉變?yōu)橐粋€回歸問題。YOLO(The You Only Look Once)[11]算法是Redmon 等人提出的第一個基于回歸的單階段算法,之后Redmon 等人又提出了基于YOLO 算法的YOLOv2算法 [12],刪除了完全連通層和最后一個匯集層,使用錨點框來預測邊界框,并設計出DarkNet-19 的新基礎網絡。YOLOv3[13] 是Redmon 等人提出的YOLO 方法的最后一個版本。它引入了特征金字塔網絡、更好的基本網絡darknet-53 和二進制交叉熵損失,以提高檢測精度和檢測較小目標的能力。由于YOLOv3 采用的信息融合類型沒有充分利用低級信息,這是限制其在工業(yè)中潛在應用的一個弱點。因此,Alexey 等人提出了YOLOv4 算法,它使用CSPDarknet53 主干、空間金字塔池模塊、PANet 路徑聚合頸和YOLOv3( 基于錨點) 頭作為YOLOv4 的架構。以上基于深度學習的目標檢測算法在目標檢測領域雖然取得一定效果,但其在智能交通領域針對小目標的檢測仍然不夠精準。本文通過對道路車輛目標圖像進行分析,結合最新的YOLOv4-tiny 算法并對其模型進行合理優(yōu)化,實現了對道路圖像車輛目標的快速準確檢測。
1 YOLOv4-tiny方法改進
1.1 YOLOv4-tiny模型
Yolov4-tiny[14](You Only Look Once vision4-tiny) 算法是在Yolov4 算法的基礎上設計的,使其具有更快的目標檢測速度,使用1080Ti GPU, Yolov4-tiny 的目標檢測速度可達到371 幀/s,精度可以滿足實際應用的要求。Yolov4-tiny 算法使用CSP Darknet53-tiny 網絡作為骨干網絡來代替Yolov4 算法中使用的CSPDarknet53網絡,空間金字塔池(SPP) 和路徑聚合網絡(PANet) 也由特征金字塔網絡(FPN) 代替,以減少檢測時間。此外,它還使用了兩個尺度的預測(26×26 和13×13),而不是3 個尺度的預測。CSPDarknet53-tiny 網絡在跨級部分網絡中使用了CSPBlock 模塊,在剩余網絡中使用了ResBlock 模塊。CSPBlock 模塊將特征映射分成兩部分,通過跨階段殘差邊緣將兩部分進行組合,這使得梯度流可以在兩種不同的網絡路徑上傳播,增加梯度信息的相關性差異。與ResBlock 模塊相比,CSPBlock 模塊不僅可以提高卷積網絡的學習能力、計算精度,而且還可以減少計算量。消除了ResBlock 模塊中計算量較大的計算瓶頸,提高了Yolov4-tiny 方法在常數情況下的精度,減少了計算量。為了進一步簡化計算過程,Yolov4-tiny 方法在CSPDarknet53-tiny 網絡中使用Leaky ReLU 函數作為激活函數,而不使用Yolov4 中使用的Mish 激活函數。在特征融合部分,Yolov4-tiny 方法使用特征金字塔網絡提取不同尺度的特征地圖,提高了目標檢測速度,而不使用Yolov4 方法中使用的空間金字塔池化和路徑聚合網絡。與此同時,Yolov4-tiny 使用了13×13和26×26 這兩種不同尺度的特征地圖來預測檢測結果。假設輸入圖的大小為416×416,特征分類為80,Yolov4-tiny 網絡結構如圖1 所示。Yolov4-tiny 方法的預測過程與Yolov4 方法相同。首先調整輸入圖像的大小,使所有輸入圖像具有相同的固定大小;其次將輸入圖像劃分為大小為S×S 的網格,每個網格使用B 個邊界框檢測目標,因此輸入圖像會生成S×S×B 的邊界框,生成的邊界框覆蓋了整個輸入圖像。如果某個對象的中心落在某個網格中,網格中的邊界框將預測該對象,為了減少預測過程中邊界框的冗余,提出了置信閾值。如果邊界框的置信值高于置信閾值,則邊界框保持不變;否則邊框將被刪除。包圍盒的置信值可得如下:

其中 代表第i 個網格中第j 個邊界框的置信度,pi, j是目標函數。如果目標在第i個網格的第j個方格中,則pi, j =1,否則pi, j =0。
代表第i 個網格中第j 個邊界框的置信度,pi, j是目標函數。如果目標在第i個網格的第j個方格中,則pi, j =1,否則pi, j =0。 表示預測框與真實框在并集上的交集。可比性得分越大,預測框就越接近地面真相框。Yolov4-tiny 的損耗函數與Yolov4 相同,都是由目標框損失Lcoord 、置信度損失Lcoin 和分類損失Lclass 三部分組成,公式如下所示:
表示預測框與真實框在并集上的交集。可比性得分越大,預測框就越接近地面真相框。Yolov4-tiny 的損耗函數與Yolov4 相同,都是由目標框損失Lcoord 、置信度損失Lcoin 和分類損失Lclass 三部分組成,公式如下所示:
loss=loss1+loss2+loss3
loss1 ,loss2 ,loss3分別代表置信度損失、分類損失、目標框回歸損失。
置信度損失函數:


圖1 YOLOv4-tiny網絡框架
這里S2 是輸入圖像的格子的個數, B 是格子里邊框的個數, 是一個目標函數。如果jth 邊框是ith 格子里檢測的正確目標,
是一個目標函數。如果jth 邊框是ith 格子里檢測的正確目標, 否則
否則 和
和 分別是預測框的置信度分數和真實框的置信度分數,λnoobj是一個權重參數。
分別是預測框的置信度分數和真實框的置信度分數,λnoobj是一個權重參數。
分類損失函數:

這里的 和
和 分別代表預測框和真實框目標屬于c 類目標在jth 邊框中是ith 格子里的概率。
分別代表預測框和真實框目標屬于c 類目標在jth 邊框中是ith 格子里的概率。
位置回歸損失:

其中IOU 是預測框和真實框之間的交集并集, wgt和hgt分別為真實框的寬度和高度,W和h分別為預測框的寬度和高度,ρ 2 (b,bgt )為預測框中心點與真實框中心點之間的歐氏距離,C是能包含預測邊界盒和真值邊界盒的最小對角線距離。
2.2 YOLOv4-tiny改進模型
對于卷積神經網絡,不同深度的卷積層對應不同級別的特征信息。低級網絡具有更高的分辨率和更詳細的特征,而高級網絡具有更低的分辨率和更多的語義特征。為了使更深層次的網絡同時包含豐富的語義特征和圖像表面特征,我們基于特征融合思想改進了YOLOv4-tiny的網絡架構,在原有的框架基礎上增加了52×52 比例的輸出,使分割圖像的像元變小,這有助于提高小尺寸物體檢測的精度。改進的YOLOv4-tiny 網絡架構如圖2 所示。其中實線代表YOLOv4-tiny 網絡架構,虛線代表我們改進后的網絡。
1)增加52×52 的標度輸出
①提取高層語義信息和淺層表面信息
我們提取了距離第二輸出最近的CSPBlock 卷積層的輸出信息,由于在網絡中的深層位置,其包含了豐富的語義信息。此外,提取包含圖像豐富表面信息的淺層CSPBlock 的輸出。
②特征融合
將A 部分提取的兩個輸出送入1×1×128 的CBL,輸出大小為26×26×128,之后是上采樣層,將其大小改為52×52×128。然后將輸出結果送入concat層進行融合,融合后的特征圖大小為52×52×256。這些融合的特征圖被處理成3×3×256 的CBL,用于進一步的信息提取。
③增加一個輸出尺度將B 節(jié)中獲得的融合特征圖通過1×1×255 的Conv層,再增加一個52×52×255 的輸出。在YOLOv4-tiny中, 網絡具有13×13 和26×26 的輸出。在改良的YOLOv4-tiny 中,我們增加了52×52 比例的輸出,使分割圖像的像元變小,這有助于提高小尺寸物體檢測的精度。

圖2 改進的YOLOv4-tiny網絡框架
2)損失函數優(yōu)化
YOLOv4-tiny 優(yōu)化后的損失函數由目標框損失Lcoord 、置信度損失Lcoin 和分類損失Lclass 組成:

式中: L(c,x, y,w,h)為優(yōu)化后的 YOLOv4-tiny 損失函數; N 為匹配到目標區(qū)域的Default Box 的數量; α 為用于調整目標框損失Lcoord 的比例(α初=1 )。目標檢測算法流程如圖3 所示:

2 實驗結果與分析
本次實驗的環(huán)境為: 英特爾酷睿TM i7-8700 CPU@3.20 GHz;Window10 帶有Pytorch1.6.0 和Python3.6;GPU是NVIDIA Geforce GTX 3090,計算機配置如表1 所示。

本文使用的車輛目標數據集是利用攝像裝置在道路上采集得到,并使用圖片標志工具(label Img)對數據集進行標注。通過對圖像中的車輛目標用矩形框標記,標記后的圖片將以XML 文件存儲,作為對應訓練圖片的標簽。數據由訓練集、測試集、驗證集3 部分組成(如圖表2 所示),共使用8 000 張圖片進行訓練,對已標記好的圖像進行整理,以XML 文件作為對應圖片訓練的標簽,存儲了3 個屬性:Label、Pixels、Usage。

2.1 實驗結果展示
在這篇文章中,我們所用的數據集都是自己在道路中采集的,之后對數據集進行標簽處理。該數據集包含6 500 張訓練集和1 200 張驗證集,最后從300 張測試集中隨機抽取2 張圖像分別用YOLOv4-tiny 和改進后的YOLOv4-tiny 模型進行測試,測試效果如圖4 和圖5 所示。從圖4、圖5 可以看出,通過對YOLOv4-tiny 與改進后的YOLOv4-tiny 模型進行檢測效果對比,YOLOv4-tiny沒有將圖像中的小目標檢測出來,改進后的YOLOv4-


圖4 YOLOv4-tiny模型檢測結果


圖5 改進的YOLOv4-tiny模型檢測結果
2.2 實驗對比與評估
文章將提出的方法與YOLOv4、YOLOv4-tiny 進行比較,測試它們在檢測效果精確率P(Precision)、召回率R(Recall)、AP 的性能。其公式可表示為:

其中,FP(False Positive)是真實類別為負,預測類別為正;FN(False Negative)是樣本真實類別為負,預測類別為負;TP(True Positive)是樣本真實類別為正,預測類別為正;TN(True Negative)是真實類別為正,預測類別為負。

3 結束語
為了提高對小目標的檢測效果,文章提出了一種改進的YOLOv4-tiny,將YOLOv4-tiny 提取的高級卷積特征和低級卷積特征進行融合,增加52×52 尺度的輸出,并使用K-means 聚類方法在數據集上生成檢測框架的錨框。通過將數據集在改進前后的網絡上訓練,并進行對比測試。實驗結果表明,改進后的YOLOv4-tiny 與YOLOv4 相比,各項指標表都比較低;改進后的YOLOv4-tiny 與YOLOv4-tiny 相比,準確率(Precision)提高了8.4%,召回率(Recall)提高了4.6%,AP 值提高了4.4%。與YOLOv4-tiny 相比,改進后的YOLOv4-tiny可以較好地檢測出圖像中存在的小目標。
參考文獻:
[1] 徐子睿,劉猛,談雅婷.基于YOLOv4的車輛檢測與流量統計研究[J].現代信息科技,2020,4(15):98-100+103.
[2] 王永平,張紅民,彭闖,等.基于YOLO v3的高壓開關設備異常發(fā)熱點目標檢測方法[J].紅外技術,2020,42(10):983-987.
[3] REDMON J,FARHADI A.YOLOv3:An Incremental Improvement[Z].arXive -prints,2018.
[4] REDMON J,FARHADI A.YOLOv3:An incremental improvement[Z].arXiv preprint,2018.
[5] SIMONYAN K,ZISSERMAN A.Very deep convolutional networks for large scale image recognition[Z].arXiv preprint,2014.
[6] REDMON J,DIVVALA S,GIRSHICK R,et al.You only look once:Unified,real-time object detection[C].In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR),2016:779-788.
[7] ZHANG Y,SONG C,ZHANG D.Deep Learning-Based Object Detection Improvement for Tomato Disease[J].IEEE Access,2020(8):56607-56614.
[8] ALGABRI M,MATHKOUR H,BENCHERIF M A,et al.Towards Deep Object Detection Techniques for Phoneme Recognition[J].IEEE Access,2020(8):54663-54680.
[9] ZHOU L,MIN W, ,LIN D, ,et al. .Detecting Motion Blurred Vehicle Logo in IoV Using Filter-Deblur GAN and VL-YOLO[J]. .IEEE Transactions on Vehicular Technology, 2020, ,69(4)::3604-3614. .
[10] ZHANG H,QIN L,LI J,et al.Real-Time Detection Method for Small Traffic Signs Based on Yolov3[J].IEEE Access,2020(8):64145-64156
[11] REDMON J,DIVVALA S,GIRSHICK R,et al.You Only Look Once:Unified,Real-Time Object Detection[C].In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,Las Vegas,NV,USA,2016:779-788.
[12] REDMON J,FARHADI A.YOLO9000:Better,Faster, Stronger[J].IEEE Trans.Pattern Anal.2017,29:6517–6525.
[13] REDMON J,FARHADI A.YOLOv3:An Incremental Improvement[J].IEEE Trans.Pattern Anal.2018,15:1125–1131.
[14] HOU X,MA J,ZANG S.Airborne infrared aircraft t a r g e t d e t e c t i o n a l g o r i t h m b a s e d o n Y O L O v 4 -tiny[J].2021 International Conference on Advances i n Opticsand Computational Sciences (ICAOCS) 2021,Ottawa,Canada,IOP Publishing Ltd.
(本文來源于《電子產品世界》雜志2021年9月期)






評論