AI業界,全球最大16核心GPU原理剖析

隨著AI市場的興起,近年來各業界精英在GPU上持續發力,不斷推出全新的產品。新產品在計算能力提升的同時,其芯片面積也已經屢創新高,甚至逼近了制程和成本的平衡極限。前不久,一款超級計算機的發布,讓人嘩然,人們震驚的是其擁有16顆Volta GPU所展現的強大的計算能力,16核GPU可提供高達2PFLOPS的深度學習計算能力,成為目前AI業界的最強者。
本文引用地址:http://www.104case.com/article/201808/390897.htm這16顆Tesla V100的GPU連接在一起,并發揮出如此強大的計算能力的的核心當屬NVLink 2和NVSwitch。
1、NVLINK
隨著開發人員在人工智能(AI)計算等應用領域中越來越依賴并行結構,各行各業中的多GPU 和多CPU系統愈發普及。其中包括采用PCIe系統互聯技術的4GPU和8GPU系統配置來解決非常復雜的重大難題。然而,在多 GPU系統層面,PCIe帶寬逐漸成為瓶頸,這就需要更快速和更具擴展性的多處理器互聯技術。
a、更快速、更具可擴展性的互聯技術
NVLink技術可以提供更高帶寬與更多鏈路,并可提升多GPU和多GPU/CPU系統配置的可擴展性,因而可以解決這種互聯問題。通過提高可擴展性,進而實現超快速的深度學習訓練。
NVLink技術首先將每個方向的信號發送速率從20GB/每秒增加到25GB/每秒。含此技術的產品可用于GPU至CPU或GPU至GPU的通信。
b、3層控制層,能更大限度提高系統吞吐量
NVLink控制器由3層組成,即物理層(PHY)、數據鏈路層(DL)以及交易層(TL)。下圖展示了P100 NVLink 1.0的各層和鏈路:
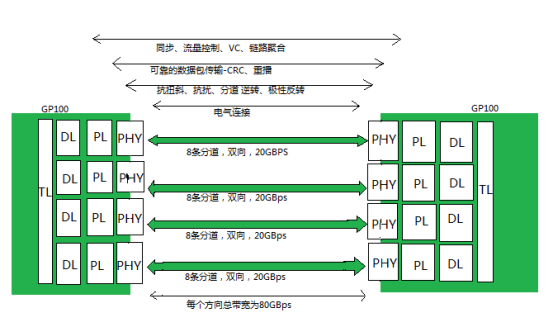
P100搭載的NVLink 1.0,每個P100有4個NVLink通道,每個擁有40GB/s的雙向帶寬,每個P100可以最大達到160GB/s帶寬。
V100搭載的NVLink 2.0,每個V100增加了50%的NVLink通道達到6個,信號速度提升28%使得每個通道達到50G的雙向帶寬,因而每個V100可以最大達到300GB/s的帶寬。
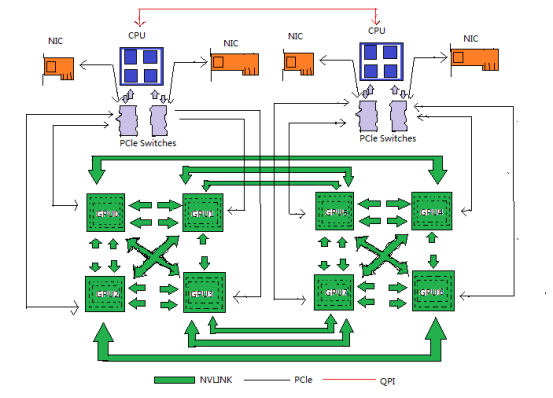
下圖是HGX-1/DGX-1使用的8個V100的混合立方網格拓撲結構,雖然V100有6個NVlink通道,但是實際上因為無法做到全連接,2個GPU間最多只能有2個NVLink通道100G/s的雙向帶寬。而GPU與CPU間通信仍然使用PCIe總線。CPU間通信使用QPI總線。這個拓撲雖然有一定局限性,但依然大幅提升了同一CPU Node和跨CPU Node的GPU間通信帶寬。
2、NVSwitch
a、拓撲擴展實現完全連接的NVLINK
類似于PCIe使用PCIe Switch用于拓撲的擴展,使用NVSwitch實現了NVLink的全連接。NVSwitch作為首款節點交換架構,可支持單個服務器節點中16個全互聯的GPU,并可使全部8個GPU對分別以 300GB/s 的驚人速度進行同時通信。這16個全互聯的GPU(32G顯存V100)還可作為單個大型加速器,擁有 0.5TB統一顯存空間和2PetaFLOPS 計算性能。
由于PCIe 帶寬日益成為多GPU系統級別的瓶頸,深度學習工作負載的快速增長使得對更快速、更可擴展的互連的需求逐漸增加。
NVLink實現了很大的進步,可以在單個服務器中支持八個GPU,并且可提升性能,使之超越 PCIe。但是,要將深度學習性能提升到一個更高水平,將需要使用GPU 架構,該架構在一臺服務器上支持更多的GPU以及GPU之間的全帶寬連接。
b、首款節點交換架構,加速深度學習和高性能計算
NVIDIA NVSwitch 是首款節點交換架構,可支持單個服務器節點中16個全互聯的GPU,并可使全部8個GPU 對分別以300GB/s 的驚人速度進行同時通信。這16個全互聯的GPU還可作為單個大型加速器,擁有0.5TB統一顯存空間和2PetaFLOPS計算性能。
NVIDIA NVLink將采用相同配置的服務器性能提高31%。使用NVSwitch的DGX-2則能夠達到2倍以上的深度學習和高性能計算的加速。












評論