ASIC、FPGA、GPU,三種深度學習硬鑒方案哪種更被看好?

今天被羅振宇的跨年演講刷爆了朋友圈。不過他講深度學習和GPU的時候,真讓人虐心。
本文引用地址:http://www.104case.com/article/201802/375297.htm顯卡的處理器稱為圖形處理器(GPU),它是顯卡的“心臟”,與CPU類似,只不過GPU是專為執行復雜的數學和幾何計算而設計的,這些計算是圖形渲染所必需的。
對深度學習硬件平臺的要求
要想明白“深度學習”需要怎樣的硬件,必須了解深度學習的工作原理。首先在表層上,我們有一個巨大的數據集,并選定了一種深度學習模型。每個模型都有一些內部參數需要調整,以便學習數據。而這種參數調整實際上可以歸結為優化問題,在調整這些參數時,就相當于在優化特定的約束條件。
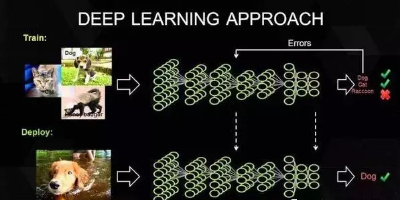
百度的硅谷人工智能實驗室(SVAIL)已經為深度學習硬件提出了DeepBench基準,這一基準著重衡量的是基本計算的硬件性能,而不是學習模型的表現。這種方法旨在找到使計算變慢或低效的瓶頸。 因此,重點在于設計一個對于深層神經網絡訓練的基本操作執行效果最佳的架構。那么基本操作有哪些呢?現在的深度學習算法主要包括卷積神經網絡(CNN)和循環神經網絡(RNN)。基于這些算法,DeepBench提出以下四種基本運算:
矩陣相乘(Matrix Multiplication)——幾乎所有的深度學習模型都包含這一運算,它的計算十分密集。
卷積(Convolution)——這是另一個常用的運算,占用了模型中大部分的每秒浮點運算(浮點/秒)。
循環層(Recurrent Layers )——模型中的反饋層,并且基本上是前兩個運算的組合。
All Reduce——這是一個在優化前對學習到的參數進行傳遞或解析的運算序列。在跨硬件分布的深度學習網絡上執行同步優化時(如AlphaGo的例子),這一操作尤其有效。
除此之外,深度學習的硬件加速器需要具備數據級別和流程化的并行性、多線程和高內存帶寬等特性。 另外,由于數據的訓練時間很長,所以硬件架構必須低功耗。 因此,效能功耗比(Performance per Watt)是硬件架構的評估標準之一。

GPU在處理圖形的時候,從最初的設計就能夠執行并行指令,從一個GPU核心收到一組多邊形數據,到完成所有處理并輸出圖像可以做到完全獨立。由于最初GPU就采用了大量的執行單元,這些執行單元可以輕松的加載并行處理,而不像CPU那樣的單線程處理。另外,現代的GPU也可以在每個指令周期執行更多的單一指令。所以GPU比CPU更適合深度學習的大量矩陣、卷積運算的需求。深度學習的應用與其原先的應用需求頗為類似。GPU廠家順理成章的在深度學習,找到了新增長點。
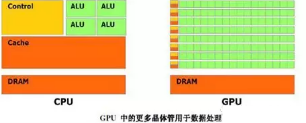
英偉達以其大規模的并行GPU和專用GPU編程框架CUDA主導著當前的深度學習市場。但是越來越多的公司開發出了用于深度學習的加速硬件,比如谷歌的張量處理單元(TPU/Tensor Processing Unit)、英特爾的Xeon Phi Knight's Landing,以及高通的神經網絡處理器(NNU/Neural Network Processor)。
多虧了新技術和充滿GPU的計算機數據中心,深度學習獲得了巨大的可能應用領域。這家公司的任務中很大一部分都只是獲取用來探索這些可能性的時間和計算資源。這項工作極大地擴張了設計空間。就科學研究而言,覆蓋的領域已經在指數式擴張了。而這也已經突破了圖像識別的范疇,進入到了語音識別、自然語言理解等其它任務中。正因為覆蓋的領域越來越多,微軟在提高其GPU集群的運算能力的同時也在探索使用其它的專用處理器,其中包括FPGA——一種能針對特定任務(如深度學習)編程的芯片。而且這項工作已經在全世界的技術和人工智能領域掀起了波瀾。英特爾完成了其歷史上最大的并購案,收購了專注FPGA的Altera。
FPGA的優勢是,如果計算機需要改變,它可以被重新裝配。但是,最通用、最主流的方案仍舊是使用 GPU,以并行處理大量數學運算。不出預料,GPU 方案的主要推動者是該市場的霸主英偉達。

英偉達旗艦顯卡 Pascal Titan X
事實上, 2009 年之后人工神經網絡的復興與 GPU 有緊密聯系——那一年,幾名斯坦福的學者向世界展示,使用 GPU 可以在合理的時間內訓練深度神經網絡。這直接引發了 GPU 通用計算的浪潮。
英偉達首席科學家、斯坦福并發 VLSI 架構小組的負責人 William J. Dally 表示:“行內每個人現在都在做深度學習,這方面,GPU 幾乎已經達到了最好。”

幾乎所有深度學習的研究者都在使用GPU
熟悉深度學習的人都知道,深度學習是需要訓練的,所謂的訓練就是在成千上萬個變量中尋找最佳值的計算。這需要通過不斷的嘗試實現收斂,而最終獲得的數值并非是人工確定的數字,而是一種常態的公式。通過這種像素級的學習,不斷總結規律,計算機就可以實現像像人一樣思考。如今,幾乎所有的深度學習(機器學習)研究者都在使用GPU進行相關的研究。當然,只是“幾乎”。除了GPU之外,包括MIC和FPGA也提供了不同的解決方案。
“技術發展和科技的發展,是需要不同的技術一起來參與。無論是GPU也好、FPGA也好或者是專用的神經網芯片也好,它的主要目的都是推動深度學習(機器學習)這個方向的技術發展。那么我們在初期,確實可以嘗試不同的技術,來探討哪種技術可以更好的適合這項應用。從目前來看,深度學習大量的使用,主要集中在訓練方面。那么在這個領域,GPU確實是非常適合的,這也體現在所有的這些工業界的大佬如BAT、谷歌,Facebook等等,都在使用GPU在做訓練。”NVIDIA如是說。面對FPGA以及ASIC的挑戰,NVIDIA表示“考慮是否設計低功耗的GPU,來滿足用戶的需求”。
除了硬件方面的因素之外,英偉達從軟件方面解答了GPU對于深度學習應用的價值。首先從深度學習應用的開發工具角度,具備CUDA支持的GPU為用戶學習Caffe、Theano等研究工具提供了很好的入門平臺。其實GPU不僅僅是指專注于HPC領域的Tesla,包括Geforce在內的GPU都可以支持CUDA計算,這也為初學者提供了相對更低的應用門檻。除此之外,CUDA在算法和程序設計上相比其他應用更加容易,通過NVIDIA多年的推廣也積累了廣泛的用戶群,開發難度更小。最后則是部署環節,GPU通過PCI-e接口可以直接部署在服務器中,方便而快速。得益于硬件支持與軟件編程、設計方面的優勢,GPU才成為了目前應用最廣泛的平臺。
深度學習發展遇到瓶頸了嗎?
我們之所以使用GPU加速深度學習,是因為深度學習所要計算的數據量異常龐大,用傳統的計算方式需要漫長的時間。但是,如果未來深度學習的數據量有所下降,或者說我們不能提供給深度學習研究所需要的足夠數據量,是否就意味著深度學習也將進入“寒冬”呢?“做深度神經網絡訓練需要大量模型,然后才能實現數學上的收斂。深度學習要真正接近成人的智力,它所需要的神經網絡規模非常龐大,它所需要的數據量,會比我們做語言識別、圖像處理要多得多。假設說,我們發現我們沒有辦法提供這樣的數據,很有可能出現寒冬”。
其實深度學習目前還在蓬勃發展往上的階段。比如說我們現階段主要做得比較成熟的語音、圖像方面,整個的數據量還是在不斷的增多的,網絡規模也在不斷的變復雜。
對于NVIDIA來說,深度學習是GPU計算發展的大好時機,其實這是一場各個能夠實現深度學習各個芯片,以及巨頭賽跑的結局。誰最先找到自己逼近深度學習最適合的芯片模式,誰就是勝利者。
GPU、FPGA 還是專用芯片?
盡管深度學習和人工智能在宣傳上炙手可熱,但無論從仿生的視角抑或統計學的角度,深度學習的工業應用都還是初階,深度學習的理論基礎也尚未建立和完善,在一些從業人員看來,依靠堆積計算力和數據集獲得結果的方式顯得過于暴力——要讓機器更好地理解人的意圖,就需要更多的數據和更強的計算平臺,而且往往還是有監督學習——當然,現階段我們還沒有數據不足的憂慮。未來是否在理論完善之后不再依賴數據、不再依賴于給數據打標簽(無監督學習)、不再需要向計算力要性能和精度?
退一步說,即便計算力仍是必需的引擎,那么是否一定就是基于GPU?我們知道,CPU和FPGA已經顯示出深度學習負載上的能力,而IBM主導的SyNAPSE巨型神經網絡芯片(類人腦芯片),在70毫瓦的功率上提供100萬個“神經元”內核、2.56億個“突觸”內核以及4096個“神經突觸”內核,甚至允許神經網絡和機器學習負載超越了馮·諾依曼架構,二者的能耗和性能,都足以成為GPU潛在的挑戰者。
不過,這些都尚未產品化的今天,NVIDIA并不擔憂GPU會在深度學習領域失寵。首先,NVIDIA認為,GPU作為底層平臺,起到的是加速的作用,幫助深度學習的研發人員更快地訓練出更大的模型,不會受到深度學習模型實現方式的影響。其次,NVIDIA表示,用戶可以根據需求選擇不同的平臺,但深度學習研發人員需要在算法、統計方面精益求精,都需要一個生態環境的支持,GPU已經構建了CUDA、cuDNN及DIGITS等工具,支持各種主流開源框架,提供友好的界面和可視化的方式,并得到了合作伙伴的支持,例如浪潮開發了一個支持多GPU的Caffe,曙光也研發了基于PCI總線的多GPU的技術,對熟悉串行程序設計的開發者更加友好。相比之下,FPGA可編程芯片或者是人工神經網絡專屬芯片對于植入服務器以及編程環境、編程能力要求更高,還缺乏通用的潛力,不適合普及。

目前來說,GPU貴,功耗高,運行效率比FPGA高,易使用。FPGA功耗,單顆性能是低的,單顆FPGA的硬件設計挑戰沒有GPU大,但是總體性價比和效率不占優;Intel收購Altera是否可以通過其工藝實力,給其帶來極具的功能提升,我們還在長期的期待過程中。FPGA如果實現深度學習功能,還需要大批量使用,才能實現完整的功能,且需要與CPU相結合。
另外一個問題是,FPGA的大規模開發難度偏高,從業人員少。我們可以通過ARM戰勝MIPS、以及STM32的迅速發展可以看到,一個好的生態環境,更多的從業人口,比技術、性價比本身更利于其發展。所以易用性是幾個并行技術發展的一個重要考量維度。
FPGA猶如樂高,其靈活性,根據實際應用的需求,構建我所需要的硬件組件。但是樂高本身就是一種浪費:其功耗性能比,可變布線資源、多余的邏輯資源,其實都是浪費。所以你如果用樂高做一個機器人跟一個專門為格斗而開發的機器人對抗,結果可想而知。
FPGA在深度學習的應用場景,存在的價值在于其靈活性。DNN是深度神經網絡系統的統稱,實際使用的時候,使用幾層網絡,最終結果用什么樣的篩選策略,在不同的應用和不同的設計框架下面,對硬件的訴求并不相同。
要看設計者的建模方案。GPU的一個缺點是,他的組件模塊是乘法器、加法器。雖然深度學習的參數都是數學模型,需要對RTL級別的變化,但是GPU的硬件資源是以乘法器、加法器這樣量級的硬件單元組成的。如果GPU的預先配置與使用者的模型相差甚遠。例如:加法器配置15個,乘法器配置15個。但實際使用的時候,乘法器使用量是15個,但是加法器只需要2個。這就浪費了13個加法器的資源。而FPGA是以查找表和觸發器子單元,組合成任意運算單元。
但是換種角度來看FPGA本身就是一種浪費。
當然ASIC是能效最高的,但目前,都在早期階段,算法變化各異。想搞一款通用的ASIC適配多種場景,還是有很多路需要走的。但是,在通信領域,FPGA曾經也是風靡一時,但是隨著ASIC的不斷發展和蠶食,FPGA的份額和市場空間已經岌岌可危。如果深度學習能夠迅速發展,有可能這個過程會比通信領域過程更短。
人機大戰落幕后的兩個月,谷歌硬件工程師 Norm Jouppi 才公開了其加速硬件的存在。在博客中,他解釋道,谷歌給數據中心裝備這些加速器卡已經有超過一年的時間。雖然谷歌對技術細節嚴格保密,但已透露它們專為谷歌開源項目 TensorFlow 而優化;它采取了:ASIC。
谷歌發布了人工智能芯片:Tensor Processing Unit,這是ASIC
據知情人士說,TPU已經在谷歌的數據中心運行了一年時間,由于谷歌嚴守TPU的秘密,所以TPU一直不為外界所知。這位知情人士說,從目前的運行效果來看,TPU每瓦能耗的學習效果和效率都比傳統的CPU、GPU高出一個數量級,達到了摩爾定律預言的七年后的CPU的運行效果。這位知情人士不無煽情的說,請忘掉CPU、GPU、FPGA吧。
如此看來,在深度學習方面,TPU可以兼具桌面機與嵌入式設備的功能,也就是低能耗高速度。
據報道,TPU之所以具有良好的機器學習能力,是因為這種芯片具有比較寬的容錯性,這就意味著,達到與通用芯片相同的學習效果,TPU不需要通用芯片那樣多的晶體管,不需要通用芯片上那樣多的程序操作步驟,也就是說,相同數量的晶體管,在TPU上能做更多的學習工作。
谷歌研發TPU并非要取代CPU或者FPGA,谷歌認為,TPU是介于CPU和ASIC (application-specific integrated circuit:應用集成電路)之間的芯片。ASIC用于專門的任務,比如去除噪聲的電路,播放視頻的電路,但是ASIC明顯的短板是不可更改任務。通用CPU可以通過編程來適應各種任務,但是效率能耗比就不如ASIC。一如前邊所言,在機器學習方面,TPU兼具了CPU與ASIC的特點,可編程,高效率,低能耗.
最后說說,異構處理器:
什么是異構多核處理器?簡單地說異構多核處理器指的是在CPU里集成了 CPU與【其他模塊】一起同步工作,【也就是說 一塊cpu 里不單有 CPU運算模塊 還有其他運算模塊 例如 GPU,FPGA,DSP等等。
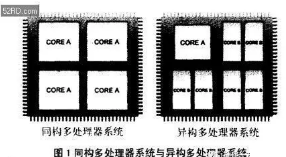
AMD,Nvidia以及賽靈思公司都在進行異構多核處理器的研發
這是AMD的異構多核處理器

AMD在異構多核處理器發展方面是不遺余力,早在2012年就成立了“異構系統架構基金會”(HSA Foundation),首批會員是AMD、 ARM、Imagination Technologies、 聯發科和德州儀器(TI)是“異構系統架構基金會”的創始成員。

瞧瞧,英特爾的老對手ARM和AMD都在里面呢
HSA聯盟發展了兩年也有一些新成員加入,但是總的來說對英特爾威脅不大,直到 ,直到,賽靈思推了zynq的時候。
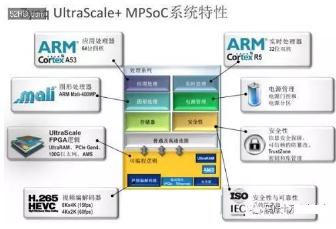
看看它的內部結構:
1、四核A53處理器 CPU
2、一個GPU Mali-400MP
3、一個Cortex-R5 CPU
4、電源管理單元,AMS單元
5、H.265(HEVC)視頻編解碼器
6、安全模塊
7、UltraScale FPGA 單元;
這其實就是一款異構處理器,如前所述,它是一款ASIC就級的異構處理器!而且是64位,采用16nm FinFET工藝的處理器!而且是采用FPGA實現硬加速的處理器!但是這個ARM是不是偏弱了一點?做深度學習還是欠把火后。
Intel收購Altera,應該最終的目的也是要在異構處理器上面做出更多的文章吧。X86+FPGA,看起來好像很美。但是X86和FPGA結合就更符合模型么?目前也沒有應用,更沒有看到成熟的芯片推出。兩個巨無霸的整合,可以說是用腳趾頭都能想到很多的困難。Intel這口也許吃得太大了,吞得很痛苦。不是每個公司都有很強大執行力的,歷史包袱在所難免。






評論