IBM展示10倍速GPU機器學習,處理30GB訓練數據只要1分鐘

IBM研究院與瑞士洛桑聯邦理工學院共同于2017 NIPS Conference發表大數據機器學習解決方案,此方法可以利用GPU在一分鐘內處理完30GB的訓練數據集,是現存有限內存訓練方法的10倍。
本文引用地址:http://www.104case.com/article/201712/372773.htm研究團隊表示,機器訓練在大數據時代遇到的挑戰是動輒TB等級起跳的訓練數據,這是常見卻又棘手的問題,或許一臺有足夠內存容量的服務器,就能將所有訓練數據都加載內存中進行運算,但是仍要花費數小時,甚至是數周。
他們認為,目前如GPU等特殊的運算硬件,的確能有效加速運算,但僅限于運算密集的工作,而非數據密集的任務。 如果想要善用GPU運算密集的優勢,便需要把數據預先加載到GPU內存,而目前GPU內存的容量最多只有16GB,對于機器學習實作來說并不算寬裕。
批次作業看似是一個可行的方法,將訓練數據切分成一塊一塊,并且依造順序加載至GPU做模型訓練,不過經實驗發現,從CPU將數據搬移進GPU的傳輸成本,完全蓋過將數據放進GPU高速運算所帶來的好處。 ,IBM研究員Celestine Dünner表示,在GPU做機器學習最大的挑戰,就是不能把所有的數據都丟進內存里面。
為了解決這樣的問題,研究團隊開發為訓練數據集標記重要性的技術,因此訓練只使用重要的數據,那多數不必要的數據就不需要送進GPU,藉此大大節省訓練的時間。 像是要訓練分辨狗與貓圖片的模型,一旦模型發現貓跟狗的差異之一為貓耳必定比狗小,系統將保留這項特征,在往后的訓練模型中都不再重復回顧這個特征,因此模型的訓練會越來越快。 IBM研究員Thomas Parnell表示,這樣的特性便于更頻繁的訓練模型,也能更及時的調整模型。
這個技術是用來衡量每個數據點對學習算法的貢獻有多少,主要利用二元差距的概念并及時影響調整訓練算法。 將這個方法實際應用,研究團隊在異質平臺(Heterogeneous compute platforms)上,為機器學習訓練模型開發了一個全新可重復使用的組件DuHL,專為二元差距的異質學習之用。
IBM表示,他們的下一個目標是在云端上提供DuHL,因為目前云端GPU服務的計費單位是小時,如果訓練模型的時間從十小時縮短為一小時,那成本節省將非常驚人。
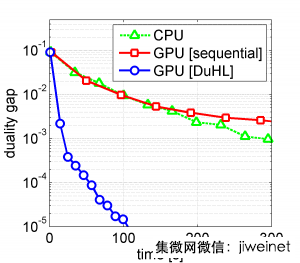
(上圖)圖中顯示了三種算法所需的時間,包含DuHL在大規模的支持向量機的表現,所使用的數據集都為30GB的ImageNet數據庫,硬件為內存8GB的NVIDIA Quadro M4000 GPU, 圖中可以發現GPU序列批次的效率,甚至比單純CPU的方法還要糟,而DuHL的速度為其他兩種方法的10倍以上。





評論