收購Nervana后 Intel在AI芯片上進展如何?


本文引用地址:http://www.104case.com/article/201612/341370.htm
Xeon(至強)是目前Intel產品中最經典、也是使用最廣泛的平臺,是一個能夠針對不同種類的工作進行計算支持的平臺。全球90%以上的數據分析在Intel Xeon 處理器平臺上實現;其中人工智能、深度學習相關方案及部署中,也有超過90%的案例使用Xeon CPU。
Xeon Phi是Xeon的進階版,加入了眾核的概念。在Xeon的基礎上加入多個64核、74核的加速器,使其可以在軟件的配合下大幅提高計算性能。對于例如Caffe、Alexnet這樣的網絡,在經過針對Xeon Phi進行軟硬件結合的優化之后,性能提升了400倍。可見軟硬件結合能夠大幅提升深度神經網絡的訓練效率。
同時,若可以確定系統的應用領域是某種工作負載,則可以采用FPGA或Nervana這類定制化的硬件架構作為支持。FPGA可以用來做網絡計算、視頻處理、語音等方面。
與FPGA不同的,也是人工智能從業者最為關心的,Lake Crest硬件架構,是專為深度學習這種大規模運算及需要實時緩存的系統設計的。

Lake Crest是主要基于張量運算的架構,矩陣運算屬于張量運算。圖中綠色部分是專門針對矩陣運算的處理單元。同時運用Flexpoint技術,一個基于定點與雙精度浮點之間可以變化的技術,來提供較高的并行化計算能力,計算密度是目前最好的硬件加速水平的十倍。同時,由于計算單元專門針對張量運算所設計,所以功耗較低。
上圖周圍的四個黃色塊為高帶寬內存,通過專用的內存訪問接口連接到主芯片,中間灰色大區域可以看作一個芯片。這些內存是直接由軟件管理的,因此整個計算中不存在Cache,也就不存在不可預測的Cache miss,何時、去哪里讀取數據完全由程序控制。
單靠一個這樣的芯片可能處理不了所有的深度學習訓練任務,針對特殊的需求,可以采取多個芯片協同工作的方式。多個芯片之間的互聯靠RCL,RCL是Intel專門定制的Interchip Link,它的速度比傳統的PCIE快20倍,而且是雙向的數據帶寬通道,能夠達到8TB/s。借由RCL,一個芯片最多可以與12個芯片互聯,以組成訓練所需的規模較大的超網格。
記憶是AI產生認知的必要條件
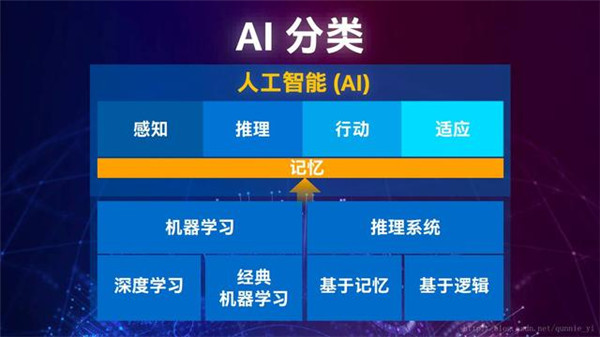
對于AI今后發展的展望,宋繼強不止一次強調,記憶是AI產生認知的必要條件。
“智能體現哪些方面?首先是感知外界環境的能力;二是根據感知進行推理;三是推理形成決策觸動機器做反饋(如說視覺、聲音);最后且更重要的是能適應環境,不然就會變成死程序。這里有條橫線很重要——記憶。Numenta創始人Jeff Hawkins寫過一本書《人工智能的未來》,就是專門講怎樣去看待人工智能。智能就表現在能利用記憶進行預測,若能做到這一點,機器就真有智能了。記憶能力非常重要,很多人工智能廠商正在將它加入系統。”









評論