基于矩陣乘法器的MP3解碼優化設計


2.2 基于矩陣乘法器的快速DCT算法優化
3×3矩陣乘法器由觸發器和乘累加器組成,是高性能DSP處理器的重要部件,也是實時處理的核心,其速度直接影響DSP處理器的速度。矩陣乘法器的實現有很多種,基本上都基于并行計算原則。由于每列結果與其他列不相關,因此可以通過增加乘法器多列同時計算,經過n次乘累加就可以得到最后結果。圖3給出矩陣乘法器的結構。本文引用地址:http://www.104case.com/article/187628.htm
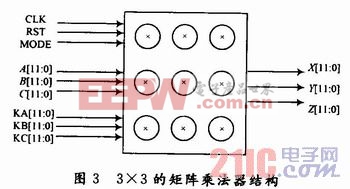
顯然,這種結構的計算速度很快,但是使用乘法器會因矩陣維數n的增加而快速增加,使用的觸發器也很多。在很多場合下,只要滿足處理速度的要求,完全沒有必要浪費這么多硬件資源,而是只要1個乘累加單元流水作業,分步計算每1列結果既可。在做乘累加計算1個元素時候,準備下一組參與運算的數據,如此循環,同樣可以獲得較高的處理速度。
在該設計中,由于B矩陣是1×n的一維向量輸入數據,A矩陣為DCT系數矩陣,A矩陣中的元素為n個系數的線性組合,因此整個矩陣乘法器需要2組n個觸發器分別存放輸入數據和n個系數,1個乘累加單元。輸入數據X[0:n],從X[O]到X[n]循環n次進入乘法器,使用選擇信號Assi-gn[0:n]選擇系數C[0:n],另外系數符號由Sign信號軟件控制,基本結構如圖4所示。
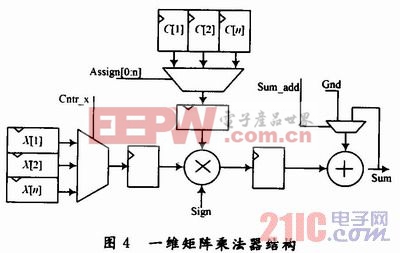
由于DCT計算本質上就是n×n矩陣乘法運算,而n×n矩陣乘法器是在通用乘法器的基礎上增加2組分別存放系數矩陣的系數C(n)和輸入X(n)的n個寄存器,使之實現長度為n的乘累加功能,同時還需保存上次乘法結果。其中,DCT中的系數是一組n維基的n種線性組合。只需1次輸入n個系數,使用軟件進行選擇和符號控制就可實現這些不同系數組合,無需反復往寄存器中置數,大大提高了取數/置數的效率,節省了整個DCT的運算時間。
因此在計算32點的DCT,可將32點DCT分解為2個16點的DCT計算,計算量也減少1倍。可以使用2組16×16的矩陣乘法器并行計算,使得計算時間大幅減少。表2是通過增加矩陣乘法器優化處理后,子帶綜合濾波使用不同實現方式所需要的時間。

結果表明,第2.1節中使用快速32點DCT算法改進子帶綜合濾波計算是有效的,直接減少59%的計算時間。在采用并行2個16×16矩陣乘法器加速快速32點DCT的計算,可以取得明顯的效果:使得計算時間比原算法減少了約91.4%,而且硬件上只增加1個乘法器和30個數據鎖存器,以及部分控制電路。使用軟硬件協同操作就可以獲得子帶綜合濾波計算速度上的大幅度上升。
3 結語
該設計面向SoC實現了利用增加矩陣乘法器就可加快基于32點快速DCT算法的MP3解碼中子帶綜合濾波的處理速度,大大緩解了系統的頸瓶,使得采用系統主頻比較低(fs≤100 MHz)的SoC平臺進行MP3的解碼成為可能。

電源濾波器相關文章:電源濾波器原理






評論