Armv9 技術講堂 | Neon、SVE 和 SME 實現矩陣-矩陣乘法的比較

Arm 始終專注于架構演進,確保生態系統能夠適應未來的技術趨勢和不斷變化的計算需求。Armv9 架構上的 可伸縮矩陣擴展 (SME) 顯著提高了 Arm CPU 對現有人工智能 (AI) 和機器學習 (ML) 工作負載的處理能力,從而在各種 AI 驅動的設備和應用中帶來速度更快、響應更靈敏的用戶體驗。
本文引用地址:http://www.104case.com/article/202409/462643.htm在此前的內容中,Arm 技術專家為大家簡要介紹了 SME 和 SME 指令 ,本期將帶你了解如何使用 Neon、可伸縮向量擴展 (SVE) 和 SME 這三種不同的 Arm 技術實現相同的矩陣-矩陣乘法算法。這三個示例展現了這些技術之間的關鍵差異,為開發者將代碼從 Neon、SVE/SVE2 移植到 SME/SME2 提供指導。
架構演進
Armv7 引入了高級 SIMD 擴展,為一系列整型和浮點型提供單指令多數據 (SIMD) 操作。Neon 是高級 SIMD 指令的一種實現方案,作為部分 Arm Cortex-A 系列處理器的擴展提供。2011 年 Armv7-A 中引入了 Neon。Neon 提供固定寬度的 128 位寄存器。這意味著每條 Neon 指令對固定數量的數據值進行操作,例如四個 32 位數據值。
2016 年 Armv8-A 中引入了 SVE,2021 年 Armv9-A 中引入了 SVE2,它們提供可變長度寄存器。寄存器的大小由實現方案定義,從 128 位到 2048 位寄存器不等。這意味著程序員不知道可用寄存器的大小,因此必須將代碼編寫為與向量長度無關。因此,每條指令處理的數據值的數量不是固定的,而是可變的。
2021 年 Armv9-A 中引入了 SME 和 SME2,也提供可變長度寄存器。SME 引入了兩個關鍵的新架構特性:Streaming SVE 模式和 ZA 存儲。Streaming SVE 模式是一種高吞吐量的矩陣數據處理模式,ZA 存儲則是一種專用的二維數組,可以方便地進行常見的矩陣操作。這些特性使 SME 和 SME2 能夠高效地處理矩陣和基于向量的工作負載。
這些 SIMD 架構擴展提供的指令可加速多種應用,包括媒體和信號處理應用、高性能計算 (HPC) 應用,以及 ML 應用。
本文中的示例使用了內置函數 (intrinsics),即編譯器提供的與特定 Arm 指令相對應的函數。這使得程序員能夠用 C 語言而不是匯編語言編寫整個程序。
矩陣-矩陣乘法
本文中的所有三個示例都能夠實現矩陣-矩陣乘法。矩陣乘法需要接收兩個輸入矩陣,通過將第一個矩陣一行的每個元素與第二個矩陣一列的相應元素相乘,然后對這些乘積求和,從而生成一個結果矩陣。結果矩陣的維度由第一個矩陣的行數和第二個矩陣的列數決定。例如,3 x 2 矩陣乘以 2 x 3 矩陣將得到 3 x 3 矩陣。
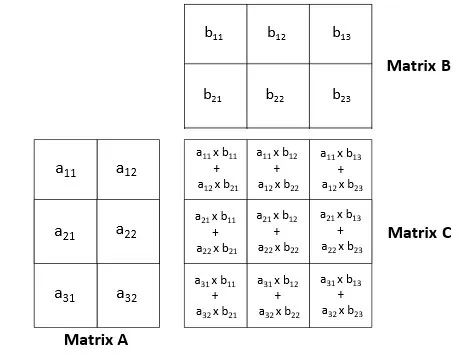
要將矩陣 A 和矩陣 B 相乘,矩陣 A 的列數必須等于矩陣 B 的行數。將矩陣 A 和矩陣 B 相乘將得到矩陣 C。
Neon
此示例使用 Neon 內置函數來執行矩陣-矩陣乘法。相關代碼執行以下操作:
兩個輸入矩陣包含以列優先格式存儲的 32 位浮點數據。
代碼以 4 x 4 的塊形式迭代處理這些矩陣中的所有數據。
vld 內置函數將輸入矩陣的行和列中的四個值加載到 Neon 寄存器中。
每個 fma Neon 內置函數執行四次乘加運算,計算正在處理的 4 x 4 塊的結果。
vst 內置函數將結果矩陣存儲到內存中。
以下是使用 Neon 內置函數的示例代碼:
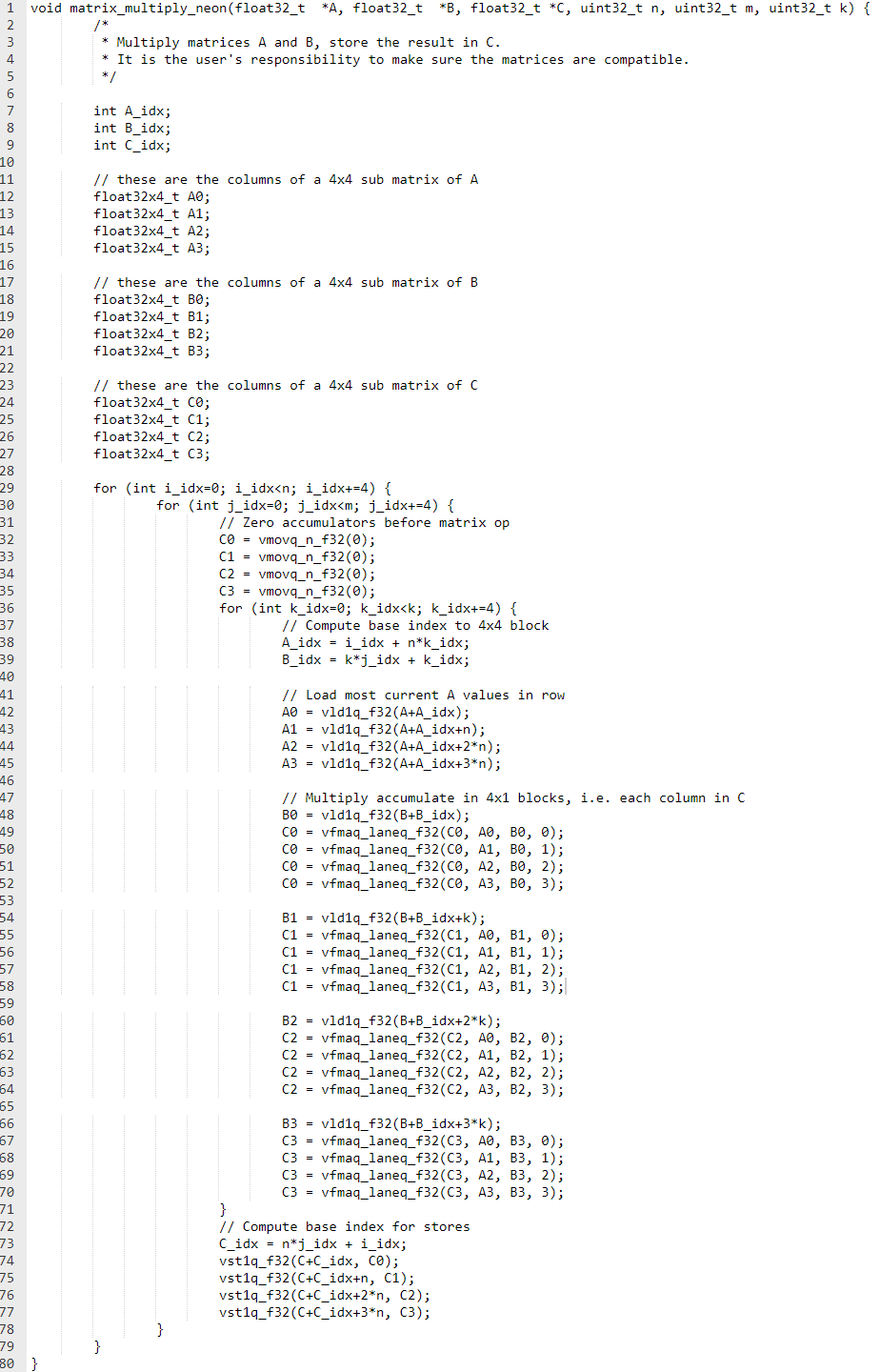
此示例使用以下 Neon 代碼特性:

此示例使用 4 x 4 的固定塊大小。這意味著輸入矩陣在兩個維度上都必須是四的倍數。可以通過用零填充矩陣來處理其他大小的矩陣。
SVE/SVE2
此示例使用 SVE2 內置函數來執行矩陣-矩陣乘法。
Neon 示例和 SVE2 示例之間的主要區別在于 SVE2 使用可變長度向量。Neon 示例可以使用 4 x 4 的固定塊大小來匹配 Neon 寄存器中的四個 32 位值,但程序員要到運行時才能知道 SVE2 寄存器的大小。這意味著代碼必須與向量長度無關。此示例使用 predication 來控制 SVE2 內置函數操作的數據值的數量。這意味著無論實現的大小如何,它們都能夠精準地適配 SVE2 寄存器。Neon 示例使用 32 位浮點數據類型 float32x4_t,其中 的“4”表示每個 Neon 寄存器可以包含四個 32 位值。SVE2 示例使用 svfloat32_t 數據類型,因為無法在運行前知道 SVE2 寄存器的大小。
相關代碼執行以下操作:
兩個輸入矩陣包含以列優先格式存儲的 32 位浮點數據。
代碼以四行一組的形式迭代處理這些矩陣中的所有數據。它使用 svcntw 內置函數,返回向量中 32 位元素的數量,以匹配加載到 SVE2 寄存器大小的列數。這有助于避免對外循環每次迭代中的元素數量進行硬編碼。whileit 內置函數生成一個 predicate,以確保不超過矩陣的界限。
四個 svld 內置函數使用之前生成的 predicate 將矩陣數據加載到 SVE2 寄存器中。
svlma 內置函數執行乘加運算,計算當前迭代的結果。
svst 內置函數將結果矩陣存儲到內存中。
以下是使用 SVE2 內置函數的示例代碼:
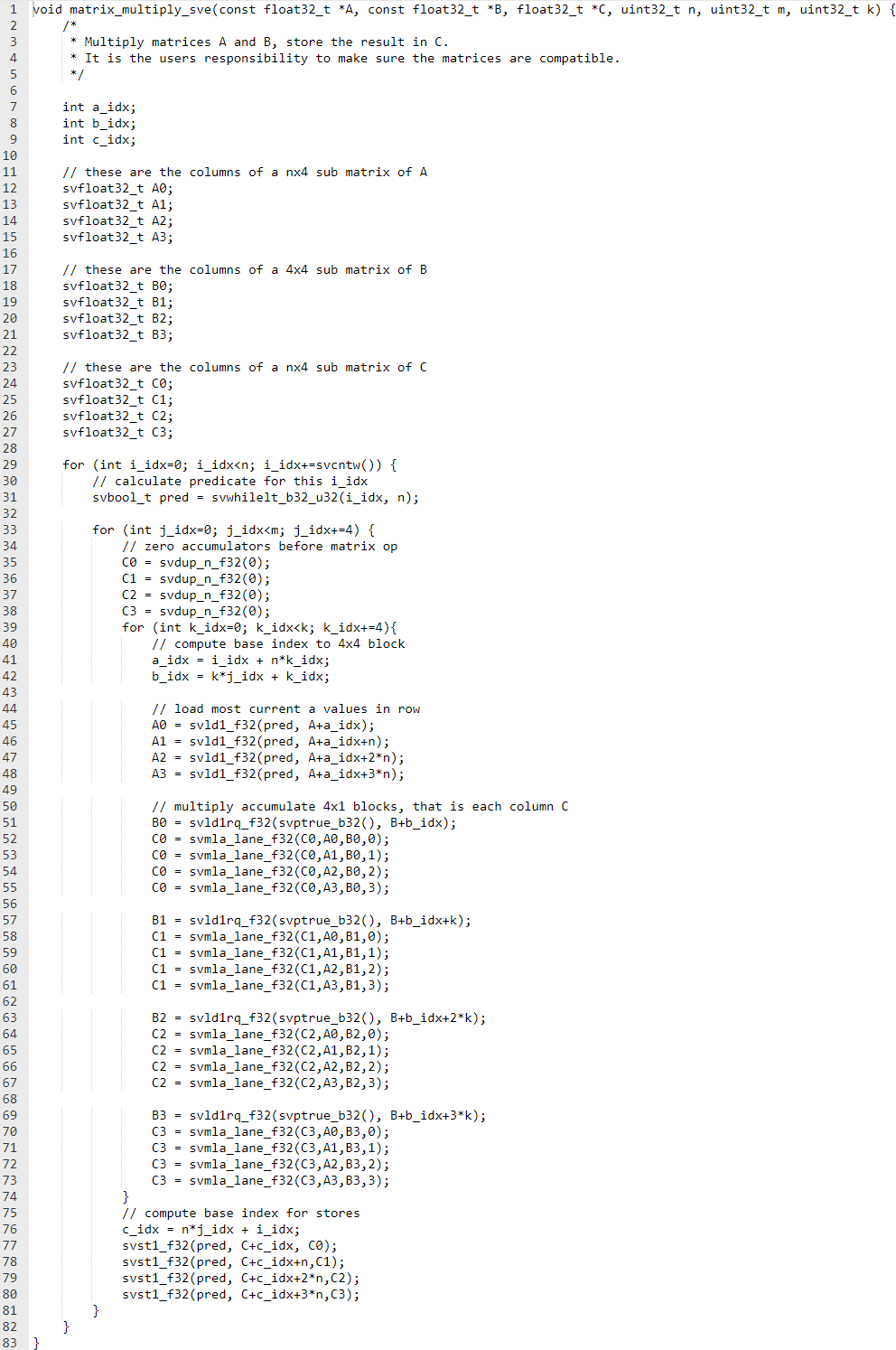
此示例使用以下 SVE2 代碼特性:

SME/SME2
此示例使用 SME2 匯編指令來執行矩陣-矩陣乘法。SME2 示例與其他示例的區別如下:
SME2 示例使用匯編代碼,而不是其他示例所使用的內置函數。
SME2 提供 ZA 存儲,這是專為矩陣運算設計的二維數據數組。此 ZA 存儲內的子數組可作為 tile 進行訪問,并且 tile 內的元素可以垂直或水平訪問。這為操作矩陣數據提供了非常靈活的機制。
SME2 提供了執行矩陣運算的新指令。例如,fmopa 指令可計算外積。
SME2 提供了一種多向量二維 predication 機制,以確保不超出矩陣邊界。
Streaming SVE 模式(使用 smstart 指令進入的)啟用 SME2 指令和 ZA 存儲。
此示例使用 matLeft 和 matRight 作為輸入矩陣。示例中用到了以下運算原理:兩個矩陣相乘等同于依次對 matLeft 的每一列和 matRight 的每一行的外積求和。
初始輸入矩陣作為行優先數組存儲在內存中。矩陣乘法是將 matLeft 的一列與 matRight 的一行的外積求和。由于外積需要 matLeft 的列元素,因此代碼重新排列 matLeft 數據,以便列元素連續存儲在內存中。為了簡潔起見,本文未展示此類數據重排,如需參考可查看 SME 程序員指南。
此示例包含三個嵌套循環:
最外層循環用于迭代處理結果矩陣的行。
中間層循環用于迭代處理結果矩陣的列。
最內層循環用于迭代處理 K 維度,通過對乘積求和生成結果矩陣元素。
使用 ld1w 指令將矩陣數據從內存加載到 ZA 存儲。外積計算使用 fmopa 指令。每個 fmopa 指令讀取兩個 SVE Z 輸入向量,并使用結果更新整個 SME ZA tile。二維 predication 確保不超出矩陣的邊界。最后,st1w 指令將結果從 ZA 存儲寫入內存。









評論