可配置處理器開發(fā)原理

首先,頻率并不代表性能。低功耗的針對(duì)特殊應(yīng)用的而設(shè)計(jì)的處理器架構(gòu)比頻率高得多的通用處理器性能可能更好。所以頻率代表性能的結(jié)論只能局限于同樣的架構(gòu)的基礎(chǔ)上。同時(shí)過高的頻率意味著更高的功耗。
其次,應(yīng)用的發(fā)展對(duì)處理器的需求越來越多樣化。我們可以看到單顆通用處理器的極限已經(jīng)到來,通用處理器需要處理的應(yīng)用越來越復(fù)雜,需要多內(nèi)核的支持。最大半導(dǎo)體公司Intel的多核的產(chǎn)品策略足以證明這一點(diǎn)。另外,后PC時(shí)代是消費(fèi)電子產(chǎn)品的時(shí)代,通用的CPU和DSP都無法滿足多種應(yīng)用的要求。針對(duì)特殊應(yīng)用設(shè)計(jì)的SOC要求能夠靈活設(shè)計(jì)針對(duì)應(yīng)用的最優(yōu)化處理器:性能好、功耗低、面積小、大I/O帶寬……
綜上所述,應(yīng)用的需求的發(fā)展促進(jìn)了可配置處理器技術(shù)的產(chǎn)生和發(fā)展。
以Tensilica的Xtensa可配置處理器架構(gòu)為例,探討可配置處理器的開發(fā)原理。
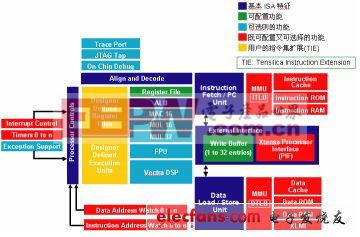
Xtensa可配置處理器架構(gòu)是可配置可擴(kuò)展的微處理器技術(shù),可以用于片上系統(tǒng)SOC設(shè)計(jì)。現(xiàn)在的SOC需要更高系統(tǒng)性能、更高輸入/輸出帶寬和更高功耗利用率, Xtensa架構(gòu)均實(shí)現(xiàn)提供相應(yīng)的解決方案。系統(tǒng)設(shè)計(jì)師可根據(jù)各自的應(yīng)用需求,首先配置和選擇架構(gòu)元素,比如:內(nèi)部cache大小,總線位寬,F(xiàn)PU單元, DSP引擎,中斷數(shù)量… 進(jìn)而針對(duì)應(yīng)用擴(kuò)展添加全新的指令、寄存器和I/O端口來設(shè)計(jì)具有專用功能的處理器內(nèi)核。這種方法甚至能提供與手工RTL設(shè)計(jì)的硬邏輯有可比性的性能、尺寸和功耗等特性。通過圖1可以看到Xtensa處理器的架構(gòu)。
Xtensa處理器產(chǎn)生器可通過增加新的功能來自動(dòng)產(chǎn)生用戶所需要的硬件,產(chǎn)生硬件是經(jīng)過驗(yàn)證的RTL代碼格式。自動(dòng)產(chǎn)生的處理器RTL代碼可以和現(xiàn)在的SOC設(shè)計(jì)流程無縫結(jié)合,用于邏輯綜合。處理器產(chǎn)生器還可建立與產(chǎn)生的處理器相匹配的系統(tǒng)軟件。
可以說Tensilica可配置處理器技術(shù)的核心,是在于可伸縮可擴(kuò)展的Xtensa處理器架構(gòu)和功能強(qiáng)大的自動(dòng)化生成工具—處理器生成器。
Xtensa架構(gòu)打破輸入/輸出瓶頸
為了提高I/O帶寬,可配置處理器必須克服總線瓶頸。 總線瓶頸問題是自Intel在1971年引入第一個(gè)商用微處理器4004以來就存在的問題。每個(gè)處理器都和系統(tǒng)總線上的其余設(shè)計(jì)部件進(jìn)行通信。總線上的流量由加載/存儲(chǔ)部件控制。由于總線的固有特性,在任何時(shí)候,只允許一小部分?jǐn)?shù)據(jù)在總線上和處理器進(jìn)行通信。另外,加載/存儲(chǔ)單元和處理器內(nèi)部執(zhí)行部件以及處理器局部存儲(chǔ)器通過類似有限的總線進(jìn)行通信。這種單一的、一次只能一個(gè)方向的處理器總線特性嚴(yán)重限制了微處理器的系統(tǒng)吞吐量。
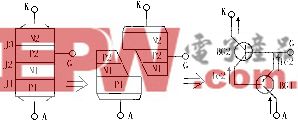
為了克服處理器總線所固有的局限性,Tensilica在Xtensa處理器中增加了另一個(gè)特性來永遠(yuǎn)消除總線瓶頸問題。這種新的特性稱為TIE(Tensilica指令擴(kuò)展)端口和隊(duì)列技術(shù)。采樣TIE端口和隊(duì)列技術(shù),設(shè)計(jì)者可以定義多達(dá)1024個(gè)端口直接與 Xtensa處理器執(zhí)行部件相連接,如圖2所示。每個(gè)端口寬度可以達(dá)到1024位。這種技術(shù)的結(jié)果是可以使系統(tǒng)以350,000 Gbits/秒的速度與Xtensa處理器進(jìn)行信息交換。這可以充分滿足所有處理器的輸入/輸出帶寬需求和采用RTL技術(shù)設(shè)計(jì)的系統(tǒng)需求。
Xtensa架構(gòu)提高計(jì)算性能
隨著傳統(tǒng)微處理器總線瓶頸的解決,處理器工程師們將注意力集中到提高Xtensa 處理器的性能上,以便使得計(jì)算性能的提高可以和通過設(shè)置TIE端口和隊(duì)列來提高輸入/輸出帶寬相匹配。
自從1999年開始引入第一個(gè)可配置Xtensa處理器以來,片上系統(tǒng)SOC設(shè)計(jì)師已經(jīng)具備能力來自己定義新指令,定義的新指令基于多操作(例如加法運(yùn)算跟隨一個(gè)移位或者一個(gè)位選擇操作)技術(shù),多操作指令可以作為一條新的指令。將多個(gè)操作合并在一起成為一條新的機(jī)器指令,該技術(shù)稱為操作數(shù)融合。操作數(shù)融合技術(shù)可以有效提高微處理器的計(jì)算性能。另外,片上系統(tǒng)SOC設(shè)計(jì)者可以在Xtensa處理器版本中添加SIMD(單指令、多數(shù)據(jù))指令。 單指令流多數(shù)據(jù)流SIMD指令可以同時(shí)對(duì)多個(gè)數(shù)據(jù)元素執(zhí)行相同的操作,該技術(shù)也可以顯著提高微處理器的計(jì)算性能。
然而,操作數(shù)融合和單指令流多數(shù)據(jù)流SIMD指令仍然只是微處理器的特征,每次只能發(fā)射一條指令。為更有效提高系統(tǒng)性能,設(shè)計(jì)人員決定在Xtensa處理器核中增加每個(gè)時(shí)鐘周期發(fā)射多條指令的能力。
從歷史的觀點(diǎn)來看,處理器設(shè)計(jì)人員可以通過兩種方法來實(shí)現(xiàn)微處理器具備每個(gè)時(shí)鐘周期可以發(fā)射多條指令的能力。其一為超標(biāo)量設(shè)計(jì)技術(shù),該技術(shù)通過復(fù)制處理器整個(gè)執(zhí)行部件來保證指令譯碼和發(fā)射部件在每個(gè)時(shí)鐘周期可以發(fā)射多條指令。采用這種方法,處理器硬件必須在應(yīng)用程序代碼中找到軟件固有的指令級(jí)并行性。 該技術(shù)的缺點(diǎn)是超標(biāo)量處理器用于完全復(fù)制處理器執(zhí)行部件的硬件開銷大,而且程序代碼中缺少指令級(jí)并行性。盡管4路超標(biāo)量處理器設(shè)計(jì)時(shí)可以在每個(gè)時(shí)鐘周期發(fā)射4個(gè)操作, 但是實(shí)際上從通用程序代碼中抽取的平均指令級(jí)并行性通常低于兩個(gè)操作。
第二種方法是采樣稱為超長指令字VLIW的技術(shù)來保證處理器每個(gè)時(shí)鐘周期發(fā)射多個(gè)操作。該方法采用一個(gè)非常長的指令字來對(duì)多個(gè)操作進(jìn)行編碼,有時(shí)每個(gè)指令字可以達(dá)到幾百位,多個(gè)操作可以同時(shí)發(fā)射到VLIW處理器的多個(gè)執(zhí)行部件。VLIW處理器的編譯器負(fù)責(zé)找出應(yīng)用程序代碼中的指令級(jí)并行性,VLIW處理器編譯器通常具有比較高的能力來識(shí)別程序中的并行性,因?yàn)榫幾g器掃描指令的窗口范圍比超標(biāo)量處理器要大,而超標(biāo)量處理器是采用指令譯碼和發(fā)射部件來對(duì)指令代碼的并行性進(jìn)行調(diào)度。VLIW技術(shù)從處理器硬件開銷的角度來說是非常有效的,然而VLIW處理器會(huì)造成指令代碼的劇烈膨脹(故需要更大的存儲(chǔ)器),因?yàn)槊織lVLIW指令字都非常長,而且VLIW編譯器經(jīng)常不能找到足夠的目標(biāo)程序代碼中的指令級(jí)并行性來保證處理器中的每個(gè)執(zhí)行部件都保持忙碌狀態(tài)。因此,VLIW處理器由于帶有與代碼相關(guān)的特性以及會(huì)耗盡片上的指令存儲(chǔ)器,故對(duì)深度嵌入式應(yīng)用的處理器而言也不是一個(gè)理想的選擇。
因此,處理器設(shè)計(jì)人員開發(fā)了一種變種VLIW結(jié)構(gòu),稱為可變長度指令擴(kuò)展FLIX技術(shù),用于Xtensa處理器。和VLIW指令一樣,F(xiàn)LIX指令可以將多個(gè)獨(dú)立的指令操作進(jìn)行編碼,變成一個(gè)FLIX指令字,該指令字寬度為32位或者64位,如圖3所示。和所有設(shè)計(jì)人員定義的TIE指令一樣,F(xiàn)LIX指令均是可選擇的,并且它們可以和Xtensa處理器現(xiàn)有的16和24位指令自由地混合在一起。因此,采用FLIX指令就避免了代碼膨脹問題,同時(shí)應(yīng)用程序代碼執(zhí)行速度更快,而不是使得程序代碼變得很長。
由于提高了輸入/輸出帶寬和計(jì)算性能,因此基于Xtensa 處理器的片上系統(tǒng)SOC設(shè)計(jì)通常可以以比基于固定指令集體系結(jié)構(gòu)ISA的處理器更低的時(shí)鐘頻率進(jìn)行運(yùn)行,這些低頻的時(shí)鐘頻率可以保證系統(tǒng)有更低的SOC系統(tǒng)功耗。然而,Xtensa處理器還可以通過擴(kuò)展的內(nèi)部時(shí)鐘門控技術(shù)來保證系統(tǒng)有更低的系統(tǒng)功耗,時(shí)鐘門控技術(shù)是由TIE指令進(jìn)行自定義擴(kuò)展的。







評(píng)論