地平線與英偉達工具鏈 PTQ 工具功能參數對比與實操

在閱讀本文之前,希望大家對 PTQ(Post-Training Quantization) 訓練后量化有一定的了解~
地平線 OpenExplorer 和 NVIDIA TensorRT 是兩家公司為適配自己的硬件而開發的算法工具鏈,它們各自具有獨特的特點和優勢。分開看的時候,網上有很多資料,但卻沒找到將他們放在一起對比的文章,本文從 PTQ 通路進行對比介紹。
OpenExplorer 中文名為天工開物,是地平線發布的算法開發平臺,主要包括模型編譯優化工具集、算法倉庫和應用開發 SDK 三大功能模塊。
TensorRT 是 NVIDIA 高性能深度學習的推理 SDK,包含深度學習推理優化器和運行時環境,可加速深度學習推理應用。利用 Pytorch、TensorFlow 等 DL 框架訓練好的模型,通過模型轉換編譯生成可以在各家硬件上運行的格式(TensorRT xxx.engine/xxx.trt 或地平線 xxx.hbm/xxx.bin),提升這個模型在各家硬件(英偉達 GPU、地平線 BPU)上運行的速度。
為了讓深度學習模型高效的在自家硬件上運行起來,他們都會做很多優化,包括但不限于 量化、數據壓縮、算子替換、算子拆分、算子融合等等優化措施,下面以兩家 show 出來的算子融合為例來看一下:
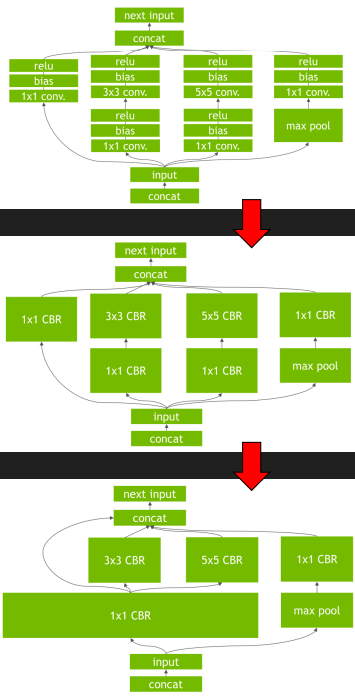
地平線宣傳材料中的圖片
量化方案:兩家都是對稱均勻量化,weight 是 per channel,feature 為 per tensor,地平線在有限條件下支持 feature per channel 量化
TensorRT 在進行 PTQ 量化(默認進行 fp32 不量化) 時,會在優化網絡的時候嘗試 int8 精度,假設某一層在 int8 精度下速度優于默認精度(fp32),則優先使用 int8。支持的數據類型與精度:https://docs.nvidia.com/deeplearning/tensorrt/support-matrix/index.html#layers-precision-matrix,對應的 onnx 算子:https://github.com/onnx/onnx-tensorrt/blob/main/docs/operators.md
地平線 OpenExplorer 默認使用 int8 量化,部分節點 BPU 支持 int16、int32,可以通過 node_info、run_on_bpu、run_on_cpu 參數控制量化精度以及運行的器件。
硬件相關:
TensorRT 的核心在于對模型算子的優化(算子合并、量化、利用 GPU 特性選擇特定核函數等策略),通過 tensorRT 能夠在 NVIDIA 系列 GPU 上獲得最好的性能,因此 tensorRT 的模型,需要在目標 GPU 上實際運行的方式選擇最優算法和配置,也就是說 tensorRT 生成的模型只能在特定條件下運行(編譯的 trt 版本、cuda 版本、編譯時的 GPU 型號),不同硬件之間的優化是不能共享的。但是從 tensorrt8.6 開始,–hardwareCompatibilityLevel 參數可以允許用戶在不同的架構上構建和運行模型,可能會帶來一些性能損失(視情況而定,5%左右,若某個大的優化只支持特定架構,性能損失會比較大);
OpenExplorer 進行 PTQ 量化時需要指定參數 march,指定產出混合異構模型需要支持的平臺架構,針對不同硬件,地平線提供的 OpenExplorer 是不同的,當然,本質上用到的幾個 whl 包是相同的。
NVIDIA
trtexec 工具提供的參數總體上可以分為:Model Options、Build Options、Inference Options、Reporting Options、System Options,最常用到的是前三個;
Horizon 征程 5
hb_mapper 工具提供的參數總體上可以分為:模型參數組、輸入信息參數組、校準參數組、編譯參數組、自定義算子參數組;
hrt_model_exec 工具提供模型信息查看、模型推理、模型性能評測三組參數;
Horizon 征程 6
hb_compile 等效于 hb_mapper 工具,新增了一些功能參數,用法上稍有不同
同樣使用 hrt_model_exec 工具 可以粗暴理解為:NVIDIA trtexec = Horizon J5 hb_mapper/J6 hb_compile + hrt_model_exec 本文將以 NVIDIA trtexec 工具(TensorRT-8.6.1)為核心,看看地平線 J5 OpenExplorer1.1.68 和 J6 OpenExplorer3.0.17 是如何提供與 trtexec 工具類似功能的。
trtexec 工具常用參數與 J5 hb_mapper/J6 hb_compile 工具對比
2.1.1 Model Options--onnx=<file> ONNX model # 指定 onnx model 的路徑
J5 hb_mapper: –model
J6 hb_compile:–model NVIDIA 支持 ONNX、Caffe、UFF,Horizon 支持 ONNX、Caffe,但均主流支持 ONNX,本文僅介紹 ONNX 相關內容
--minShapes=spec Build with dynamic shapes using a profile with the min shapes provided # 指定動態輸入形狀的范圍最小值
--optShapes=spec Build with dynamic shapes using a profile with the opt shapes provided # 指定動態輸入形狀的范圍常見值
--maxShapes=spec Build with dynamic shapes using a profile with the max shapes provided # 指定動態輸入形狀的范圍最大值
動態shape時,三個參數均必須配置,可以配置為一樣的
Example
--minShapes=input0:1x3x224x224
--optShapes=input0:1x3x224x224
--maxShapes=input0:16x3x224x224
多輸入時 spec:
input0:1x3x256x256,input1:1x3x128x128
征程 5 不支持動態 shape
征程 6 支持動態 shape,hb_compile 對應參數:待完善
# 輸入/輸出 數據精度和排布 --inputIOFormats=spec Type and format of each of the input tensors (default = all inputs in fp32:chw) --outputIOFormats=spec Type and format of each of the output tensors (default = all outputs in fp32:chw) # 精度可選:fp32、fp16、int32、int8 # 排布可選chw、hwc、chw16等 # Example --inputIOFormats=fp32:chw,fp32:chw # 兩個輸入 -outputIOFormats=fp16:chw,fp16:chw # 兩個輸出
J5 hb_mapper 相關參數有:
node_info # 配置節點輸入/輸出精度
input_type_rt # 板端模型輸入數據格式 nv12/rgb/featuremap 等
input_layout_rt # 板端輸入數據排布 NCHW/NHWC
輸出排布和 onnx 保持一致
input_type_train # 原始浮點模型的輸入數據類型 rgb/bgr 等
input_layout_train # 原始浮點模型的輸入數據排布 NCHW/NHWC
J6 hb_compile 相比于 J5 hb_mapper 的差異:
取消 input_layout_rt,板端輸入 layout 與原始浮點輸入數據排布相同
增加 quant_config 參數,支持對模型算子計算精度進行精細化配置
NVIDIA 的 tensor core 和地平線的 BPU core 都是 HWC 排布的,HWC 數據排布是為了編譯優化模型性能,雖然 CHW 和 HWC 排布均支持,但內部會進行轉換。 針對網絡輸入/輸出數據排布,允許用戶進行一些控制
--workspace=N # Set workspace size in MiB,可融進memPoolSize參數中
--memPoolSize=poolspec # Specify the size constraints of the designated memory pool(s) in MiB.
Example: --memPoolSize=workspace:1024.5,dlaSRAM:256
J5 hb_mapper 以及 J6 hb_compile 不需要配置類似參數
--profilingVerbosity=mode # Specify profiling verbosity. mode ::= layer_names_only|detailed|none (default = layer_names_only), 打印信息的詳細程度
Example: --profilingVerbosity=detailed
# 構建期間保留更多逐層信息
類似于 hb_mapper/hb_compile 中 advice 和 debug 參數
--refit # 標記生成的這個engine是refittable,即可以指定稍后更新其權重
hb_mapper 與 hb_compile 中無相關參數
允許用戶在運行時重新適配(refit)TensorRT 引擎的權重。對于需要在推理過程中動態更新模型權重的場景比較有用,例如在模型部署后需要根據新數據進行微調,強化學習中或在保留相同結構的同時重新訓練模型時,權重更新是使用 Refitter(C++、Python)接口執行的。
--sparsity=spec # Control sparsity (default = disabled),spec ::= "disable", "enable", "force" # disable = 不稀疏 # enable = 權重滿足稀疏規則才稀疏 # force = 強制稀疏
hb_mapper 與 hb_compile 中無對應參數,默認支持稀疏化
--noTF32 # 禁用TF32精度,(default is to enable tf32, in addition to fp32)
--fp16 # 使能fp16精度
--fp8 # 使能fp8精度
--int8 # 使能int8量化精度
J5 hb_mapper 不支持 TF32/fp16/fp8、可以通過 run_on_cpu 或 node_info 將節點配置運行在 CPU 上
J5 hb_mapper 支持 int8 和 int16 以及尾部 conv 節點 int32 量化,可以通過 node_info 或 run_on_bpu 參數進行配置
J6 hb_compile 通過 node_info 和 quant_config,支持對模型算子計算精度進行精細化配置
TF32 是英偉達提出的代替 FP32 的單精度浮點格式,TF32 采用與半精度( FP16 )數學相同的 10 位尾數位精度,這樣的精度水平遠高于 AI 工作負載的精度要求。同時, TF32 采用與 FP32 相同的 8 位指數位,能夠支持與其相同的數字范圍。 注意:NV 不論配置哪一項,fp32 都是會使用的。舉例:配置–fp16,網絡會使用 fp16+fp32;配置–int8 和–fp16,網絡會使用 int8+fp16+fp32
--best # fp32+fp16+int8 同時使用,找一個速度最快的
類似于 hb_mapper/hb_compile --fast-perf 功能,主要用于性能評測
--precisionConstraints=spec # 精度限制spec ::= "none" | "obey" | "prefer",(default = none),聯合下面兩個參數使用 # none = 無限制 # prefer = 優先滿足--layerPrecisions/--layerOutputTypes設置的精度限制,不滿足可回退到默認精度 # obey = 優先滿足--layerPrecisions/--layerOutputTypes設置的精度限制,不滿足報錯退出--layerPrecisions=spec # 控制per-layer的運算精度,僅在precisionConstraints為obey或prefer時有效. (default = none) # spec::= layerName:precision # precision::= "fp32"|"fp16"|"int32"|"int8"--layerOutputTypes=spec # 控制per-layer的輸出精度(類型),僅在precisionConstraints為obey或prefer時有效. (default = none) # spec::= layerName:type # type ::= "fp32"|"fp16"|"int32"|"int8"
類似于 J5 hb_mapper run_on_bpu、run_on_cpu、node_info 三個參數的功能,支持對模型算子計算精度進行精細化配置
類似于 J6 hb_compile node_info 和 quant_config,支持對模型算子計算精度進行精細化配置
--layerDeviceTypes=spec # 指定layer運行的器件 # spec ::= layerName:deviceType # deviceType ::= "GPU"|"DLA"
類似于 hb_mapper/hb_compile node_info、run_on_cpu、run_on_bpu 參數的功能
--calib # 指定int8校準緩存文件
類似于 hb_mapper/hb_compile 中如下參數:
cal_data_dir # 模型校準使用的樣本存放目錄
cal_data_type # 指定校準數據的數據存儲類型
下面針對校準數據進行一些更詳細的介紹:
trtexec 工具支持送入校準數據,在校準過程中,可以使用 --calib 選項來指定一個包含校準數據的文件。這個文件通常是一個緩存文件,包含了模型在特定輸入數據集上運行時的激活值的統計信息。
trtexec --onnx=model.onnx --int8 --calib=calibrationCacheFile.cache
trtexec 工具本身不提供校準數據的生成功能,需要事先通過其他方式(例如使用 TensorRT 的 API trt.IInt8EntropyCalibrator2)生成,包含了用于量化的統計信息。
NVIDIA 校準方法
IInt8EntropyCalibrator2 熵標定選擇張量的尺度因子來優化量子化張量的信息論內容,通常可以抑制分布中的異常值。目前推薦的熵校準器。默認情況下,校準發生在層融合之前,適用于 cnn 類型的網絡。
IInt8EntropyCalibrator 最原始的熵校準器,目前已不推薦使用。默認情況下,校準發生在層融合之后。
IInt8MinMaxCalibrator 該校準器使用整個激活分布范圍來確定比例因子。推薦用于 NLP 任務的模型中。默認情況下,校準發生在層融合之前。
IInt8LegacyCalibrator 該校準器需要用戶進行參數化,默認情況下校準發生在層融合之后,不推薦使用。
hb_mapper/hb_compile 工具支持送入校準數據(cal_data_dir),且在模型轉換編譯過程中選擇校準方法(cal_data_type)。與 NVDIA 不同的是,地平線校準數據僅是滿足模型輸入的圖像/數據文件,并不包含校準信息。
hb_mapper/hb_compile 工具本身不提供校準數據的生成功能,需要事先通過其他方式(例如使用 numpy)生成,不包含用于量化的統計信息。
地平線校準方法(校準發生在融合之后)
default default 是一個自動搜索的策略,會嘗試從系列校準量化參數中獲得一個相對效果較好的組合。
mix mix 是一個集成多種校準方法的搜索策略,能夠自動確定量化敏感節點,并在節點粒度上從不同的校準方法中挑選出最佳方法, 最終構建一個融合了多種校準方法優勢的組合校準方式。
kl KL 校準方法是借鑒了 TensorRT 提出的解決方案 , 使用 KL 熵值來遍歷每個量化層的數據分布,通過尋找最低的 KL 熵值,來確定閾值。 這種方法會導致較多的數據飽和和更小的數據量化粒度,在一些數據分布比較集中的模型中擁有著比 max 校準方法更好的效果。
max max 校準方法是在校準過程中,自動選擇量化層中的最大值作為閾值。 這種方法會導致數據量化粒度較大,但也會帶來比 KL 方法更少的飽和點數量,適用于那些數據分布比較離散的神經網絡模型。
--saveEngine # 保存序列化后的引擎文件,常見后綴名有 model.engine,model.trt
類似于 hb_mapper/hb_compile 中如下參數:
working_dir # 模型轉換輸出結果的存放目錄
output_model_file_prefix # 指定轉換產出物名稱前綴
--timingCacheFile=<file> # 保存/加載序列化的 global timing cache,減少構建時間
hb_mapper/hb_compile 默認啟用 cache 功能
通過時序緩存保存構建階段的 Layer 分析信息(特定于目標設備、CUDA 版本、TensorRT 版本),如果有其他層具備相同的輸入/輸出張量配合和層參數,則 TensorRT 構建器會跳過分析并重用緩存結果。
--builderOptimizationLevel # 構建時編譯優化等級,范圍是0~5,默認是3 # Higher level allows TensorRT to spend more building time for more optimization options. # 日志中默認時該參數顯示-1,其他整數也都可以配置,從官方手冊看,3比較穩定,性能也ok,4和5可能會構建失敗。
J5 hb_mapper 相關參數:optimize_level,范圍是 O0~O3,默認是 O0,耗時評測時需要配置為 O3
J6 hb_compile 相關參數:optimize_level,范圍是 O0~O2,默認是 O0,耗時評測時需要配置為 O2
下圖是 trtexec 關于優化等級對于構建 build 耗時與延遲 latency 耗時,hb_mapper/hb_compile 也是類似的情況。
--versionCompatible # 標記engine是軟件版本兼容的(相同OS、只支持顯式batch)
hb_mapper/hb_compile 無相關參數,默認兼容,跨多個版本時可能會存在不兼容的情況
--hardwareCompatibilityLevel=mode # 生成的engine模型可以兼容其他的GPU架構 (default = none) # 硬件兼容等級: mode ::= "none" | "ampere+" # none = no compatibility # ampere+ = compatible with Ampere and newer GPUs
hb_mapper/hb_compile 無相關參數,通過 march 指定架構即可,例如 征程 5 的 bayes、征程 6 的 nash-e/m 等
--maxAuxStreams=N # Set maximum number of auxiliary streams per inference stream that TRT is allowed to use to run kernels in parallel if the network contains ops that can run in parallel, with the cost of more memory usage. # 指定 TensorRT 在構建引擎時可以使用的最大輔助流(auxiliary streams)數量 # 輔助流是 CUDA 流的一種,用于在網絡中的不同層之間實現并行計算,特別是某些層可以獨立執行時,可能提高整體的推理性能。 # 默認根據網絡的結構和可用的 GPU 資源自動決定使用多少輔助流。 # 使用輔助流可能會增加 GPU 內存的使用,因為每個流都需要自己的內存副本。
hb_mapper/hb_compile 相關參數:
compile_mode # 編譯策略選擇
balance_factor # balance 編譯策略時的比例系數
2.2 模型推理(評測) Inference Optionsstream 是 CUDA 中為了實現多個 kernel 同時在 GPU 上運行,實現對 GPU 資源劃分,利用流水線的方法提高 GPU 吞吐率的機制。 并行化操作,地平線會在模型編譯時由編譯器完成。
trtexec 工具常用參數與 hrt_model_exec 工具(J5、J6 都有這個工具)對比
--loadEngine=<file> # 加載序列化后的引擎文件
hrt_model_exec 相關參數:
model_file # 模型文件路徑
model_name # 指定模型中某個模型的名稱,針對打包模型,用的較少
--shapes=spec # 針對動態shape,推理時使用的shape # 多輸入時示例 --shapes=input0:1x3x256x256, input1:1x3x128x128
征程 5 尚不支持動態 shape、征程 6 待呈現
--loadInputs=spec # 加載輸入數據,默認使用隨機值,主要用于debug engine推理結果是否和 pytorch 一致 # spec ::= name:file # 輸入的 binary 通過 numpy 導出即可
hrt_model_exec 相關參數:input_file
--iterations=N # 運行最少 N 次推理 ,default = 10
hrt_model_exec 相關參數:frame_count
--warmUp=N # 性能測試時執行 N 毫秒的 warmup,default = 200
hrt_model_exec 不支持 warmup,采用多幀推理獲取平均值的方式,可以很大程度上規避第一幀多出來的耗時
--duration=N # 最少運行 N 秒 (default = 3),配置為-1會一直執行
hrt_model_exec 相關參數:perf_time
--sleepTime=N # 推理前延遲 N 毫秒(between launch and compute),默認N=0 --idleTime=N # 兩次連續推理之間空閑 N 毫秒,默認N=0
hrt_model_exec 無相關參數
--infStreams=N # Instantiate實例化N個engine,測試多流執行時是否提速 (default = 1),以前是--streams
J5 hrt_model_exec 無相關參數,沒有多流的概念
在 CUDA 中,流(stream)是一種執行模型,它允許開發者將多個計算任務(如內核執行、內存拷貝等)組織成隊列,由 GPU 異步執行。使用多個流可以提高 GPU 利用率,因為當一個流的任務等待內存拷貝或其他非計算密集型操作時,GPU 可以切換到另一個流執行計算密集型任務。infStreams 與 CUDA 流的概念直接相關,它影響的是模型推理任務在 GPU 上的并行執行。 maxAuxStreams 是 TensorRT 內部用于優化網絡層執行的機制,它允許 TensorRT 在內部使用多個流來并行化可以并行化的層。 兩者之間的關系在于它們都旨在通過并行化策略來提高 GPU 上的推理性能,但它們作用的層面和具體實現方式不同。
--exposeDMA # Serialize DMA transfers to and from device (default = disabled) # 默認動態內存分配:TensorRT 會在執行推理時動態地分配和釋放內存,用于存儲中間層的激活值等。 # DMA:直接內存訪問,允許硬件設備直接在內存中讀寫數據,繞過CPU,從而減少CPU負載和提高數據傳輸效率。 # 在某些情況下,使用 DMA 可能會增加程序的復雜性,因為它需要正確管理內存的分配和釋放
hrt_model_exec 無相關參數
地平線 CPU 和 BPU 是共享內存的
--noDataTransfers # Disable DMA transfers to and from device (default = enabled) # 勿將數據傳入和傳出設備,用于什么場景呢? # 猜測:禁用數據在主機和設備之間的傳輸,方便分析模型計算部分耗時?沒有H2D/D2H(Host/Device)數據傳輸可能會存在GPU利用率
hrt_model_exec 無相關參數
--useManagedMemory # Use managed memory instead of separate host and device allocations (default = disabled). # 猜測:使用托管內存(Managed Memory),允許 CPU 和 GPU 同時訪問而不需要顯式的數據傳輸,提高數據共享的效率
hrt_model_exec 無相關參數
--useSpinWait # 主動同步 GPU 事件。 此選項可能會減少同步時間,但會增加 CPU 使用率和功率(default = disabled)
hrt_model_exec 無相關參數
啟用這個參數時,TensorRT 在等待 GPU 計算完成時使用自旋等待(spin wait)策略,而不是阻塞等待(block wait)。
阻塞等待:在默認情況下,當 TensorRT 引擎執行推理任務時,如果 GPU 計算尚未完成,它會掛起(阻塞)當前線程,直到 GPU 計算完成并返回結果。這種等待方式可能會導致線程在等待期間不執行任何操作,從而影響整體的 CPU 利用率和系統性能。
自旋等待:啟用 --useSpinWait 參數后,TensorRT 會采用自旋等待策略。在這種模式下,線程會循環檢查 GPU 計算是否完成,而不是掛起。自旋等待可以減少線程掛起和恢復的開銷,從而在某些情況下,例如 GPU 計算時間與 CPU 處理時間相比 較短的情況下。通過減少線程掛起的頻率,可以提高 CPU 的利用率,從而可能提升整體的系統性能。
GPU 計算時間不穩定或較短時,自旋等待可以減少線程上下文切換的開銷,并保持 CPU 核心的活躍狀態。然而,自旋等待也可能導致 CPU 資源的過度使用,特別是在 GPU 計算時間較長的情況下,因此需要根據具體的應用場景和硬件配置來權衡是否使用這個參數。
--threads # 啟用多線程以驅動具有獨立線程的引擎 or 加速refitting (default = disabled)
hrt_model_exec 相關參數:thread_num
"stream(流)"和"thread(線程)"是兩個不同的概念,用于處理并發和數據流的情況。
線程(Thread): 線程是計算機程序中執行的最小單位,也是進程的一部分。一個進程可以包含多個線程,它們共享進程的資源,如內存空間、文件句柄等。線程可以并行執行,使得程序能夠同時處理多個任務。線程之間可以共享數據,但也需要考慮同步和互斥問題,以避免競爭條件和數據損壞。
流(Stream): 流是一種數據傳輸的抽象概念,通常用于輸入和輸出操作。在計算機編程中,流用于處理數據的連續流動,如文件讀寫、網絡通信等。流可以是字節流(以字節為單位處理數據)或字符流(以字符為單位處理數據)。流的一個常見特性是按順序處理數據,不需要一次性將所有數據加載到內存中。 總之,線程是一種用于實現并發執行的機制,而流是一種用于處理數據傳輸的抽象概念。
--useCudaGraph # Use CUDA graph to capture engine execution and then launch inference (default = disabled)
hrt_model_exec 無相關參數
useCudaGraph 參數允許用戶指示 TensorRT 在執行推理時使用 CUDA 圖(CUDA Graph)。CUDA 圖是一種 CUDA 編程技術,它允許開發者創建一個或多個 CUDA 內核及其內存依賴關系的靜態表示,這可以提高執行效率和性能。 CUDA 圖的優勢
性能提升:通過使用 CUDA 圖,可以減少運行時的開銷,因為它們允許預編譯一組 CUDA 操作,從而減少每次執行操作時的啟動延遲。
重用性:一旦創建了 CUDA 圖,它可以被重用于多個推理請求,這使得它特別適合于高吞吐量和低延遲的應用場景。
并行化:CUDA 圖可以并行執行多個節點,這有助于提高 GPU 的利用率和整體的推理性能。 使用場景
高并發推理:在需要處理大量并發推理請求的場景中,使用 --useCudaGraph 可以提高處理速度和效率
--timeDeserialize # 測量序列化引擎文件(.engine)的反序列化時間
hrt_model_exec 會在終端中打印 加載 板端模型 的時間
反序列化時間:–timeDeserialize 參數會讓 trtexec 測量將序列化的 TensorRT 引擎文件加載到 GPU 內存中所需的時間。
性能分析:通過測量反序列化時間,開發者可以了解模型加載階段的性能瓶頸,并探索減少模型加載時間的方法。
--timeRefit # Time the amount of time it takes to refit the engine before inference.
hrt_model_exec 無相關參數
猜測:重新適配(refitting)是指在模型轉換為 TensorRT 引擎后,根據新的權重或校準數據更新引擎的過程,比如將模型的權重從一種精度轉換為另一種精度,或者根據新的校準數據調整量化參數。
--separateProfileRun # 控制性能分析和推理測試的執行方式,配置它時,二者會分開進行(兩次)
類似于 hb_mapper/hb_compile 中 debug 參數,debug 默認配置為 True,編譯后會在 html 靜態性能評估文件中增加逐層的信息打印,可以幫助分析性能瓶頸。該參數開啟后不會影響模型的推理性能,但會極少量地增加模型文件大小。
trtexec 使用該參數,一次用于收集性能分析數據的運行,另一次用于計算性能基準測試的運行,提高分析/測試的準確性。
--skipInference # 只構建engine,不推理engine進行性能測試(default = disabled),以前是--buildOnly
地平線 模型構建與模型推理/性能評測是分開的,無相關參數
--persistentCacheRatio # Set the persistentCacheLimit in ratio, 0.5 represent half of max persistent L2 size,默認是0
地平線無相關參數
2.3 報告選項 Reporting Options
緩存管理:–persistentCacheRatio 參數用于控制 TensorRT 引擎在執行推理時分配給持久化緩存的內存比例
性能優化:合理設置緩存比例可以提高模型的推理性能,尤其是在處理大型模型或復雜網絡結構時
內存使用:增加持久化緩存的比例可能會減少內存占用,但也可能導致緩存溢出
TensorRT 會自動管理緩存,因此手動設置–persistentCacheRatio 不是必須的。只有需要精細控制內存使用或優化性能時才會用到
--verbose # 使用詳細的日志輸出信息(default = false)
地平線無相關參數
日志中增加很多信息,類似于:[08/09/2024-17:18:51] [V] [TRT] Registered plugin creator - ::BatchedNMSDynamic_TRT version 1
--avgRuns=N # 指定在性能測試中連續執行推理的次數,以計算平均性能指標(default = 10)
類似于 hrt_model_exec 中 frame_count 參數
為了減少偶然因素對性能測試結果的影響,通過多次運行推理并取平均值來提供一個更加穩定和可靠的性能度量。
--percentile=P1,P2,P3,... # 指定在性能測試中報告的執行時間百分比,0<=P_i<=100 (default = 90,95,99%)
hrt_model_exec 中無相關參數
設置 --percentile=99,trtexec 將會報告第 99 百分位的執行時間,這意味著在 100 次推理中,有 99 次的執行時間會小于或等于報告的值,而只有 1 次的執行時間會大于這個值。故:0 representing max perf, and 100 representing min perf
--dumpRefit # Print the refittable layers and weights from a refittable engine
hrt_model_exec 中無相關參數
--dumpLayerInfo # 打印 engine 的每層信息v (default = disabled) --exportLayerInfo=<file> # 將 engine 的 layer 打印信息存儲下來,xxx.json (default = disabled) # Example: --exportLayerInfo=layer.json --profilingVerbosity=detailed
hb_mapper/hb_compile 默認會在日志中打印層的信息
--dumpProfile # 打印每一層的 profile 信息 (default = disabled) --exportProfile=<file> # 將 profile 打印信息存儲下來,xxx.json (default = disabled)
hb_mapper/hb_compile 默認開啟 debug 參數后,會在轉換編譯過程中生成 html 文件,其中有類似的層耗時信息
hrt_model_exec 工具中 profile_path 參數
--dumpOutput 將推理結果直接打印出來 (default = disabled) --dumpRawBindingsToFile 將 input/output tensor(s) of the last inference iteration to file(default = disabled) --exportOutput=<file> 將 ouput 打印信息存儲下來,xxx.json (default = disabled) --exportProfile=<file> 將 profile 打印信息存儲下來,xxx.json (default = disabled)
類似于 J5 hrt_model_exec 中 dump_intermediate、enable_dump、dump_format 等
--exportTimes=<file> # 將各個層的執行時間存儲下來 (default = disabled)
hrt_model_exec 無相關參數
--device=N # Select cuda device N (default = 0),選擇執行的GPU --useDLACore=N # Select DLA core N for layers that support DLA (default = none),使用較少
類似于 hrt_model_exec 中 core_id 參數
# 加載插件,實現自定義算子的編譯工作,區分動/靜態插件,替代以前的--plugins --staticPlugins Plugin library (.so) to load statically (can be specified multiple times) --dynamicPlugins Plugin library (.so) to load dynamically and may be serialized with the engine if they are included in --setPluginsToSerialize (can be specified multiple times) # 允許將插件序列化進engine中,結合--dynamicPlugins參數使用 --setPluginsToSerialize Plugin library (.so) to be serialized with the engine (can be specified multiple times)
類似于 J5 hb_mapper 中 custom_op_method、op_register_files、custom_op_dir 參數
J6 hb_compile 待確定
看到這兒,trtexec 大部分參數就介紹完成了,還有少量不常用到參數,例如–minTiming、–avgTiming=M、–tempdir、–tempfileControls、–useRuntime=runtime、–leanDLLPath=<file>、–excludeLeanRuntime、–ignoreParsedPluginLibs 未進行介紹,歡迎大家自行探索。
各家的工具都會針對自己的硬件或特性設計針對性的參數,只要滿足開發者需要的功能即可,例如地平線工具鏈的一些參數,有一些就沒介紹到。
這么多參數其實并不是都會用到,大家根據自己的需求選擇性使用即可。
3.實操演示3.1 onnx 模型生成import torch.nn as nn
import torch
import numpy as np
import onnxruntime
class MyNet(nn.Module):
def __init__(self, num_classes=10):
super(MyNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1), # input[3, 28, 28] output[32, 28, 28]
nn.BatchNorm2d(32),
nn.ReLU(inplace=True),
nn.Conv2d(32, 64, kernel_size=3, stride=2, padding=1), # output[64, 14, 14]
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2) # output[64, 7, 7]
)
self.fc = nn.Linear(64 * 7 * 7, num_classes)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, start_dim=1)
x = self.fc(x)
return x
# -----------------------------------#
# 導出靜態ONNX
# -----------------------------------#
def model_convert_static_onnx(model, dummy_input, output_path):
input_names = ["input1"] # 導出的ONNX模型輸入節點名稱
output_names = ["output1"] # 導出的ONNX模型輸出節點名稱
torch.onnx.export(
model,
dummy_input,
output_path,
verbose=False, # 如果指定為True,在導出的ONNX中會有詳細的導出過程信息description
opset_version=11, # J5目前僅支持為 10 or 11
input_names=input_names,
output_names=output_names,
)
# -------------------------------------------------------------------------#
# 導出動態ONNX
# dynamic_axes 參數中可以只指定輸入動態,因為輸出維度會根據模型的結構自動推出來。
# 一般場景,只做 batch 維度動態
# -------------------------------------------------------------------------#
def model_convert_dynamic_onnx(model, dummy_input, output_path):
input_names = ["input1"] # 導出的ONNX模型輸入節點名稱
output_names = ["output1"] # 導出的ONNX模型輸出節點名稱
torch.onnx.export(
model,
dummy_input,
output_path,
verbose=False, # 如果指定為True,在導出的ONNX中會有詳細的導出過程信息description
opset_version=11, # J5目前僅支持為 10 or 11
input_names=input_names,
output_names=output_names,
dynamic_axes={"input1": {0: "batch"}, "output1":{0: "batch"}}
)
if __name__ == '__main__':
torch.manual_seed(1)
model = MyNet()
# 將模型轉成 eval 模式
model.eval()
# 網絡輸入
input_shape = (28, 28)
dummy_input = torch.randn(1, 3, input_shape[0], input_shape[1])
# torch推理
with torch.no_grad():
torch_output = model(dummy_input)
print("torch_output:", torch_output)
# 導出靜態ONNX模型
output_static_path = './static.onnx'
model_convert_static_onnx(model, dummy_input, output_static_path)
print("model export static onnx finsh.")
static_sess = onnxruntime.InferenceSession(output_static_path)
static_output = static_sess.run(None, {"input1": dummy_input.numpy()})
print("static_output: ", static_output)上述代碼運行后,會生成一個 static.onnx,接下來就可以使用這個 onnx 啦。
3.2 性能評測實測實操的方向不同,使用的命令和腳本也會有差異,本文重點在對比兩家工具鏈的 PTQ 功能參數對比介紹上,因此只選擇一個性能評測方向進行實操演示。
英偉達 trtexec
構建用于性能評測的 engine,另外性能數據可以一起產出,腳本如下:
trtexec \ --onnx=static.onnx \ --saveEngine=static.engine \ --useCudaGraph \ --noDataTransfers \ --useSpinWait \ --infStreams=8 \ --maxAuxStreams=8 \ --builderOptimizationLevel=5 \ --threads \ --best \ --verbose \ --profilingVerbosity=detailed \ --dumpProfile \ --dumpLayerInfo \ --separateProfileRun \ --avgRuns=100 \ --iterations=1000 >1.log 2>&1
會產出 engine 文件:resnet18.engine,以及一些日志,例如:
[08/09/2024-14:11:17] [I] === Performance summary === [08/09/2024-14:11:17] [I] Throughput: 21241.3 qps [08/09/2024-14:11:17] [I] Latency: min = 0.0292969 ms, max = 4.11438 ms, mean = 0.036173 ms, median = 0.03479 ms, percentile(90%) = 0.0389404 ms, percentile(95%) = 0.0422974 ms, percentile(99%) = 0.0679932 ms [08/09/2024-14:11:17] [I] Enqueue Time: min = 0.0141602 ms, max = 4.099 ms, mean = 0.0175454 ms, median = 0.017334 ms, percentile(90%) = 0.0184326 ms, percentile(95%) = 0.0209961 ms, percentile(99%) = 0.0261841 ms [08/09/2024-14:11:17] [I] H2D Latency: min = 0.00366211 ms, max = 4.05176 ms, mean = 0.0064459 ms, median = 0.00561523 ms, percentile(90%) = 0.00682068 ms, percentile(95%) = 0.00720215 ms, percentile(99%) = 0.0361328 ms [08/09/2024-14:11:17] [I] GPU Compute Time: min = 0.0214844 ms, max = 4.10327 ms, mean = 0.024971 ms, median = 0.0244141 ms, percentile(90%) = 0.0274658 ms, percentile(95%) = 0.0285645 ms, percentile(99%) = 0.0317383 ms [08/09/2024-14:11:17] [I] D2H Latency: min = 0.00268555 ms, max = 0.0428467 ms, mean = 0.0047562 ms, median = 0.00415039 ms, percentile(90%) = 0.0065918 ms, percentile(95%) = 0.00695801 ms, percentile(99%) = 0.0113525 ms [08/09/2024-14:11:17] [I] Total Host Walltime: 3.00005 s [08/09/2024-14:11:17] [I] Total GPU Compute Time: 1.59128 s
地平線 hb_compile 與 hrt_model_exec
轉換編譯用于性能評測的 hbm
hb_compile --fast-perf --model static.onnx --march nash-m
會生成 static.hbm,以及一些日志
在板端評測性能數據
hrt_model_exec perf --model_file static.hbm --thread_num 8 --frame_count 400 --internal_use
*博客內容為網友個人發布,僅代表博主個人觀點,如有侵權請聯系工作人員刪除。





