如何實現AI的矢量數據庫

推薦:使用NSDT場景編輯器助你快速搭建3D應用場景
然而,人工智能模型有點像美食廚師。他們可以創造奇跡,但他們需要優質的成分。人工智能模型在大多數輸入上都做得很好,但如果它們以最優化的格式接收輸入,它們就會真正發光。這就是矢量數據庫的重點。
在本文的過程中,我們將深入探討什么是矢量數據庫,為什么它們在人工智能世界中變得越來越重要,然后我們將查看實現矢量數據庫的分步指南。
跳躍前進:
什么是矢量數據庫?
為什么需要矢量數據庫?
實現矢量數據庫:分步指南
先決條件
設置Weaviate項目
創建我們的節點.js項目
設置我們的矢量數據庫
設置客戶端
遷移數據
添加文檔
刪除文檔
向數據庫添加查詢函數
結合向量嵌入和 AI
人工智能模型設置
查詢我們的數據
測試我們的查詢
在我們開始探索矢量數據庫之前,了解在編程和機器學習的上下文中什么是矢量非常重要。
在編程中,向量本質上是一個一維數字數組。如果您曾經編寫過涉及 3D 圖形或機器學習算法的代碼,那么您很可能使用過向量。
const vector4_example = [0.5, 1.5, 6.0, 3.4]
它們只是數字數組,通常是浮點數,我們用它們的維度來指代。例如,a 是浮點數的三元素數組,a 是浮點數的四元素數組。就這么簡單!vector3vector4
但向量不僅僅是數字數組。在機器學習的背景下,向量在高維空間中表示和操作數據方面發揮著關鍵作用。這使我們能夠執行驅動AI模型的復雜操作和計算。
現在我們已經掌握了向量,讓我們把注意力轉向向量數據庫。
乍一看,你可能會想,“嘿,既然向量只是數字數組,我們不能使用常規數據庫來存儲它們嗎?好吧,從技術上講,你可以。但這就是事情變得有趣的地方。
矢量數據庫是一種特殊類型的數據庫,針對存儲和執行對大量矢量數據的操作進行了優化。因此,雖然您的常規數據庫確實可以存儲數組,但矢量數據庫更進一步,提供了專門的工具和操作來處理矢量。
在下一節中,我們將討論為什么矢量數據庫是必要的,以及它們帶來的優勢。所以堅持下去,因為事情會變得更加有趣!
為什么需要矢量數據庫?現在我們已經對什么是矢量數據庫有了深入的了解,讓我們深入了解為什么它們在人工智能和機器學習領域如此必要。
這里的關鍵詞是性能。矢量數據庫通常每次查詢處理數億個向量,這種性能比傳統數據庫在處理向量時能夠達到的性能要快得多。
那么,是什么讓矢量數據庫如此快速高效呢?讓我們來看看使它們與眾不同的一些關鍵功能。
復雜的數學運算向量數據庫旨在對向量執行復雜的數學運算,例如過濾和定位“附近”向量。這些操作在機器學習環境中至關重要,其中模型通常需要在高維空間中找到彼此接近的向量。
例如,一種常見的數據分析技術余弦相似性通常用于測量兩個向量的相似程度。矢量數據庫擅長這些類型的計算。
專用矢量索引與組織良好的庫一樣,數據庫需要一個良好的索引系統來快速檢索請求的數據。矢量數據庫提供專門的矢量索引,與傳統數據庫相比,檢索數據的速度更快、更確定(與隨機數據庫相反)。
借助這些索引,向量數據庫可以快速定位 AI 模型所需的向量并快速生成結果。
緊湊的存儲在大數據的世界里,存儲空間是一種寶貴的商品。矢量數據庫在這里也大放異彩,以使其更緊湊的方式存儲矢量。壓縮和量化向量等技術用于在內存中保留盡可能多的數據,從而進一步減少負載和查詢延遲。
分片在處理大量數據時,將數據分布在多臺機器上可能是有益的,這個過程稱為分片。許多數據庫都可以執行此操作,但 SQL 數據庫尤其需要付出更多努力才能橫向擴展。另一方面,矢量數據庫通常在其架構中內置分片,使它們能夠輕松處理大量數據。
簡而言之,雖然傳統數據庫可以存儲和對向量執行操作,但它們并未針對任務進行優化。另一方面,矢量數據庫正是為此目的而構建的。它們提供了處理大量矢量數據所需的速度、效率和專用工具,使其成為人工智能和機器學習領域必不可少的工具。
在下一節中,我們將向量數據庫與其他類型的數據庫進行比較,并解釋它們如何適應更大的數據庫生態系統。我們才剛剛開始!
實現矢量數據庫:分步指南出于本指南的目的,我們將使用 Weaviate(一種流行的矢量數據庫服務)來實現一個簡單的矢量數據庫,您可以基于該數據庫為任何用例進行構建。
您可以在此處克隆初學者模板并運行以進行設置。npm install
先決條件先前的JS知識將有所幫助:本教程中編寫的所有代碼都將使用JavaScript,我們也將使用Weaviate JavaScript SDK。
Node 和 npm:我們將在服務器上的 JavaScript 環境中工作。
OpenAI API密鑰:我們將使用他們的嵌入模型將我們的數據轉換為嵌入以存儲在我們的數據庫中
Weaviate帳戶:我們將使用他們的托管數據庫服務;您可以在此處獲得免費帳戶
創建帳戶后,您需要通過Weaviate儀表板設置項目。轉到 WCS 控制臺,然后單擊創建集群:

選擇“免費沙盒”層并提供群集名稱。當它要求您啟用身份驗證時,請選擇“是”:
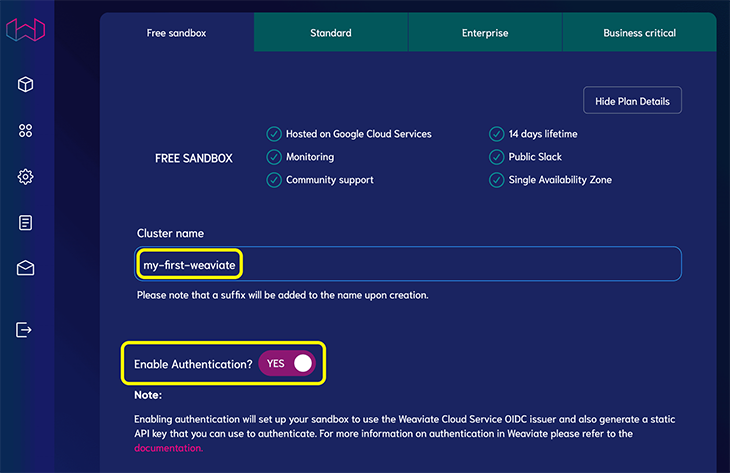
單擊創建。幾分鐘后,您應該會在完成后看到一個復選標記。
單擊“詳細信息”以查看群集詳細信息,因為我們將在下一部分用到它們。其中包括:
一個編織的****
身份驗證詳細信息(Weaviate API 密鑰;單擊密鑰圖標以顯示)
有了先決條件,我們可以創建向量數據庫并查詢它。要繼續操作,您需要一個新的 Node 項目;您可以在此處克隆 GitHub 上的模板,其中包括入門所需的一切。
或者,您可以通過運行以下命令創建一個:
mkdir weaviate-vector-database && cd weaviate-vector-database
npm init -y && npm install dotenv openai weaviate-ts-client
mkdir src
編輯文件并添加腳本,如下所示:package.jsonstart
// ...rest of package.json
"scripts": {
"start": "node src/index.js"
},
// ...rest of package.json
創建一個文件來存儲敏感信息,如 API 密鑰。編寫命令并在代碼編輯器中打開新創建的文件,然后粘貼以下內容并確保將占位符替換為實際值:.envtouch .env.env
// .env
OPENAI_KEY="<OPENAI_API_KEY>"
WEAVIATE_API_KEY="<WEAVIATE_API_KEY>"
WEAVIATE_URL="<WEAVIATE_URL>"
DATA_CLASSNAME="Document"
項目設置完成后,我們可以添加一些代碼來設置和使用我們的矢量數據庫。讓我們快速總結一下我們將要實現的內容:
幫助程序函數,它:
連接到我們的數據庫
批量矢量化和上傳文檔
查詢最相似的項目
一個 main 函數,它使用上面的輔助函數一次性上傳文檔和查詢數據庫
話雖如此,讓我們創建第一個文件來存儲數據庫連接和幫助程序函數。通過運行創建一個新文件,讓我們開始填寫它:touch src/database.js
// src/database.js
import weaviate, { ApiKey } from "weaviate-ts-client";
import { config } from "dotenv";
config();
async function setupClient() {
let client;
try {
client = weaviate.client({
scheme: "https",
host: process.env.WEAVIATE_URL,
apiKey: new ApiKey(process.env.WEAVIATE_API_KEY),
headers: { "X-OpenAI-Api-Key": process.env.OPENAI_API_KEY },
});
} catch (err) {
console.error("error >>>", err.message);
}
return client;
}
// ... code continues below
讓我們分解一下這里發生的事情。首先,我們導入必要的軟件包,Weaviate客戶端和dotenv配置。dotenv 是一個將環境變量從文件加載到 .Weaviate和OpenAI密鑰和URL通常存儲在環境變量中,以保持機密性并遠離代碼庫。.envprocess.env
以下是函數中發生的情況:setupClient()
我們初始化了一個變量client
我們有一個塊,用于設置與 Weaviate 服務器的連接。如果在此過程中發生任何錯誤,我們會將錯誤消息打印到控制臺try…catch
在塊內,我們使用該方法創建一個新的 Weaviate 客戶端。、 和 參數取自我們設置的環境變量tryweaviate.client()schemehostapiKey
最后,我們傳入OpenAI的標頭,因為我們將使用OpenAI的Ada模型來矢量化我們的數據。
設置客戶端后,讓我們使用一些虛擬數據、虛構生物、地點和事件的集合來運行遷移。稍后,我們將針對此數據查詢 GPT-3。
如果您沒有克隆初學者模板,請按照以下步驟操作:
通過運行創建新文件touch src/data.js
從此處復制文件的內容并將其粘貼到
花一些時間瀏覽 中的數據。然后,在文件頂部添加新導入:src/data.jssrc/database.js
// ...other imports
import { FAKE_XORDIA_HISTORY } from "./data";
在函數下方,添加一個新函數,如下所示:setupClient
async function migrate(shouldDeleteAllDocuments = false) {
try {
const classObj = {
class: process.env.DATA_CLASSNAME,
vectorizer: "text2vec-openai",
moduleConfig: {
"text2vec-openai": {
model: "ada",
modelVersion: "002",
type: "text",
},
},
};
const client = await setupClient();
try {
const schema = await client.schema
.classCreator()
.withClass(classObj)
.do();
console.info("created schema >>>", schema);
} catch (err) {
console.error("schema already exists");
}
if (!FAKE_XORDIA_HISTORY.length) {
console.error(`Data is empty`);
process.exit(1);
}
if (shouldDeleteAllDocuments) {
console.info(`Deleting all documents`);
await deleteAllDocuments();
}
console.info(`Inserting documents`);
await addDocuments(FAKE_XORDIA_HISTORY);} catch (err) {
console.error("error >>>", err.message);
}
}
再一次,讓我們分解一下這里發生的事情。
該函數接受單個參數,該參數確定在遷移數據時是否清除數據庫。migrateshouldDeleteAllDocuments
在我們的塊中,我們創建一個名為 .此對象表示 Weaviate 中類的架構(確保在文件中添加 a),該類使用矢量化器。這決定了文本文檔在數據庫中的配置和表示方式,并告訴Weaviate使用OpenAI的“ada”模型對我們的數據進行矢量化。try…catchclassObjCLASS_NAME.envtext2vec-openai
然后,我們使用方法鏈創建模式。這會向 Weaviate 服務器發送請求,以創建 中定義的文檔類。成功創建架構后,我們將模式對象記錄到控制臺,并顯示消息 .現在,錯誤通過記錄到控制臺的簡單消息進行處理。client.schema.classCreator().withClass(classObj).do()classObjcreated schema >>>
我們可以檢查要遷移的虛擬數據的長度。如果為空,則代碼在此處結束。我們可以使用函數(稍后會添加)清除數據庫,如果 是 .deleteAllDocumentsshouldDeleteAllDocumentstrue
最后,使用一個函數(我們接下來將添加),我們上傳所有要矢量化并存儲在 Weaviate 中的條目。addDocuments
添加文檔我們可以繼續矢量化和上傳我們的文本文檔。這實際上是一個兩步過程,其中:
原始文本字符串使用 OpenAI Ada 模型轉換為矢量
轉換后的載體將上傳到我們的 Weaviate 數據庫
值得慶幸的是,這些是由我們使用的Weaviate SDK自動處理的。讓我們繼續創建函數來執行此操作。打開同一文件并粘貼以下內容:src/database.js
// code continues from above
const addDocuments = async (data = []) => {
const client = await setupClient();
let batcher = client.batch.objectsBatcher();
let counter = 0;
const batchSize = 100;
for (const document of data) {
const obj = {
class: process.env.DATA_CLASSNAME,
properties: { ...document },
};
batcher = batcher.withObject(obj);
if (counter++ == batchSize) {
await batcher.do();
counter = 0;
batcher = client.batch.objectsBatcher();
}}
const res = await batcher.do();
return res;
};
// ... code continues below
和以前一樣,讓我們分解一下這里發生的事情。
首先,我們調用前面定義的函數來設置并獲取 Weaviate 客戶端實例setupClient()
我們使用初始化一個批處理器,用于收集文檔并一次性將它們上傳到Weaviate,使過程更高效client.batch.objectsBatcher()
我們還定義了一個計數器變量和一個變量,并將其設置為 100。計數器跟蹤已添加到當前批次的文檔數,并定義每個批次中應包含的文檔數batchSizebatchSize
然后,我們遍歷數據數組中的每個文檔:
對于每個文檔,我們創建一個對象,該對象以Weaviate期望的格式表示文檔,以便可以將其擴展到該對象的屬性中
然后,我們使用batcher.withObject(obj)
如果計數器等于批大小(意味著批已滿),我們將批上傳到 Weaviate,將計數器重置為 ,并為下一批文檔創建一個新的批處理器batcher.do()0
處理完所有文檔并將其添加到批處理后,如果還有剩余的批處理尚未上載(因為它未到達 ),則可以使用 上載剩余的批處理。batchSizebatcher.do()
此處的最后一步發生在函數返回上次調用的響應時。此響應將包含有關上傳的詳細信息,例如上傳是否成功以及發生的任何錯誤。batcher.do()
從本質上講,該函數通過將大量文檔分組為可管理的批次來幫助我們有效地將大量文檔上傳到我們的 Weaviate 實例。addDocuments()
刪除文檔讓我們添加函數中使用的代碼。在函數下方,添加以下代碼:deleteAllDocumentsmigrateaddDocuments
// code continues from above
async function deleteAllDocuments() {
const client = await setupClient();
const documents = await client.graphql
.get()
.withClassName(process.env.DATA_CLASSNAME)
.withFields("_additional { id }")
.do();
for (const document of documents.data.Get[process.env.DATA_CLASSNAME]) {
await client.data
.deleter()
.withClassName(process.env.DATA_CLASSNAME)
.withId(document._additional.id)
.do();
}
}
// ... code continues below
這個函數相對簡單。
我們使用類名為setupClientidDocument
然后使用循環,我們使用其刪除每個文檔for...ofid
這種方法之所以有效,是因為我們擁有少量數據。對于較大的數據庫,需要一種技術來刪除所有文檔,因為每個請求的限制是一次只有 200 個條目。batching
向數據庫添加查詢函數現在我們有了將數據上傳到數據庫的方法,讓我們添加一個函數來查詢數據庫。在本例中,我們將執行“最近鄰搜索”以查找與我們的查詢相似的文檔。
在同一文件中,添加以下內容:src/database.js
// code continues from above
async function nearTextQuery({
concepts = [""],
fields = "text category",
limit = 1,
}) {
const client = await setupClient();
const res = await client.graphql
.get()
.withClassName("Document")
.withFields(fields)
.withNearText({ concepts })
.withLimit(limit)
.do();
return res.data.Get[process.env.DATA_CLASSNAME];
}
export { migrate, addDocuments, deleteAllDocuments, nearTextQuery };
同樣,讓我們對這里發生的事情進行細分:
nearTextQuery()是一個接受對象作為參數的異步函數。此對象可以包含三個屬性:
概念:表示我們正在搜索的術語的字符串數組
字段:一個字符串,表示我們希望在搜索結果中返回的字段。在本例中,我們從 和 字段請求textcategory
限制:我們希望從搜索查詢中返回的最大結果數
我們調用函數來獲取 Weaviate 客戶端實例setupClient()
我們使用一系列方法構建 GraphQL 查詢:
client.graphql.get():初始化 GraphQL 查詢
.withClassName("Document"):我們指定要在“文檔”對象中搜索
.withFields(fields):我們指定要在結果中返回哪些字段
.withNearText({ concepts }):這就是魔術發生的地方!我們指定了 Weaviate 將用于搜索語義相似的文檔的概念
.withLimit(limit):我們指定要返回的最大結果數
最后,執行查詢.do()
來自查詢的響應存儲在變量中,然后在下一行返回res
最后,我們導出此處定義的所有函數以在其他地方使用
簡而言之,該函數幫助我們根據提供的術語在 Weaviate 實例中搜索語義相似的文檔。nearTextQuery()
讓我們遷移數據,以便在下一節中查詢它。打開終端并運行 。npm run start"migrate"
結合向量嵌入和 AI像 GPT-3 和 ChatGPT 這樣的大型語言模型旨在處理輸入并生成有用的輸出,這是一項需要了解單詞和短語之間復雜含義和關系的任務。
他們通過將單詞、句子甚至整個文檔表示為高維向量來做到這一點。通過分析這些向量之間的異同,人工智能模型可以理解我們語言中的上下文、語義甚至細微差別。
那么,矢量數據庫從何而來?讓我們將矢量數據庫視為 AI 模型的圖書館員。在龐大的書籍庫(或者,在我們的例子中,向量)中,人工智能模型需要快速找到與特定查詢最相關的書籍。矢量數據庫通過有效地存儲這些“書籍”并在需要時提供快速精確的檢索來實現這一點。
這對于許多AI應用程序至關重要。例如,在聊天機器人應用程序中,AI 模型需要找到對用戶問題最相關的響應。它通過將用戶的問題和潛在響應轉換為向量,然后使用向量數據庫查找與用戶問題最相似的響應來實現這一點。
考慮到這一點,我們將使用上面的數據庫來提供一個 AI 模型 GPT-3.5,其中包含我們自己數據的上下文。這將允許模型回答有關未訓練的數據的問題。
人工智能模型設置通過運行并粘貼以下內容來創建新文件:touch src/data.js
import { Configuration, OpenAIApi } from "openai";
const configuration = new Configuration({
apiKey: process.env.OPENAI_API_KEY,
});
const openai = new OpenAIApi(configuration);
async function getChatCompletion({ prompt, context }) {
const chatCompletion = await openai.createChatCompletion({
model: "gpt-3.5-turbo",
messages: [
{
role: "system",
content: You are a knowledgebase oracle. You are given a question and a context. You answer the question based on the context. Analyse the information from the context and draw fundamental insights to accurately answer the question to the best of your ability. Context: ${context} ,
},
{ role: "user", content: prompt },
],
});
return chatCompletion.data.choices[0].message;
}
export { getChatCompletion };
像往常一樣,讓我們分解一下文件:
我們從包中導入一些必需的模塊并初始化一個實例openaiopenai
我們定義了一個函數,該函數接受提示、一些上下文,并將 GPT-3.5 模型配置為作為知識庫預言機進行響應getChatCompletion
最后,我們返回響應并導出函數
通過設置我們的矢量數據庫和 AI 模型,我們最終可以通過結合這兩個系統來查詢我們的數據。利用嵌入的強大效果和 GPT-3.5 令人印象深刻的自然語言功能,我們將能夠以更具表現力和可定制的方式與我們的數據進行交互。
首先創建一個新文件并運行 .然后粘貼以下內容:touch src/index.js
import { config } from "dotenv";
import { nearTextQuery } from "./database.js";
import { getChatCompletion } from "./model.js";
config();
const queryDatabase = async (prompt) => {
console.info(Querying database);
const questionContext = await nearTextQuery({
concepts: [prompt],
fields: "title text date",
limit: 50,
});
const context = questionContext
.map((context, index) => {
const { title, text, date } = context;
return Document ${index + 1} Date: ${date} Title: ${title} ${text} ;
})
.join("\n\n");
const aiResponse = await getChatCompletion({ prompt, context });
return aiResponse.content;
};
const main = async () => {
const command = process.argv[2];
const params = process.argv[3];
switch (command) {
case "migrate":
return await migrate(params === "--delete-all");
case "query":
return console.log(await queryDatabase(params));
default:
// do nothing
break;
}
};
main();
在此文件中,我們將到目前為止所做的所有工作匯集在一起,以允許我們通過命令行查詢數據。像往常一樣,讓我們探討一下這里發生了什么:
首先,我們導入必要的模塊并使用包設置我們的環境變量dotenv
接下來,我們創建一個接受文本提示的函數,我們使用它對向量數據庫執行“近文本”查詢。我們將結果限制為 50 個,并且我們特別要求提供匹配概念的“標題”、“文本”和“日期”字段queryDatabase
這基本上返回了語義上類似于我們搜索查詢中的任何重要術語的文檔(嵌入功能強大!
然后,我們映射接收到的上下文,對其進行格式化,并將其傳遞給AI模型以生成完成。使用上下文,GPT-3.5 的自然語言處理 (NLP) 功能大放異彩,因為它能夠根據我們的數據生成更準確和有意義的響應
最后,我們到達函數。在這里,我們使用命令行參數來執行各種任務。如果我們通過,我們可以遷移我們的數據(帶有可選標志,以防萬一我們想清理我們的石板并重新開始),并且有了,我們可以測試我們的查詢函數mainmigrate--delete-allquery
祝賀。如果你走到了這一步,你應該得到拍拍——你終于可以測試你的代碼了。
打開終端并運行以下命令:
npm run start "query" "what are the 3 most impressive achievements of humanity in the story?"
查詢將發送到您的 Weaviate 矢量數據庫,在那里它與其他類似矢量進行比較,并根據其文本返回 50 個最相似的矢量。然后,此上下文數據將被格式化并與您的查詢一起發送到 OpenAI 的 GPT-3.5 模型,在那里對其進行處理并生成響應。
如果一切順利,您應該得到與以下類似的響應:

隨意探索這個虛構的世界,更多的查詢,或者更好的是,帶上自己的數據,親眼目睹向量和嵌入的力量。
如果此時遇到任何錯誤,請在此處將您的代碼與最終版本進行比較,并確保已創建并填寫文件。.env
結論和今后的步驟在本教程中,我們略微探索了矢量和矢量數據庫的強大功能。使用Weaviate和GPT-3等工具,我們親眼目睹了這些技術在塑造AI應用程序方面的潛力,從改進個性化聊天機器人到增強機器學習算法。請務必也看看我們的GitHub!
然而,這僅僅是個開始。如果您想了解有關使用矢量數據庫的更多信息,請考慮:
深入了解高級概念,例如使用矢量元數據、分片、壓縮,以實現更靈活、更高效的數據存儲和檢索
嘗試更復雜的方法將向量嵌入集成到 AI 應用程序中,以獲得更豐富、更細微的結果
感謝您堅持到最后,希望這是對您的時間的有效利用。
您是否正在添加新的 JS 庫以提高性能或構建新功能?如果他們反其道而行之呢?毫無疑問,前端變得越來越復雜。當您向應用添加新的 JavaScript 庫和其他依賴項時,您將需要更高的可見性,以確保您的用戶不會遇到未知問題。
LogRocket 是一個前端應用程序監控解決方案,可讓您重播 JavaScript 錯誤,就好像它們發生在您自己的瀏覽器中一樣,這樣您就可以更有效地對錯誤做出反應。
LogRocket 可以完美地與任何應用程序配合使用,無論框架如何,并且具有用于記錄來自 Redux、Vuex 和 @ngrx/store 的其他上下文的插件。無需猜測問題發生的原因,您可以匯總并報告問題發生時應用程序所處的狀態。LogRocket 還會監控應用的性能,報告客戶端 CPU 負載、客戶端內存使用情況等指標。
原文鏈接:如何實現AI的矢量數據庫 (mvrlink.com)
*博客內容為網友個人發布,僅代表博主個人觀點,如有侵權請聯系工作人員刪除。








