基于支持向量機方法的車型分類技術(shù)

2.2核函數(shù)及模型參數(shù)選擇
本文引用地址:http://www.104case.com/article/87263.htm 應用SVM方法分類車型,輸入空間通過非線性映射到高維特征空間的分布結(jié)構(gòu)由核函數(shù)決定,同時,最優(yōu)超平面與最近的樣本之間的距離最大和分類錯誤率最小通過懲罰參數(shù)C進行折衷。因此,核函數(shù)設(shè)計和懲罰參數(shù)C的選擇將直接影響到車型分類的效果。目前常用的核函數(shù)有:
線性核 ![]() ,多項式核
,多項式核![]() 以及高斯徑向核
以及高斯徑向核![]() ,其中,d為多項式的階數(shù),σ為高斯分布的寬度。
,其中,d為多項式的階數(shù),σ為高斯分布的寬度。
在參數(shù)C、d及σ的選擇中,本文采用5-折交叉驗證法,將2 000個訓練樣本分為5個子集,每次將4個子集用于訓練,剩下的一個子集用于分類測試,重復上述過程,直到所有子集都參加了測試,計算5次平均分類錯誤率,選取平均分類錯誤率最小的參數(shù)為模型參數(shù)。
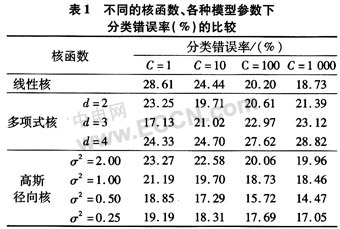
表1為不同的核函數(shù)、各種模型參數(shù)下分類錯誤率的比較結(jié)果。從表中可以看出,在不同的模型參數(shù)下,線性核函數(shù)的泛化誤差最大,多項式核函數(shù)次之,徑向基核函數(shù)最小。這主要是因為車型種類多、特征差異較小,低VC維的分類器很難很好地將它們分開。另外,對徑向基核函數(shù),一方面,當σ2恒定時,泛化誤差隨著C增大而減小,其原因主要是隨著C增大,訓練錯分樣本數(shù)減小,從而使泛化誤差減小;另一方面,當C恒定時,泛化誤差隨著σ2增大而基本上呈現(xiàn)出由大變小再變大的趨勢,其原因主要是當σ2較小時,分類器的VC維較大,出現(xiàn)了過學習而使泛化誤差變大。當σ2較大時,分類器的VC維較小,出現(xiàn)了欠學習而使泛化誤差變大。在有限的實驗參數(shù)范圍中,徑向基核函數(shù)在σ2=0.50、G=1 000時獲得14.47%的最小泛化誤差,可將其選作為車型分類的最佳模型。
2.3車型分類實驗
在模型訓練階段,從一段視頻中人工選取1 500個包含7種車型的訓練樣本進行訓練。在測試階段,采用訓練階段得到的模型對600個測試樣本進行分類。SVM方法分類性能結(jié)果如表2所示。
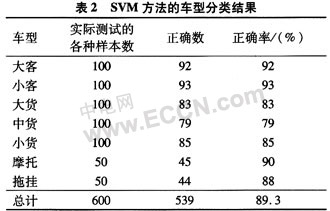
圖2是前面介紹的14個特征值作為支持向量機的輸入矢量,選擇高斯徑向核(σ2=0.50)、C=1 000來訓練SVM后進行分類的結(jié)果實例。

3結(jié)束語
本文采用SVM方法對車型分類進行了研究。實驗表明:核函數(shù)及模型參數(shù)對SVM方法的分類性能有較大的影響;對基于視頻的車型分類,SVM方法是一種很有前景的技術(shù)。





評論