TMS320C6678存儲(chǔ)器訪問(wèn)性能(上)

表3 列出了在1GHz C6678 EVM(64-bit 1333MTS DDR)上,在不同情況下用EDMA,IDMA和DSP核做大塊連續(xù)數(shù)據(jù)拷貝測(cè)得的吞吐量。
本文引用地址:http://www.104case.com/article/276392.htm在這些測(cè)試中,L1上的測(cè)試數(shù)據(jù)塊的大小是8KB;IDMA LL2->LL2 拷貝的數(shù)據(jù)塊的大小是32KB;其它DSP核拷貝測(cè)試的數(shù)據(jù)塊的大小是64KB,其它EDMA拷貝測(cè)試的數(shù)據(jù)塊大小是128KB。
吞吐量由拷貝的數(shù)據(jù)量除以消耗的時(shí)間得到。
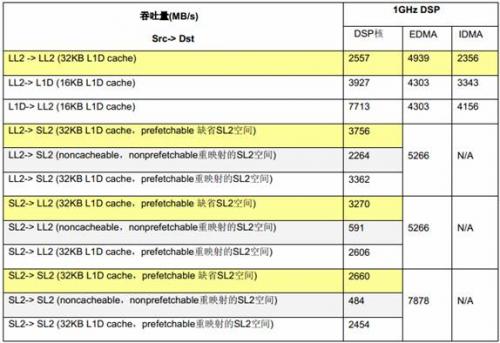
表3 DSP核,EDMA和IDMA數(shù)據(jù)拷貝的吞吐量比較
總的來(lái)說(shuō),DSP核可以高效地訪問(wèn)內(nèi)部存儲(chǔ)器,而用DSP 核訪問(wèn)外部存儲(chǔ)器則不是有效利用資源的方式;IDMA非常適用于DSP核本地存儲(chǔ)器 (L1D,L1P,LL2) 內(nèi)連續(xù)數(shù)據(jù)塊的傳輸,但它不能訪問(wèn)共享存儲(chǔ)器(SL2, DDR) ;而外部存儲(chǔ)器的訪問(wèn)則應(yīng)盡量使用EDMA。
Cache配置顯著地影響DSP核的訪問(wèn)性能,Prefetch buffer也能提高讀訪問(wèn)的效率,但它們不影響EDMA和IDMA。這里所有DSP核的測(cè)試都是基于cold cache(cache 和Prefetch buffer在測(cè)試前被清空)。
對(duì)DSP核,SL2可以通過(guò)從0x0C000000開(kāi)始的缺省地址空間被訪問(wèn),通常這個(gè)地址空間被設(shè)置為cacheable 而且prefetchable。SL2可以通過(guò)XMC(eXtended Memory Controller) 被重映射到其它存儲(chǔ)器空間,通常重映射空間被用作non-cacheable, nonprefetchable訪問(wèn)(當(dāng)然它也可以被設(shè)置為cacheable 而且prefetchable)。通過(guò)缺省地址空間訪問(wèn)比通過(guò)重映射空間訪問(wèn)稍微快一點(diǎn)。
前面列出的EDMA 吞吐量數(shù)據(jù)是在EDMA CC0(Channel Controller 0) TC0(Transfer Controller 0)上測(cè)得的,EDMA CC1和EDMA CC2的吞吐量比EDMA CC0低一些,后面有專門(mén)的章節(jié)來(lái)比較10個(gè)EDMA傳輸控制器的差別。
3. DSP核訪問(wèn)存儲(chǔ)器的時(shí)延
L1和DSP核的速度相同,所以DSP核每個(gè)時(shí)鐘周期可以訪問(wèn)L1存儲(chǔ)器一次。對(duì)一些特殊應(yīng)用,需要非常快的訪問(wèn)小塊數(shù)據(jù),可以把L1的一部分配置成普通RAM(而不是cache)來(lái)存放數(shù)據(jù)。
通常,L1被全部配置成cache,如果cache訪問(wèn)命中(hit),DSP核可在一個(gè)周期完成訪問(wèn);如果cache訪問(wèn)沒(méi)有命中(miss),DSP核需要等待數(shù)據(jù)從下一級(jí)存儲(chǔ)器中被讀到cache中。
本節(jié)討論DSP核訪問(wèn)內(nèi)部存儲(chǔ)器和外部DDR存儲(chǔ)器的時(shí)延。下面是時(shí)延測(cè)試的偽代碼:

3.1 DSP核訪問(wèn)LL2的時(shí)延
圖2是在1GHz C6678 EVM上測(cè)得的DSP核訪問(wèn)LL2的時(shí)延。DSP核執(zhí)行512個(gè)連續(xù)的LDDW(LoaD Double Word) 或STDW(STore Double Word) 指令所花的時(shí)間被測(cè)量,平均下來(lái)每個(gè)操作所花的時(shí)間被畫(huà)在圖中。這個(gè)測(cè)試使用了32KB L1D cache。
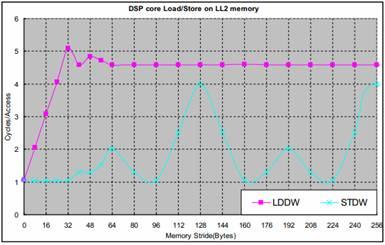
圖2 DSP核訪問(wèn)LL2
對(duì)LDB/STB和LDW/STW的測(cè)試表明,它們的時(shí)延與LDDW/STDW相同。
由于L1D cache只有在讀操作時(shí)才會(huì)被分配,DSP核讀LL2總是通過(guò)L1D cache。所以,DSP核訪問(wèn)LL2的性能高度依賴cache。多個(gè)訪問(wèn)之間的地址偏移(stride)顯著地影響訪問(wèn)效率,地址連續(xù)的訪問(wèn)可以充分地利用cache;大于或等于64字節(jié)的地址偏移導(dǎo)致每次訪問(wèn)都miss L1 cache因?yàn)長(zhǎng)1D cache行大小是64 bytes。
由于L1D cache不會(huì)在寫(xiě)操作時(shí)被分配,并且這里的測(cè)試之前cache都被清空了,所以任何對(duì)LL2的寫(xiě)操作都通過(guò)L1D write buffer(4x16bytes)。對(duì)多個(gè)寫(xiě)操作,如果地址偏移小于16bytes,這些操作可能在write buffer中被合并成一個(gè)對(duì)LL2的寫(xiě)操作,從而獲得接近平均每個(gè)寫(xiě)操作用1個(gè)時(shí)鐘周期的效率。
當(dāng)多個(gè)寫(xiě)操作之間的偏移是128bytes整數(shù)倍時(shí),每個(gè)寫(xiě)操作都訪問(wèn)LL2的相同sub-bank(LL2包含兩個(gè)banks,每個(gè)bank包含4個(gè)總線寬度為16-byte的sub-bank),對(duì)相同sub-bank的連續(xù)訪問(wèn)的時(shí)延是4個(gè)時(shí)鐘周期。對(duì)其它的訪問(wèn)偏移量,連續(xù)的寫(xiě)操作會(huì)訪問(wèn)LL2不同的bank,這樣的多個(gè)訪問(wèn)的在流水線上可以被重疊起來(lái),從而使平均的訪問(wèn)時(shí)延比較小。
C66x核在C64x+核的基礎(chǔ)上有很多改進(jìn),C66x核的L2存儲(chǔ)器控制器和DSP核速度相同,而C64x+的L2存儲(chǔ)器控制器的運(yùn)行速度是DSP核速度的1/2。圖3比較了C66x和C64x+Load/Store LL2存儲(chǔ)器的性能
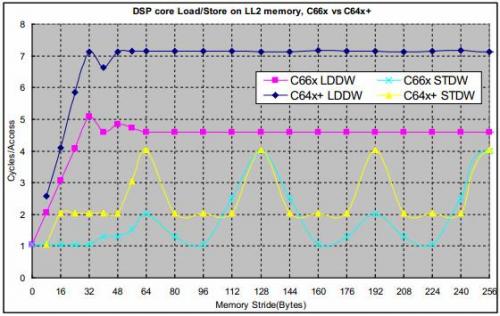
圖3 C66x和C64x+核在LL2上Load/Store的時(shí)延比較
3.2 DSP核訪問(wèn)SL2的時(shí)延
圖4 是在1GHz C6678 EVM上測(cè)得的DSP核訪問(wèn)SL2的時(shí)延。DSP核執(zhí)行512個(gè)連續(xù)的LDDW(LoaD Double Word) 或STDW(STore Double Word)指令所花的時(shí)間被測(cè)量,平均下來(lái)每個(gè)操作所花的時(shí)間被畫(huà)在圖中。測(cè)試中,L1D被配置成32KB cache。
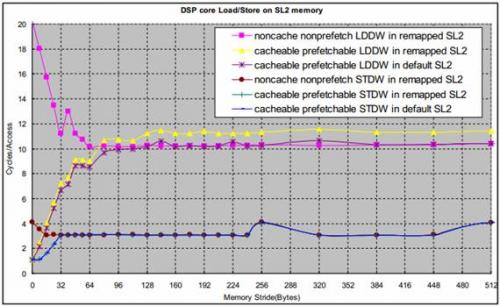
圖4 DSP核訪問(wèn)SL2
對(duì)LDB/STB和LDW/STW的測(cè)試表明,它們的時(shí)延LDDW/STDW相同。

存儲(chǔ)器相關(guān)文章:存儲(chǔ)器原理




評(píng)論