語音識別技術的研究與發展

摘 要: 回顧了語音識別技術的發展歷史,描述了語音識別系統的基本原理,介紹了語音識別的幾種基本方法,并對語音識別技術面臨的問題和發展前景進行了討論。
1 語音識別技術概述
語音識別是解決機器“聽懂”人類語言的一項技術。作為智能計算機研究的主導方向和人機語音通信的關鍵技術,語音識別技術一直受到各國科學界的廣泛關注。如今,隨著語音識別技術研究的突破,其對計算機發展和社會生活的重要性日益凸現出來。以語音識別技術開發出的產品應用領域非常廣泛,如聲控電話交換、信息網絡查詢、家庭服務、賓館服務、醫療服務、銀行服務、工業控制、語音通信系統等,幾乎深入到社會的每個行業和每個方面。
廣泛意義上的語音識別按照任務的不同可以分為4個方向:說話人識別、關鍵詞檢出、語言辨識和語音識別[1]。說話人識別技術是以話音對說話人進行區別,從而進行身份鑒別和認證的技術。關鍵詞檢出技術應用于一些具有特定要求的場合,只關注那些包含特定詞的句子,例如對一些特殊人名、地名的電話監聽等。語言辨識技術是通過分析處理一個語音片斷以判別其所屬語言種類的技術,本質上也是語音識別技術的一個方面。語音識別就是通常人們所說的以說話的內容作為識別對象的技術,它是4個方面中最重要和研究最廣泛的一個方向,也是本文討論的主要內容。
2 語音識別的研究歷史及現狀
語音識別的研究工作始于20世紀50年代,1952年Bell實驗室開發的Audry系統是第一個可以識別10個英文數字的語音識別系統。1959年,Rorgie和Forge采用數字計算機識別英文元音和孤立詞,從此開始了計算機語音識別。60年代,蘇聯的Matin等提出了語音結束點的端點檢測,使語音識別水平明顯上升;Vintsyuk提出了動態編程,這一提法在以后的識別中不可或缺。60年代末、70年代初的重要成果是提出了信號線性預測編碼(LPC)技術和動態時間規整(DTW)技術,有效地解決了語音信號的特征提取和不等長語音匹配問題;同時提出了矢量量化(VQ)和隱馬爾可夫模型(HMM)理論。
80年代語音識別研究進一步走向深入:HMM模型和人工神經網絡(ANN)在語音識別中成功應用。1988年,FULEE Kai等用VQ/I-IMM方法實現了997個詞匯的非特定人連續語音識別系統SPHINX。這是世界上第1個高性能的非特定人、大詞匯量、連續語音識別系統。
進入90年代后,語音識別技術進一步成熟,并開始向市場提供產品。許多發達國家如美國、日本、韓國以及IBM、Apple、ATT、Microsoft等公司都為語音識別系統的實用化開發研究投以巨資。同時漢語語音識別也越來越受到重視。IBM開發的 ViaVoice和Microsoft開發的中文識別引擎都具有了相當高的漢語語音識別水平。
進入21世紀,隨著消費類電子產品的普及,嵌入式語音處理技術發展迅速[2]。基于語音識別芯片的嵌入式產品也越來越多,如Sensory公司的RSC系列語音識別芯片、Infineon公司的Unispeech和Unilite語音芯片等,這些芯片在嵌入式硬件開發中得到了廣泛的應用。在軟件上,目前比較成功的語音識別軟件有:Nuance、IBM的Viavoice和Microsoft的SAPI以及開源軟件HTK,這些軟件都是面向非特定人、大詞匯量的連續語音識別系統。
我國語音識別研究一直緊跟國際水平,國家也很重視。國內中科院的自動化所、聲學所以及清華大學等科研機構和高校都在從事語音識別領域的研究和開發。國家863智能計算機專家組為語音識別技術研究專門立項,并取得了高水平的科研成果。我國中科院自動化所研制的非特定人、連續語音聽寫系統和漢語語音人機對話系統,其準確率和系統響應率均可達90%以上。
3 語音識別系統
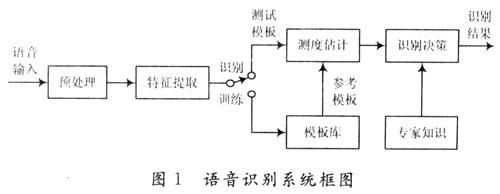
語音識別本質上是一種模式識別的過程,未知語音的模式與已知語音的參考模式逐一進行比較,最佳匹配的參考模式被作為識別結果。圖1是基于模式匹配原理的自動語音識別系統原理框圖。
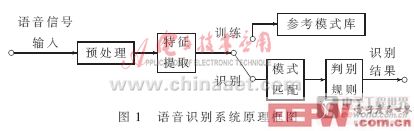
(1)預處理模塊:對輸入的原始語音信號進行處理,濾除掉其中的不重要的信息以及背景噪聲,并進行語音信號的端點檢測、語音分幀以及預加重等處理。



評論