雷達(dá)信號(hào)處理:FPGA還是GPU?
 加入技術(shù)交流群
加入技術(shù)交流群

掃碼加入
和技術(shù)大咖面對(duì)面交流
海量資料庫(kù)查詢
GPU可以通過(guò)使用Nvidia專(zhuān)用CUDA語(yǔ)言或開(kāi)放標(biāo)準(zhǔn)OpenCL語(yǔ)言來(lái)編程。這些語(yǔ)言在能力上非常相似,最大的不同在于CUDA只能用在Nvidia GPU上。
FPGA通常使用HDL語(yǔ)言Verilog或VHDL進(jìn)行編程。這些語(yǔ)言的最新版雖然采用了浮點(diǎn)數(shù)定義,但都不太適合支持浮點(diǎn)設(shè)計(jì)。例如,在System Verilog中,短實(shí)數(shù)變量對(duì)應(yīng)于IEEE單精度(浮點(diǎn)),實(shí)數(shù)變量對(duì)應(yīng)于IEEE雙精度。
DSP Builder高級(jí)模塊庫(kù)
使用傳統(tǒng)的方法將浮點(diǎn)數(shù)據(jù)通路綜合到FPGA的效率非常低,如Xilinx FPGA在Cholesky算法上使用了Xilinx浮點(diǎn)內(nèi)核產(chǎn)生函數(shù)的低性能顯示,。而Altera采兩種不同的方法。首先是使用DSP Builder高級(jí)模塊庫(kù),這是基于Mathworks的設(shè)計(jì)輸入方法。這一工具支持定點(diǎn)和浮點(diǎn)數(shù),支持7種不同精度的浮點(diǎn)處理,包括IEEE半、單和雙精度實(shí)現(xiàn)。它還支持矢量化,這是高效實(shí)現(xiàn)線性代數(shù)所需要的。最重要的是,它能夠?qū)⒏↑c(diǎn)電路高效的映射到目前的定點(diǎn)FPGA體系結(jié)構(gòu)中,如基準(zhǔn)測(cè)試所示,規(guī)模中等的28 nm FPGA,Cholesky算法接近了100 GFLOP。作為對(duì)比,在不具有綜合能力的規(guī)模相似的Xilinx FPGA上,實(shí)現(xiàn)Cholesky相同算法,性能只有20 GFLOP。
面向FPGA的OpenCL
GPU編程人員較為熟悉OpenCL。面向FPGA的OpenCL編譯意味著,面向AMD或Nvidia GPU編寫(xiě)的OpenCL代碼可以編譯到FPGA中。而且,Altera的OpenCL編譯器支持GPU程序使用FPGA,無(wú)需具備典型的FPGA設(shè)計(jì)技巧。
使用支持FPGA的OpenCL,相對(duì)于GPU有幾個(gè)關(guān)鍵優(yōu)勢(shì)。首先,GPU的I/O是有限制的。所有輸入和輸出數(shù)據(jù)必須由主CPU通過(guò)PCI Express® (PCIe®)接口進(jìn)行傳輸。結(jié)果延時(shí)會(huì)讓GPU處理引擎暫停,因此,降低了性能。
面向FPGA的OpenCL擴(kuò)展
FPGA以各種寬帶I/O功能而知名。這些功能支持?jǐn)?shù)據(jù)通過(guò)千兆以太網(wǎng)(GbE)和Serial RapidIO® (SRIO),或直接從模數(shù)轉(zhuǎn)換器(ADC)和數(shù)模轉(zhuǎn)換器(DAC)輸入輸出FPGA。Altera定義了OpenCL標(biāo)準(zhǔn)的供應(yīng)商專(zhuān)用擴(kuò)展,以支持流操作。這種擴(kuò)展對(duì)于雷達(dá)系統(tǒng)非常關(guān)鍵,數(shù)據(jù)能夠從定點(diǎn)前端波束成形直接輸出,支持浮點(diǎn)處理階段的數(shù)字下變頻處理,實(shí)現(xiàn)脈沖壓縮,多普勒,STAP, 動(dòng)目標(biāo)顯示(MTI),以及圖2所示的其他功能。通過(guò)這種方法,數(shù)據(jù)流在通過(guò)GPU加速器之前,避免了CPU瓶頸問(wèn)題,從而降低了總處理延時(shí)。
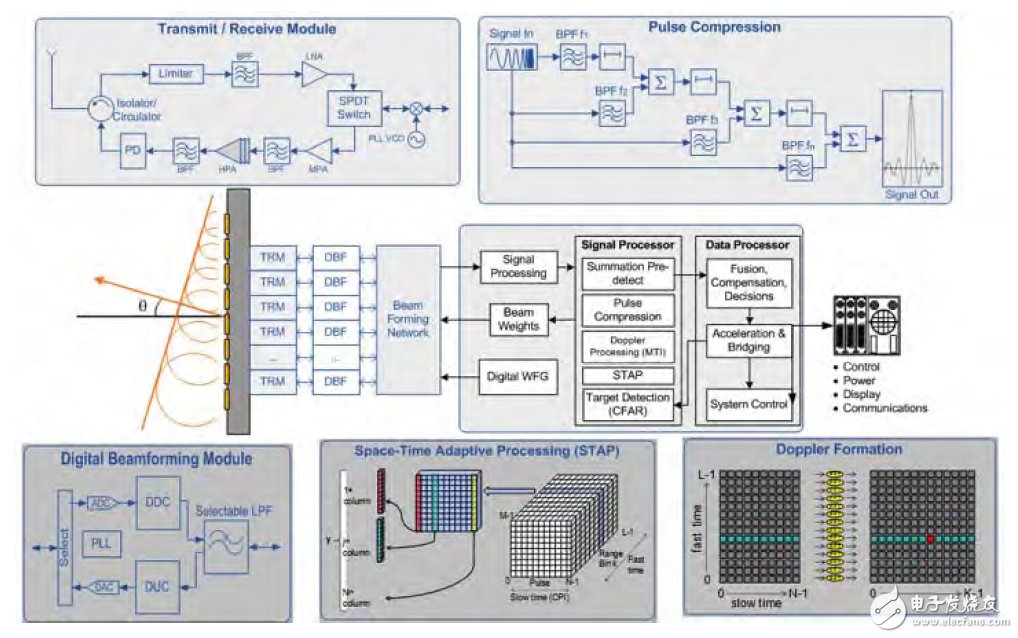
圖2.通用雷達(dá)信號(hào)處理圖
即使與I/O瓶頸無(wú)關(guān),F(xiàn)PGA的處理延時(shí)也要比GPU低很多。眾所周知,GPU必須有數(shù)千個(gè)線程才能高效工作,這是由于存儲(chǔ)器讀取很長(zhǎng)的延時(shí),以及GPU大量的處理內(nèi)核之間的延時(shí)。實(shí)際上,GPU必須有很多任務(wù)才能使得處理內(nèi)核不會(huì)暫停等待數(shù)據(jù),否則會(huì)導(dǎo)致任務(wù)很長(zhǎng)的延時(shí)。
而FPGA使用了“粗粒度并行”體系結(jié)構(gòu)。它建立了多個(gè)經(jīng)過(guò)優(yōu)化的并行數(shù)據(jù)通路,每一通路在每個(gè)時(shí)鐘周期輸出一個(gè)結(jié)果。數(shù)據(jù)通路的例化數(shù)取決于FPGA資源,但一般要比GPU內(nèi)核數(shù)少很多。但是,每一數(shù)據(jù)通路例化的吞吐量要比GPU內(nèi)核高得多。這一方法的主要優(yōu)勢(shì)是低延時(shí),這在很多應(yīng)用中都是關(guān)鍵的性能優(yōu)勢(shì)。
FPGA的另一優(yōu)勢(shì)是很低的功耗,極大的降低了GFLOPs/W。使用開(kāi)發(fā)板測(cè)量FPGA功耗,表明Cholesky和QRD等算法是5-6 GFLOPs/W,而FFT等簡(jiǎn)單算法則是10 GFLOPs/W。一般很難進(jìn)行GPU能效測(cè)量,但是,Cholesky的GPU性能達(dá)到50 GFLOP,典型功耗是200 W,得到的結(jié)果是0.25 GFLOPs/W,單位FLOP的功率比FPGA高20倍。
對(duì)于機(jī)載或車(chē)載雷達(dá)裝備,系統(tǒng)體積、重量和功耗(SWaP)都非常重要。在未來(lái)的系統(tǒng)中,雷達(dá)工作很容易達(dá)到數(shù)十個(gè)TFLOP。總處理能力與現(xiàn)代雷達(dá)系統(tǒng)的分辨率和覆蓋范圍相關(guān)。
融合數(shù)據(jù)通路
OpenCL和DSP Builder都依靠“融合數(shù)據(jù)通路”這種技術(shù)(圖3),以這種技術(shù)實(shí)現(xiàn)浮點(diǎn)處理,能大幅度減少桶形移位電路,支持使用FPGA開(kāi)發(fā)大規(guī)模高性能浮點(diǎn)設(shè)計(jì)。
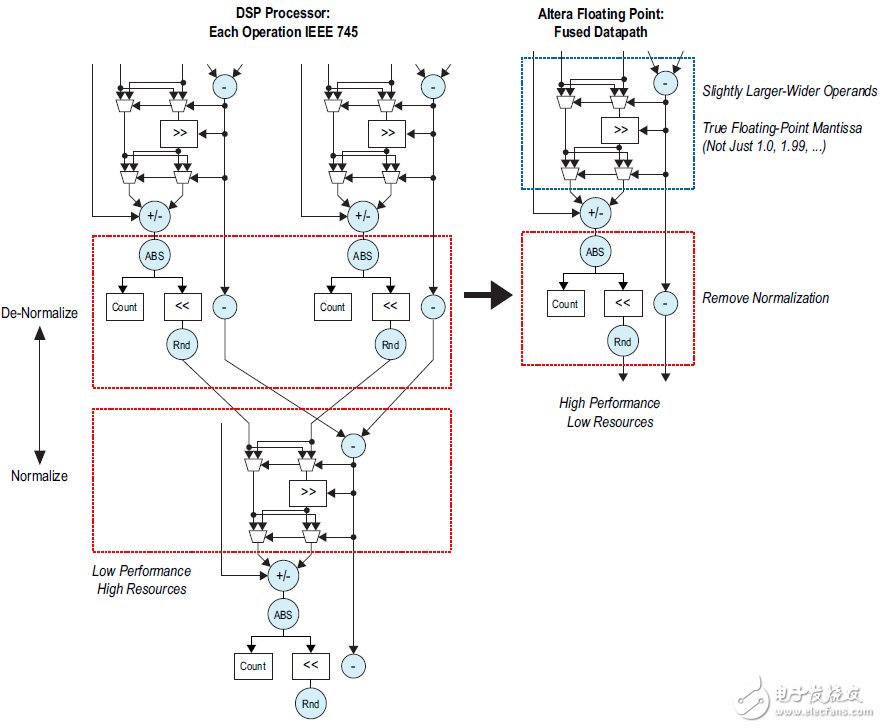
圖3.采用融合數(shù)據(jù)通路實(shí)現(xiàn)浮點(diǎn)處理

fpga相關(guān)文章:fpga是什么
鎖相環(huán)相關(guān)文章:鎖相環(huán)原理







評(píng)論