AMD新專利,解決多芯粒GPU延遲

據報道,基于最新獲批的專利,AMD 公司已探索「智能交換器」優化數據處理,從而解決多芯粒 GPU 的延遲問題。有消息稱在消費級 GPU 領域,AMD 預計將采用多芯粒模塊設計。
多芯粒模塊設計,即將多個芯片集成到一個封裝中,之前已在高性能計算領域得到應用,而 AMD 計劃將其擴展到游戲 GPU,以應對單芯片設計在制造和性能上的瓶頸。
此前,AMD 在這方面積累了豐富的經驗,例如其 Instinct 系列加速器已采用多芯片設計。Instinct MI200 使用多個圖形計算芯片與高帶寬內存堆疊,實現了高效的數據傳輸。后續的 Instinct MI350 系列進一步優化了這一結構,搭載 288GB HBM3E 內存,內存帶寬達 8TB/s,基于 3nm 工藝節點,總晶體管數達 1850 億。該系列通過 10 個芯片模塊的 2D 混合鍵合,提升了 AI 任務的處理能力,為消費級產品提供了技術基礎。
具體到游戲領域,GPU 若要采用多芯粒模塊設計,那么最大的問題就是延遲較高,因為幀渲染對長距離數據傳輸的延遲非常敏感。若要解決這一問題,AMD 就必須想出一種能盡可能縮小數據與計算之間差距的方案。
根據披露的一項新專利申請,AMD 或許已經破解了多芯粒模塊設計游戲 GPU 的設計之道。不過,該專利視頻中披露的是 CPU 相關細節,而非 GPU,但文本內容和機制表明其目標是圖形應用場景。
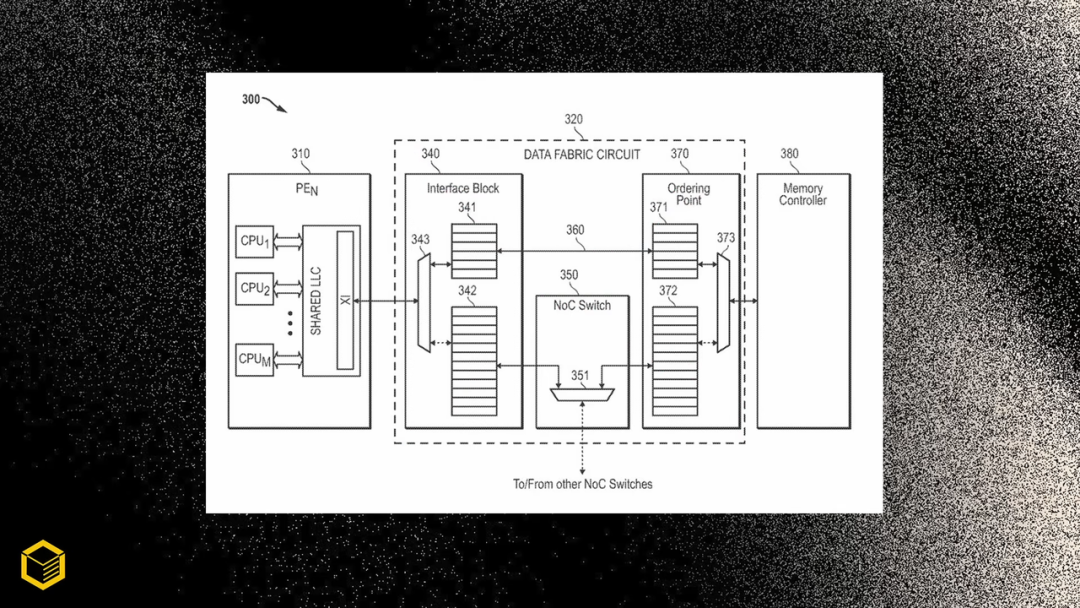
那么,AMD 究竟將如何在 GPU 中運用多芯粒模塊設計呢?據悉,該專利的核心是一種「帶有智能交換機的數據架構電路」,它能連接計算小芯片與內存控制器之間的通信。這本質上是 AMD
那么,AMD 究竟將如何在 GPU 中運用多芯粒模塊設計呢?據悉,該專利的核心是一種「帶有智能交換機的數據架構電路」,它能連接計算小芯片與內存控制器之間的通信。這本質上是 AMD Infinity Fabric,但為消費級 GPU 進行了縮減,因為 AMD 無法采用 HBM 內存芯片。該交換機旨在優化內存訪問,其工作原理是先判斷圖形任務請求是否需要任務遷移或數據復制,決策延遲達到納秒級。
解決了數據訪問問題后,該專利還指出要讓圖形計算核心(GCD)配備 L1 和 L2 緩存,這與 AI 加速器的設計類似。不過,通過交換機還能訪問額外的共享 L3 緩存(或堆疊式 SRAM),該緩存將連接所有 GCD。這不僅減少了對全局內存的訪問依賴,同時能夠充當小芯片之間的共享過渡區,類似于 AMD 3D V-Cache 技術,只不過 3D V-Cache 主要用于處理器。此外,該專利還涉及堆疊式 DRAM,這本質上是多芯粒模塊設計的基礎。
這一專利的出現表明,AMD 已為多芯片 GPU 生態做好準備。AMD 可以使用臺積電的 InFO-RDL 橋接技術,以及在小芯片之間使用特定版本的 Infinity Fabric 進行封裝。更具吸引力的是,這種實現方式是 AI 加速器的縮減版本。此前,AMD 計劃將其游戲和 AI 架構合并為一個統一架構,即 UDNA 架構。AMD 還整合了軟件生態系統,這樣可以攤薄驅動程序和編譯器的開發工作。
由于單芯片設計存在局限性,這或許是 AMD 超越競爭對手的絕佳機會。然而,芯粒設計也存在復雜性,AMD 此前在 RDNA 3 上就曾遇到過小芯片互連帶來的延遲。AMD RDNA 3 架構 Navi 31 GPU 已部分采用多芯片設計,配備六個內存控制器芯片,總 Infinity Cache 達 96MB,內存總線寬 384 位,支持高達 24GB GDDR6 內存。通過 Infinity Fabric 互聯,峰值帶寬達 5.2TB/s。該設計在 RX 7900 系列中實現,每瓦性能較前代提升 50%,但也暴露了芯片間延遲的缺陷。
然而憑借創新的交換機方案,再加上額外的共享 L3 緩存,AMD 有望解決延遲問題。不過,具體效果如何,可能要到 UDNA 5 才能見分曉。










評論