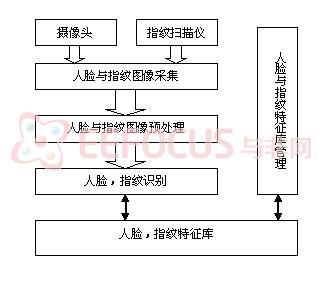
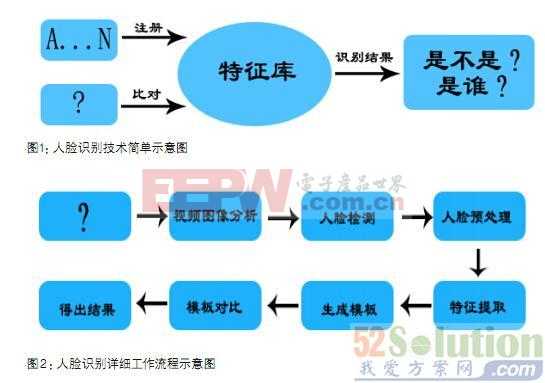
ZLG深度解析人臉識別核心技術

5.人臉反欺詐
本文引用地址:http://www.104case.com/article/201901/396553.htm從技術角度來說,人臉是唯一不需要用戶配合就可以采集的生物特征信息。人臉不同于指紋、掌紋、虹膜等,用戶不愿意被采集信息就無法獲得高質量的特征信息。人臉信息簡單易得,而且質量還好,所以這引發了有關個人數據安全性的思考。而且在沒有設計人臉反欺詐算法的人臉識別系統使用手機、ipad或是打印的圖片等都能對輕松欺騙系統。
所以我們采用多傳感器融合技術的方案,使用紅外對管與圖像傳感器數據進行深度學習來判斷是否存在欺詐。紅外對管進行用戶距離的判斷,距離過近則懷疑欺詐行為。圖像傳感器用深度學習算法進行二分類,把正常用戶行為與欺詐用戶行為分為兩類,對欺詐用戶進行排除。
二分類算法能夠有效抵抗一定距離的手機、ipad或是打印圖片的欺詐攻擊。對人臉欺詐數據集與普通人臉數據集預測如圖所示:
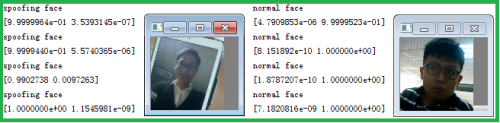
本二分類算法在100萬張圖片中準確分類的概率為98.89%,所以并不會對整體系統的準確率進行影響,保障系統的可靠性。
6.算法優化
在使用神經網絡算法解決問題的時候,算法效率問題是必要的考量的。特別是在資源與算力不足的嵌入式端,更是頭等大問題。除了依托TensorFlow、Keras等開源框架,根據其前向傳播的原理寫成C++程序,還有必要的編譯優化外,模型權重參數的清洗和算法計算的向量化都是比較有效的手段。
1)模型權重參數清洗
權重參數清洗對神經網絡算法的效率影響相當大,沒有進行清洗的權重參數訪問與操作非常低效,與清洗后的權重參數相比往往能效率相差6-8倍。這差距在算力不足的嵌入式端非常明顯,往往決定一個算法是否能落地。具體的方法就是先讀取原模型進行重組,讓參數變得緊湊且能在計算時連續訪問計算,最后獲得重組后的模型與對應的重組模型的計算方法。這個步驟需要一定的優化實踐經驗以達到滿意的效果,對模型讀取效率與運算效率都會有顯著的提高。
2)算法計算向量化
對于算法的向量化的做法就是讓算法的計算能夠使用向量乘加等運算,而特別是在使用神經網絡算法情況下,大量的計算沒有前后相關性且執行相類似的步驟,所以向量化計算會對算法有明顯的提升,一般能把算法效率提升三倍左右。
使用NEON指令集的SIMD指令取代ARM通用的SISD指令,是一個常用的算法向量化方法。在基于ARMV7-A和ARMV7-R的體系架構上基本采用了NEON技術,ARMV8也支持并與ARMV7兼容。
以IMX6ULL芯片為例,可以通過查閱官方的參考手冊查看其NEON相關信息:

下面舉例說明普通的編程寫法與NEON instrinsics編程、NEON assembly編程區別。以下為普通的編程寫法:

以下為轉化為NEON instrinsics的編程:

以為轉為NEON assembly的編程:

一般NEON instrinsics已經能做到三倍的提速效果,而NEON assembly效果會更好一些。但是程序向量化需要特殊訪存規則,如果不符合則會對導致提速效果大打折扣。
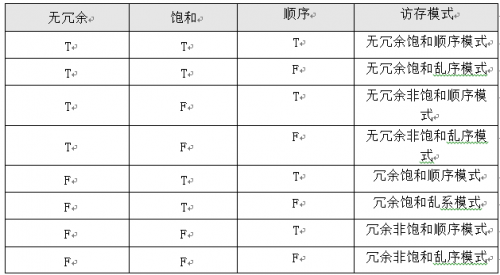
訪存特征詳細分類如表所示:




評論