人工智能:破解梵蒂岡神秘卷宗之謎

這個 AI 認識中世紀手寫拉丁文
本文引用地址:http://www.104case.com/article/201805/379837.htm“以后青銅銘文也交給 AI 來識別好了!”
AI 識別文字已經不算是什么難事,但是如果字體是手寫,而且還是古文呢?
這似乎聽起來具有相當的難度!
梵蒂岡秘密檔案館(Vatican Secret Archives)可謂全球最偉大的歷史藏品之一,但其珍藏的許多文件從未轉錄。近日,一個名為 Codice Ratio 項目,利用人工智能與光學字符識別(簡稱 OCR)軟件的組合重現這些被忽視的文本,并將其重新呈現在世人面前。
這座恢宏的建筑坐落在梵蒂岡城墻之內,毗鄰使徒圖書館、位于西斯廷大教堂北側,擁有著可追溯于1200年之前的總長達53英里的書架。除了將Martin Luther逐出教會的《教皇詔書》之外,其中還包括蘇格蘭瑪麗女王被處決之前發給教皇西克斯五世的函件。在規模與范圍方面,其中的收藏幾乎著稱無與倫比。

然而,梵蒂岡秘密檔案館對現代學者卻沒多大現實意義。因為在這長達53英里的書架當中,只有極少數書頁經過掃描以提供在線版本,這當中的一小部分轉錄為計算機文本以供內容搜索。如果我們打算閱讀其它任何內容,則必須申請特殊的訪問權限,一路前往羅馬,并親自動手翻開這些古籍。
傳統 OCR 技術只適用于經過嚴格排版的文字,而對于字母之間缺少間隔空間(即臟分割)的手寫卷宗形式則無法識別。對此, Codice Ratio 項目利用拼圖分割法將單詞理解為一種單筆筆劃,軟件只需要知曉哪些組塊代表真實的字母,而哪些只是連筆造成的假象即可。該軟件的手寫字母判斷準確率已經高達96%。如果成功,這項技術還將被用于處理世界各地其它歷史檔案庫當中數不勝數的其它記錄文件。

利用拼圖分割法讓 OCR 識別連體字
由于傳統OCR技術是把單詞分割成一個個字母來識別的,所以對于這類連體字,OCR無法識別字母。有人想出了一個方案,直接讓OCR去識別一個個的單詞,但是,如何讓OCR掌握成千上萬的拉丁文單詞呢?大概需要一個排的中世紀拉丁文專家來辨認不同單詞的圖形。
除了請專家辨認單詞外,還有更簡單的方法幫助OCR識別手寫字母,只要找實習生就可以搞定了。
我們知道,無論中文還是英文,連體字中粗的部分是筆畫,細的部分是筆尖移動造成的虛線,并不是筆畫的一部分。根據這個原則,In Codice Ratio的專家們發明了新的方法——拼圖分割法。拼圖分割法改變了傳統OCR把單詞分成字母的傳統方式,而是是把連在一起的單詞按照筆畫分隔開,在此之后,該軟件會進一步進行字母繪制,并最終生成以下一系列拼圖碎片:

這些拼圖碎片本身作用不大,但該軟件能夠將其通過多種方式組合起來以生成可能的字母。具體來講,軟件只需要知曉哪些組塊代表真實的字母,而哪些只是連筆造成的假象即可。
為了教會軟件這項能力,研究人員們選擇了不同尋常的導師——高中生。該團隊在意大利的24所學校當中招募了一批高中生用于建立項目的記憶庫。學生們在登錄相關網站后,會看到如下圖所示的三分屏幕界面:
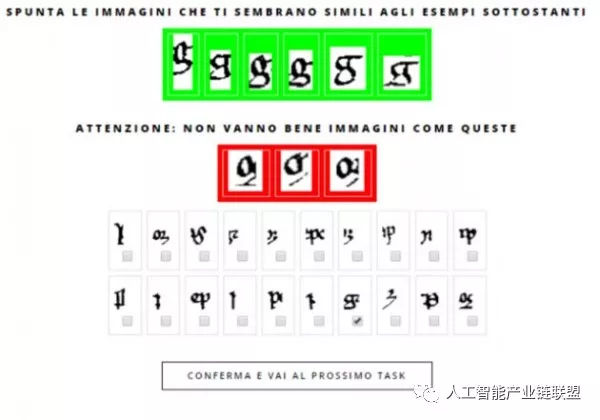
之后,就要讓識別系統判斷對錯:識別出的字母,哪些是真正的字母,哪些是虛線的誤判。
通過一次次點擊,學生們努力教授該軟件如何識別22個中世紀拉丁字母(a-i,l-u,以及s與d的某些替代形式)。 22個中世紀拉丁文字母都學會之后,這個識別系統就成為了一個能認識手寫體中世紀拉丁文的AI。
當然,最終學生們也不再需要參與其中。當訓練進行到一定階段之后,該軟件即可獨立拼圖,并自行判斷字母的具體位置。這,正是人工智能的價值所在。
在另一方面,這也證明單靠拼圖碎片還不足以組合出正確的字母。計算機仍然需要額外的幫助才能破解手寫文本的秘密。想象一下,大家正在讀信,并在其中看到下面這句:

中間的單詞到底是“clear”還是“dear”?很難判斷,因為“d”與“cl”的筆畫構成實際上完全相同。OCR軟件也面臨著同樣的問題,特別是在處理高度風格化的文本時更是如此。以下圖為例:

在經過不同的拼圖組合之后,OCR認為可能的選項包括aimo、amio、aniio、aiino甚至是aiiiio。但這個詞實際上是anno,也就是拉丁語中的年。該軟件認準了a和o,但卻弄不清中間的四個豎到底該如何劃分。
為了解決這個問題,Codice Ratio團隊不得不為自己的軟件提供一些常識性的知識。他們建立起一套包含150萬個經過數字化的拉丁詞匯語料庫,并對其中的雙字母與三字母組合進行了檢查。通過這種方式,他們確定了哪些字母組合較為常見,而哪些永遠不會出現。通過將這些統計信息提供給OCR軟件,其能夠了解到不同字符串的具體出現概率,從而意識到nn比iiii的可能性高得多。
隨著這樣的改進,OCR終于能夠自行閱讀部分文本了。該團隊決定為其提供一些來自梵蒂岡秘密歸案館的資料。這是一份超過18000頁的檔案集合,其中包括寫給歐洲國王的信件、關于法律問題的裁決以及其它信件。
最初的結果有好有壞。在迄今為止的全部轉錄文本中,有三分之一文檔中包含一處或多處拼寫錯誤——意味著OCR作出了錯誤的判斷。然而,該軟件仍然帶來了高達96%的手寫字母判斷準確率。Merialdo表示,即使是“不完美的轉錄結果,亦可提供關于手稿內容及背景的大量有價值信息。”
經過對AI更專業的訓練后,它可以識別各大文明的古代文獻并電子化。
所以,為了給AI提升難度,青銅銘文了解一下?

梵蒂岡秘密檔案館(Vatican Secret Archives):由教皇保羅五世(Pope Paul V)主導創立,是歐洲教會中收藏檔案最豐富,最古老的檔案館。梵蒂岡秘密檔案館擁有著可追溯于1200年之前的總長達53英里的書架,其中保存著各種古籍、歷史事件檔案、教皇的私人信件以及一些有關超自然現象和神秘學的資料。梵蒂岡秘密檔案館收錄了許多重要史料,除了將 Martin Luther 逐出教會的《教皇詔書》之外,還包括蘇格蘭瑪麗女王被處決之前發給教皇西克斯五世的函件。










評論