2016人工智能技術發展進程梳理

Intel人工智能布局
本文引用地址:http://www.104case.com/article/201702/343473.htmIntel收購Nervana
8月9日,Intel宣布收購創業公司Nervana Systems。Nervana的IP和加速深度學習算法經驗可幫助Intel在人工智能領域獲得一席之地。
Nervana提供基于云的服務用于深度學習,使用獨立開發的、使用匯編級別優化的、支持多GPU的Neon軟件,在卷積計算時采用了Winograd算法,數據載入也做了很多優化。該公司宣稱,訓練模型時,Neon比使用最普遍的Caffe快2倍。不僅如此,Nervana準備推出深度學習定制芯片Nervana Engine,相比GPU在訓練方面可以提升10倍性能。與Tesla P100類似,該芯片也利用16-bit半精度浮點計算單元和大容量高帶寬內存(HBM,計劃為32GB,是競品P100的兩倍),摒棄了大量深度學習不需要的通用計算單元。
在硬件基礎上,Nervana于11月份推出了Intel Nervana Graph平臺(簡稱ngraph)。該框架由三部分組成:一個用于創建計算圖的API、用于處理常見深度學習工作流的前端API(目前支持TensorFlow和Neon)、用于在 CPU/GPU/Nervana Engine上編譯執行計算圖的轉換器API。
與此同時宣布成立Intel Nervana人工智能委員會,加拿大蒙特利爾大學Yoshua Bengio教授擔任創始會員。
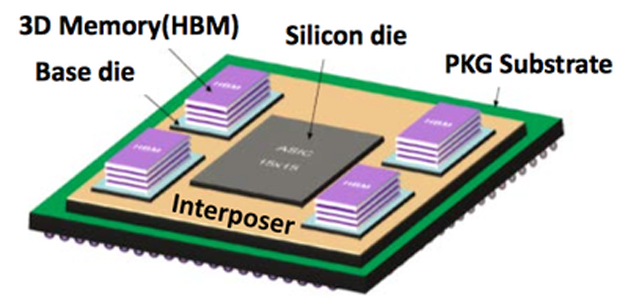
圖7 Nervana Engine芯片架構
8月17日,在Intel開發者峰會(IDF)上,Intel透露了面向深度學習應用的新Xeon Phi處理器,名為Knights Mill(縮寫為 KNM)。它不是Knights Landing和Knights Hill的競品,而是定位在神經網絡云服務中與NVIDIA Tesla GPU一較高下。
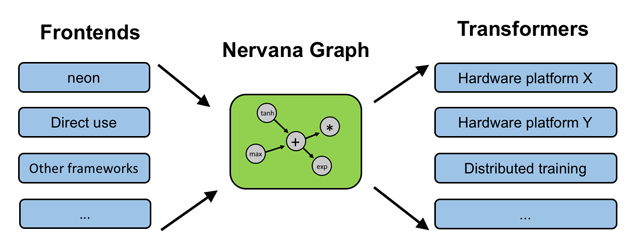
圖8 ngraph框架
9月6日,Intel收購計算機視覺創業公司Movidius。
Movidius是人工智能芯片廠商,提供低能耗計算機視覺芯片組。Google眼鏡內配置了Movidius計算機視覺芯片。Movidius芯片可以應用在可穿戴設備、無人機和機器人中,完成目標識別和深度測量等任務。除了Google之外Movidius與國內聯想和大疆等公司簽訂了協議。Movidius的Myriad 2系列圖形處理器已經被聯想用來開發下一代虛擬現實產品。
9月8日,Intel FPGA技術大會(IFTD)杭州站宣布了Xeon-FPGA集成芯片項目。這是Intel并購Altera后最大的整合舉動,Intel將推出CPU+FPGA架構的硬件平臺,該平臺預計于2017年量產,屆時,一片Skylake架構的Xeon CPU和一片Stratix10的FPGA將“合二為一”,通過QPI Cache一致性互聯使FPGA獲得高帶寬、低延遲的數據通路。在這種形態中,FPGA本身就成為了CPU的一部分,甚至CPU上的軟件無需“感知”到FPGA的存在,直接調用mkl庫就可以利用 FPGA來加速某些計算密集的任務。
Xeon-FPGA樣機已經在世界七大云廠商(Amazon、Google、微軟、Facebook、百度、阿里、騰訊)試用,用于加速各自業務熱點和基礎設施,包括機器學習、搜索算法、數據庫、存儲、壓縮、加密、高速網絡互連等。
除了上面CPU+FPGA集成的解決方案,Altera也有基于PCIe加速卡的解決方案。
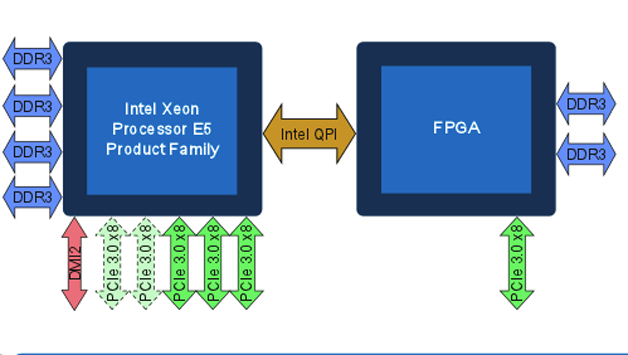
圖9 Xeon-FPGA集成芯片架構
11月8日ISDF大會上宣布,預計明年將銷售深度學習預測加速器(DLIA,Deep Learning Inference Accelerator)。該加速器為軟硬件集成的解決方案,用于加速卷積神經網絡的預測(即前向計算)。軟件基于Intel MKL-DNN軟件庫和Caffe框架,便于二次開發,基于PCIe的FPGA加速卡提供硬件加速。該產品將直接同Google TPU、NVIDIA Tesla P4/M4展開競爭。
小結: Intel在人工智能領域的動作之大(All in AI),品類之全(面向訓練、預測,面向服務器、嵌入式),涉獵之廣(Xeon Phi,FPGA,ASIC)令人為之一振。冰凍三尺非一日之寒,AI硬件和上層軟件的推廣與普及還有很長一段路要走。
NVIDIA人工智能布局
NVIDIA財報顯示,深度學習用戶目前占據數據中心銷售額一半,而HPC占三分之一,剩下的為虛擬化(例如虛擬桌面)。這也驅動NVIDIA在硬件架構和軟件庫方面不斷加強深度學習性能,典型例子是在Maxwell處理器中最大化單精度性能,而在Pascal架構中增加了半精度運算單元。與HPC不同,深度學習軟件能夠利用較低精度實現較高吞吐。
Pascal架構
在4月5日GTC(GPU Technology Conference)2016大會上,NVIDIA發布了16nm FinFET制程超級核彈帕斯卡(Pascal)顯卡,最讓人驚嘆的還是一款定位于深度學習的超級計算機DGX-1。DGX-1擁有8顆帕斯卡架構GP100核心的Tesla P100 GPU,以及7TB的SSD,兩顆16核心的Xeon E5-2698 v3以及512GB的DDR4內存,半精度浮點處理能力170TFLOPS,功耗3.2kW。售價129000美元,現已面市。
9月13日,NVIDIA在GTC中國北京站發布了Tesla P4和P40。這兩個處理器也基于最新的Pascal架構,是去年發布的M4和M40的升級版,包括了面向深度學習預測計算的功能單元,丟掉了64位雙精度浮點計算單元,取而代之的是8-bit整數算法單元。詳細參數如下。

圖10 DGX-1外觀
Tesla P4為半高半長卡,功耗只有50~75W,便于安裝到已有的Web Server提供高效的預測服務。同時,P4包括一個視頻解碼引擎和兩個視頻編碼引擎,對基于視頻的預測服務更為適合。
Tesla P40與P4用途稍有不同,絕對性能高,適合訓練+預測,使用GoogLeNet評估時相比上一代M40有8倍性能提升。
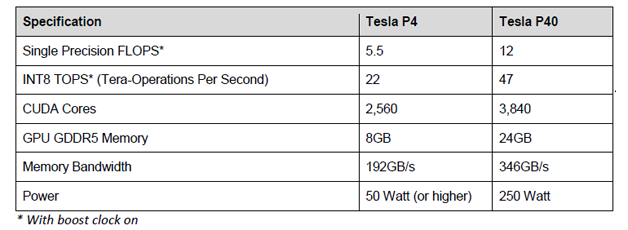
圖11 Tesla P4/P40參數對比
Tesla P100仍然是最合適訓練的GPU,自帶NVLink多GPU快速互聯接口和HBM2。這些特性是P40和P4不具備的,因為面向預測的GPU不需要這些。
Pascal家族從P100到P4,相對三年前的Kepler架構提速達到40~60倍。
在硬件之外,NVIDIA軟件方面也不遺余力。
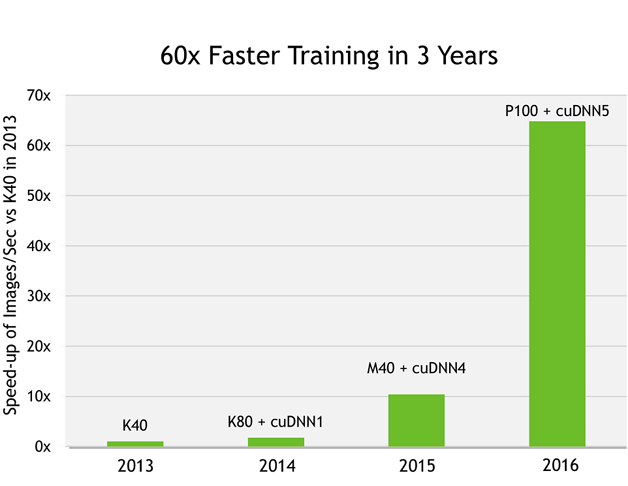
圖12 NVIDIA Pascal架構軟硬件加速情況
cuDNN
NVIDIA CUDA深度神經網絡庫(cuDNN)是一個GPU上的深度神經網絡原語加速庫。cuDNN提供高度優化的標準功能(例如卷積、下采樣、歸一化、激活層、LSTM的前向和后向計算)實現。目前cuDNN支持絕大多數廣泛使用的深度學習框架如Caffe、TensorFlow、Theano、Torch和CNTK等。對使用頻率高的計算,如VGG模型中的3x3卷積做了特別優化。支持Windows/Linux/MacOS系統,支持Pascal/Maxwell/Kepler硬件架構,支持嵌入式平臺Tegra K1/X1。在Pascal架構上使用FP16實現,以減少內存占用并提升計算性能。
TensorRT
TensorRT是一個提供更快響應時間的神經網絡預測引擎,適合深度學習應用產品上線部署。開發者可以使用TensorRT實現高效預測,利用INT8或FP16優化過的低精度計算,可以顯著降低延遲。
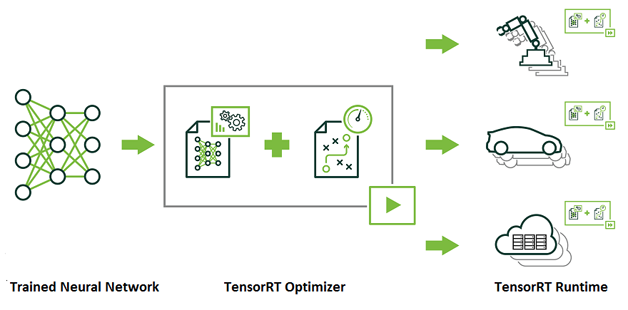
圖13 TensorRT的使用方式
DeepStream SDK支持深度學習視頻分析,在送入預測引擎之前做解碼、預處理。
這兩個軟件庫都是與Pascal GPU一起使用的。
小結: NVIDIA是最早在AI發力的硬件廠商,但從未停止在軟件上的開發和探索,不斷向上發展,蠶食、擴充自己在AI的地盤,目前已經涵蓋服務器/嵌入式平臺,面向多個專用領域(自動駕駛、醫療健康、超算),具備極強的爆發力(從今年NVIDIA股票也能看出這一點)。










評論