基于支持向量機的車牌定位方法

3.1 特征提取
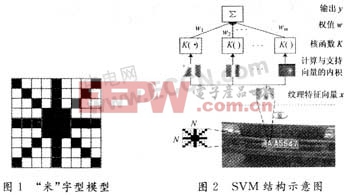
利用SVM自身結構可以實現有效的特征提取,選擇直接提取像素灰度特征。圖像像素點之間不是孤立的,相互之間存在著相關性,體現了一種紋理。可以通過提取一些特定像素的灰度值作為整幅圖像的特征,同時減少了計算量。首先將每幅圖像切割成若干個N×N子塊,再將每一子塊標注為牌照區域(+1)和非牌照區域(-1)兩類,然后使用圖1所示“米”字型模型提取像素灰度值(圖中陰影為要提取的像素點)。這樣每幅子圖的特征維數由N×N減少到4N-3,提高了訓練和分類速度。
3.2 SVM分類器
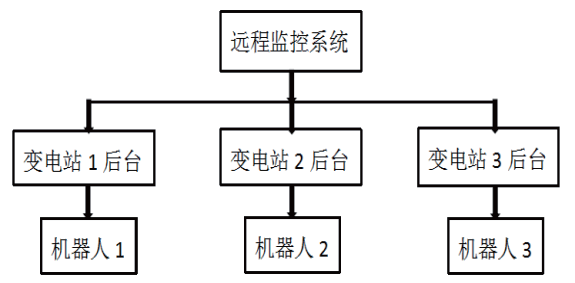
SVM分類器分為三層結構,結構示意見圖2。輸入層的維數為子圖的特征維數4N-3,輸入值是灰度值。隱含層的維數是由訓練獲得的支持向量決定,即由訓練階段自動獲得,而且二次規劃在凸集下的解是全局最優解,避免陷入局部最小。隱含層計算輸入向量與支持向量之間的內積,完成非線性映射,通過核函數一步來實現的。輸出層的輸出就是對隱層的輸出與權值ωi的乘積求和,權值aiyi也是在訓練中獲得的。
SVM中研究最多的核函數主要有三類:多項式、徑向基函數(RBF)和多層Sigmoid神經網絡。實驗中使用的是多項式核函數,形式為:
![]()
作為一種基于樣本學習的方法,我們希望訓練樣本集盡可能地大,以獲得比較充分的代表性。然而考慮到實際的限制,這個尺寸又必須是適中的。因此,問題就是如何構造一個全面又可行的訓練樣本集。對于車牌定位問題,所有包含牌照區域的圖像可以作為正樣本,困難點是收集負樣本,因為實際上存在太多的不包含牌照的圖像可以作為負樣本。如何在這些圖像中選取具有代表性的子集,實驗中采用了一種叫“自舉”(bootstrap)的方法,他已被Sung和Poggio成功地應用于人臉識別。主要思想就是一些負樣本(非牌照)是在訓練中獲得而不是在訓練以前,具體實現步驟如下:
(1)建立包含正樣本(牌照區域)和負樣本(非牌照區域)的訓練集合N1;
(2)用N1訓練SVM;
(3)用訓練好的SVM分類器對隨機選取的非牌照樣本進行分類測試,收集那些被錯分為牌照的樣本;
(4)隨機選取20%的錯分類樣本加入到訓練集N1;
(5)重復(2)~(4)步直至沒有再發現錯分的樣本;
(6)使用最終獲得的N1訓練SVM。



評論