基于FPGA 的多時鐘片上網絡設計

3 性能分析
利用Virtex-4 系列中XC4VLX100-11[4]設備進行設計, 利用Xilinx ISE 8.2i 進行綜合布局布線。使用ModelSim 6.1c[5]驗證所設計的功能。設置了單一時鐘和多時鐘進行了模擬,分析多時鐘片上網絡的性能。由于路由器是直接連接到內核, 所以沒必要考慮片與片之間的延時而去估計最高的頻率。所設計是由一個路由功能模塊(RFM)執行[6],用以準確地估計工作頻率,基本路由器的單機版工作頻率可到達357MHz。因此8bits 通道的路由器的吞吐量最高可達2.85Gbits/s。在所設計的路由器中, 頭數據片前進到下一個節點,而剩下的數據片以流水線方式流通。在計劃中,網絡延時僅僅與路徑長度H(跳躍點數量)有關。在信道爭用的情況下,網絡延時L 可以用以下方式計算:
L = 7×H + B/w (1)
公式(1)中,B 是數據包的字節數,w 是每個時鐘周期轉換的字節數。參數7 是在多時鐘片上網絡路由器中安裝在每個路由器跳延遲支付。這個延時是因為基于數據包中的頭數據片的解碼和仲裁執行所導致的。
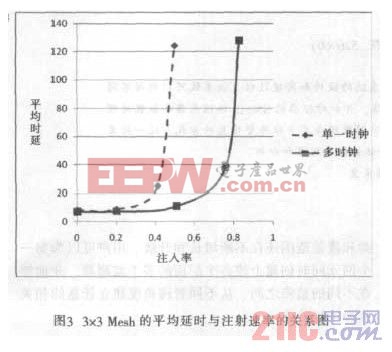
為了*估所設計的多時鐘架構的性能, 將利用所設計的路由器的VHDL 模型,模擬一個3×3Mesh 結構,在本身頻率下執行包裝產生的數據包。路由器的頻率值會在拓撲結構合成,布局和布線階段完成之后得出。對于不同的配置(資源的可用性、跨路由器的距離、bRAM/dRAM FIFO 的版本),路由器的頻率可以降低高達18%[6]。圖3 顯示了單一時鐘與多時鐘,在延時與注射速率關系中的曲線圖。在單一時鐘時,網絡的頻率為286MHz。而在多時鐘時, 頻率的范圍是從286MHz~357MHz。圖3 中,X 軸表示的注射率是在一個周期內每個節點注入flit 的數量。Y 軸曲線測量的是每個實例中數據包的平均延時。可以看出,所提出的多時鐘片上網絡相比單一時鐘片上網絡的性能顯著增加。
4 結語
本文介紹了一個基于FPGA 的高效率多時鐘的虛擬直通路由器,通過優化中央仲裁器和交叉點矩陣,以爭取較小面積和更高的性能。同時,擴展路由器運作在獨立頻率的多時鐘NoC 架構中,并在一個3×3Mesh 的架構下實驗,分析其性能特點,比較得出多時鐘片上網絡具有更高的性能。












評論