LDPC碼數據分配通用模塊設計方案

硬件實現的過稃中該參數的實現手段如圖4所示。本文引用地址:http://www.104case.com/article/153700.htm

經過對原數值的兩次移位,得到該數值的四分值,通過減法達到(1/λk)為0.75的目的。
4 通用化模塊設計
下面的討論不失一般性,以每個循環子矩陣巾有3組1為例進行說明。
如圖5所示。A,B,C 3條線從“初始列號”開始向右側進行編排,由于C線的ver_pos_C(ver_pos_A、ver_pos_B、ver_pos_C分別指循環子矩陣中每組1的列初始位置)值最大,即C線在最右端.這也就意味著在經過511—1—ver_pos_C(511是每個循環子矩陣的大小)行的運算之后,C線首先將要從最左邊重新開始循環。因此,下面進行的數據初始化順序從A,B,C,變為C,A,B,以此類推。
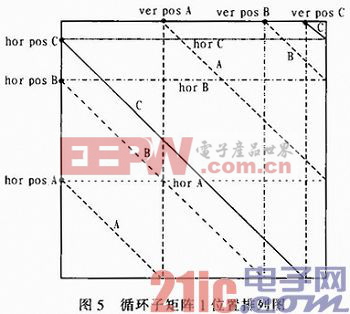
總而言之,每當排在最右側的一條線到達最右側的列時,下一步的CNU運算就將其變為本子矩陣的最先處理的數據。因為有這樣的運行規律,于是形象的稱這種運行方式為“反彈”。即,每當排在最右側的線碰撞到循環子矩陣的右側壁時便發生“反彈”,橫向處理數據的順序便進行一次向右的循環移位,將最右側線的數據移到最左邊,其他的數據順序不變。
如此循環,直到把該循環子矩陣中所有的“1”位置全部處理完畢。每當循環子矩陣中發生一次“碰壁”后“定位位”就加1。
想要知道每條線橫向的先后順序就需要用到前面提到的“穿越”方法。首先確定3條水平直線,3條水平直線位于hor_pos_A,hor_pos_B,hor_pos_C位置上,記為hor_A,hor_B,hor_C,如圖5所示。A,B,C 3條線從“初始行號”位置開始向右側進行編排,A,B,C中的每條線,每當穿越hor_A,hor_B,hor_C中的直線時,A,B,C的橫向計數便加1,因為每穿越一次除它本身之外的線時,在它左邊就多一條線。因此本方法稱之為“穿越”。
先以C線為例進行說明。C線從hor_pos_C點殲始,向右側移動,當C線的行號“穿越”第一個除hor_C以外的水平直線hor_B的時候.此時C線上數據的編號加1。
5 加入通用化模塊的高速譯碼實現方案
從上面的分析的出結論,當存儲器內的數據進行向右側的循環移位的時候,每當到達最右側,通用定位模塊檢測到這一信息便將通用定位模塊的輸出加1。存儲在定位位內。具體說明參見如圖6所示。
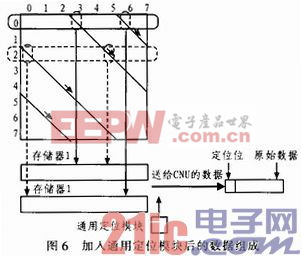
該圖說明了加入通用化定位模塊后的數據組成。仍以圖2所述矩陣為例,而且列初始位置小的一組1的數據從存儲器1中讀出,列初始位置大的一組1從存儲器2中讀出。當數據初始化到兩個存儲器內之后,進行水平運算的時候,首先提取第0行的數據以實線表示,此時的通用定位模塊的定位位輸出是0,輸出到CNU進行運算的數據前端的定位位也是0。隨著數據讀取的進行,當進行到以虛線表示的第2行進行數據讀取的時候,存儲器1對應那組1達到了存儲器的還沒有到達存儲器的最右側,而此時從存儲器2中讀出的數據已經經過了該存儲器的最右側,開始重新從最左邊讀數,因此定位位被通用定位模塊加1,變為1。
這樣進行數據的讀取工作,直到讀完該循環子矩陣中所有的數據,所有讀出的數據都在首位增加了一個“定位位”,然后被送往CNU參與水平運算。


評論