基于中英文數字語音登陸系統的仿真研究

引言
本文引用地址:http://www.104case.com/article/142175.htm語言是人與人之間在日常交往中最直接也是最強大的工具,然而我們并不滿足于人與人之間的對話,而是通過語音識別技術來實現人機對話,語音識別技術的終極目標就是能夠讓人類與計算機進行自由地交談。隨著語音識別技術的逐漸成熟及近些年來已經取得的進步,英文數字語音識別在其發展的20多年間已達到了很高的識別率,漢語數字語音識別也經過多年研究在PC平臺和實驗室條件下達到了高性能,但中英文混合連續數字語音識別還有待進一步研究,張晴晴等人研究的中英雙語混合語音識別的識別率為16.8%,遠低于理想中的識別率。為使識別效果達到可實用的水平,本系統首先從基本的中英文數字語音識別出發,從而為相應的登錄注冊系統做出一些嘗試。
本文研究的中英文連續數字語音識別,包含中文0-10和英文zero-ten的數字語音識別,其中包括對語音信號的預處理、特征參數提取、中英文聲學模型與語言模型的訓練及模版匹配等,適合于研究數字語音登錄系統,比如用戶用中英文任何語言念學號或是身份證號就能登陸,免去書寫的麻煩,同時也對后續研究中英文混合連續語音識別奠定了基礎。
語音識別原理
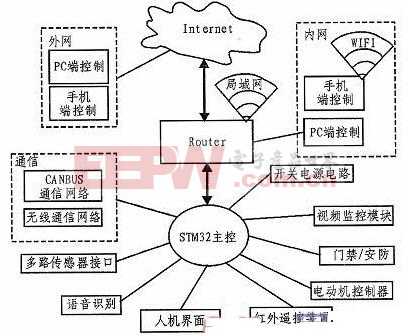
根據對說話人說話方式的要求,語音識別可以分為孤立字(詞)語音識別系統,連接字語音識別系統以及連續語音識別系統;根據對說話人的依賴程度,語音識別可以分為特定人和非特定人語音識別系統;根據詞匯量大小,又可以分為小詞匯量、中等詞匯量、大詞匯量以及無限詞匯量的語音識別系統。不同的語音識別系統,其目的和功能各不相同,但它們所采用的基本框架大體一致,語音識別基本流程如圖1。
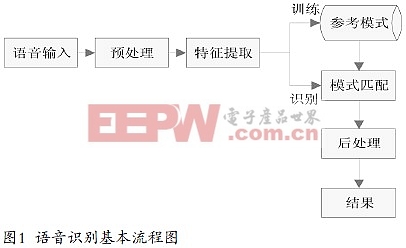
語音識別的過程,其本質就是模式匹配的過程。語音信號經過預處理、語音信號的特征提取、聲學模型的訓練與模式匹配后,經過處理輸出識別結果。其中:
1)預處理是對輸入的原始語音信號進行處理,濾除掉其中不重要的信息和背景噪聲,并進行語音信號的端點檢測、語音分幀以及預加重等處理。
2)特征提取主要負責計算語音的聲學參數,并進行特征的計算,以便提取出反映信號特征的關鍵特征參數,從而用于后續處理。因Mel頻率倒譜系數(MFCC)具有良好的抗噪性和魯棒性,故本文采用MFCC提取特征參數。
3)訓練階段是用戶通過輸入若干次訓練語音后,經預處理和特征提取后得到特征矢量參數,建立或修改訓練語音的參考模式庫。
4)識別階段是將輸入的語音提取特征矢量參數與參考模式庫中的模式進行匹配,得出最終的識別結果。





評論