ICLR2023 | 阿卜杜拉國王科技大學最新發布,3D表示新網絡:多視圖+點云!(2)

3D 計算機視覺和計算機圖形學的一個基本問題是如何表示 3D 數據。鑒于深度學習在 2D 計算機視覺領域的成功推動了深度學習在 3D 視覺和圖形領域的廣泛采用,這個問題變得尤為重要。
事實上,深度網絡已經在 3D 分類、3D 分割、3D 檢測、3D 重建和新穎的視圖合成。計算機視覺網絡依賴于直接 3D 表示、圖像上的間接 2D 投影或兩者的混合。
- 直接方法對通常以點云、網格或體素表示的 3D 數據進行操作。
- 相比之下,間接方法通常渲染對象或場景的多個 2D 視圖,并使用傳統的基于 2D 圖像的架構處理每個圖像。人類視覺系統更接近這種用于 3D 理解的多視圖間接方法,因為它接收渲染圖像流而不是顯式 3D 數據。
使用間接方法處理 3D 視覺任務具有三個主要優勢:
- (i) 成熟且可遷移的 2D 計算機視覺模型(CNN、Transformers 等);
- (ii) 用于預訓練的大型和多樣化標記圖像數據集(例如 ImageNet);
- (iii) 多視圖圖像根據視角提供豐富的上下文特征,這與幾何 3D 鄰域特征不同。
多視圖方法在 3D 形狀分類和分割方面取得了令人印象深刻的性能。然而,多視圖表示(尤其是密集預測)的挑戰在于將每個視圖的特征與 3D 點云正確聚合。需要進行適當的聚合以獲得具有代表性的 3D 點云,每個點具有適用于典型點云處理管道的單個特征。
以前的多視圖工作依賴于將像素映射到點后的啟發式方法(例如平均或標簽模式池化),或與體素的多視圖融合。由于某些原因,此類設置可能不是最佳設置。
- (i) 這種啟發式方法可能會匯總從中獲得的誤導性預測信息任意觀點。例如,從底部看一個對象并獨立處理該視圖,當與其他視圖結合時,可能會攜帶有關該對象內容的錯誤信息。
- (ii) 視圖缺少幾何 3D 信息。
為此,本文提出了一種新的混合 3D 數據結構,它繼承了點云的優點(即緊湊性、靈活性和 3D 描述性),并利用了多視圖投影豐富的感知特征的優勢。將這種新表示稱為多視圖點云(或 Voint cloud),并在圖 1 中進行了說明。
Voint cloud是一組 Voint,其中每個 Voint 是一組與視圖相關的特征(視圖特征),對應于3D 點云中的相同點。這些視圖特征的基數可能因一個 Voint 而異。在表1 中,比較了一些廣泛使用的 3D 表示和我們的 Voint cloud表示。
Voint cloud繼承了顯式 3D 點云的特征,這有助于學習用于各種視覺應用(例如點云分類和分割)的 Voint 表示。為了在新的 Voint 空間上部署深度學習,定義了 Voint 上的基本操作,例如池化和卷積。
基于這些操作,定義了一種構建 Voint 神經網絡的實用方法,稱之為 VointNet
- VointNet 采用 Voint 云并輸出點云特征以進行 3D 點云處理。
- 本文展示了學習這種 Voint 云表示如何在 ScanObjectNN 和 ShapeNet。
(i) 本文提出了一種新穎的多視圖3D點云表示方法,稱為Voint cloud。在這種表示方法中,每個點(即Voint)由來自不同視角的一組特征表示。
(ii) 本文在Voint級別定義了池化和卷積運算,用于構建Voint神經網絡(VointNet )。VointNet 能夠學習從Voint空間中的多個視圖聚合信息。
(iii) 本文的VointNet 在多個3D理解任務上取得了最好的性能,包括3D形狀分類、檢索和穩健的部分分割。此外,VointNet 還實現了對遮擋和旋轉的魯棒性改進。通過引入Voint cloud表示和VointNet 網絡,在處理3D點云數據時取得了顯著的改進,并在多個任務中取得了優越的性能,提高了對復雜3D場景的理解和分析能力。
相關背景3D 點云的學習3D點云學習是計算機視覺中廣泛應用的一種方法,而點云由于其緊湊、靈活性以及可以通過LiDAR和RGB-D相機等傳感器自然獲取的特點,在3D表示中被廣泛使用。
- PointNet是第一個能夠直接在3D點云上進行深度學習的算法,為后續的研究奠定了基礎。它獨立地計算點的特征,并使用順序不變函數(例如最大池化)對這些特征進行聚合。隨后的研究工作主要集中在尋找點的鄰域來定義點卷積運算。
- 近期的研究工作將點云表示與其他3D模態進行了結合,例如體素或多視圖圖像。
在這項研究中,本文提出了一種新穎的表示方法,稱為Voint cloud,用于3D形狀表示,并研究了一種新穎的架構,用于在3D點級別聚合視圖相關的特征。通過引入Voint cloud表示和相關架構,對3D點云的學習和表示提出了新的方法,進一步推動了這一領域的發展。
3D 多視圖多視圖應用最初是于1994年提出的,使用2D圖像來理解3D世界。這種直觀的多視圖方法與MVCNN(Multi-View Convolutional Neural Networks)中的3D理解深度學習相結合。隨后,一系列工作通過改進每個圖像視圖的視圖特征的聚合,繼續開發用于分類和檢索的多視圖方法。
在本文中,將多視圖的概念融合到3D結構本身中,使每個3D點根據可用的視點具有一組獨立的視圖特征。Voints與采樣的3D點云對齊,提供緊湊的表示形式,既能高效計算和節省內存,又保持了視圖相關的組件,促進了基于視圖的視覺學習。
3D數據的多視圖混合在一些3D語義分割任務中,也有一些方法嘗試采用多視圖方法。然而,當組合視圖特征以表示局部點或體素并保留局部幾何特征時,會遇到問題。這些方法往往會對視圖特征進行平均、僅標簽、從鄰域中的重建點學習、對單個網格上的點進行排序,或將多視圖特征與3D體素特征相結合。
因此,本文提出的VointNet 在Voint cloud空間中運行,同時保留了原始點云的緊湊性和3D描述性。VointNet 利用多視圖功能的強大能力,并學習將視圖特征獨立應用于每個點并進行聚合。這樣的設計使得VointNet 在多視圖任務上取得了良好的性能表現。
Method 方法Pipeline研究工作中的主要假設是表面 3D 點是球面函數,即它們的表示取決于觀察它們的視角。這種情況與大多數假設 3D 點云的視圖獨立表示的 3D 點云處理Pipeline形成對比。完整的Pipeline如下圖所示。
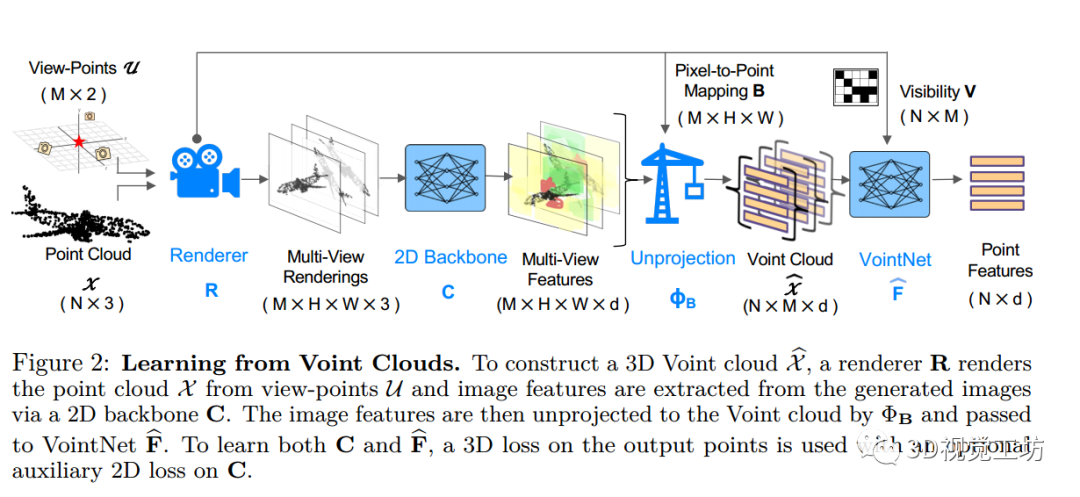
從點云到 Voint cloud —— From Point Clouds to Voint clouds圖2:從 Voint cloud中學習。
- 為了構建 3D Voint cloud ,渲染器 從視點 渲染點云 ,并通過 2D 主干 從生成的圖像中提取圖像特征。
- 然后,圖像特征通過 投影到 Voint 云并通過到VointNet 。
- 為了學習 和 ,輸出點上的 3D 損失與 上可選的輔助 2D 損失一起使用。
3D點云是由3D對象或場景表面上的采樣點組成的緊湊3D表示,可以通過不同的傳感器獲取,如LiDAR或重建結果。
- 將曲面 的坐標函數定義為連續歐氏空間中的符號距離函數(SDF),然后將3D等值面定義為滿足 條件的所有點 的集合。
- 將表面3D點云 定義為一組 個3D點,其中每個點 由其3D坐標 表示,并滿足等值面條件 。
在本文中,目標是將視圖依賴性融合到3D點中。受到NeRFs(Neural Radiance Fields)的啟發,假設表面點的特征也取決于觀察它們的視角方向。
- 具體而言,引入一個連續的隱式球函數 ,它根據視角方向u定義每個點x的特征。
- 給定一組M個視角方向 ,Voint 是一組M個與視角相關的特征,用于描述以點x為中心的球體。
- 點云 表示父點云X中每個點 的集合。
- 需要注意的是,通常我們無法直接訪問底層的隱式函數,因此通過以下三個步驟對其進行近似。
Voint 將同一個 3D 點的多個視圖特征結合在一起。這些視圖特征來自于點云渲染器 對點云 進行多視圖投影的結果:。
- 它將來自多個視點 的點云 渲染為大小為 的 個圖像,每個像素包含三維信息。
- 除了將點云投影到圖像空間,渲染器 還定義了每個像素與其對應的 個點和背景之間的索引映射 。
此外,渲染器 R 還為每個視圖的每個點輸出可見性二元矩陣 。
- 由于像素的離散化,不是所有的點都會在所有的視圖中出現,因此可見性分數 定義了 Voint 在視圖 中是否可見。
- 矩陣 對于非投影操作至關重要,而矩陣 是定義 Voints 上有意義的操作所必需的。
渲染圖像通過函數 進行處理:,提取圖像特征,具體示意如圖2所示。
- 如果函數 是恒等函數,那么所有視圖特征通常對應于點的 RGB 值。
- 然而,函數 可以是專門針對下游任務的2D網絡,它可以提取關于每個視圖的有用的全局和局部特征。
本文提出了一個模塊 ,用于將每個像素的2D特征反投影為相應點的3D視圖特征。利用由渲染器創建的映射, 形成Voint云特征 。
總之,輸出的Voint云可以用方程(1)描述,其中 ,當 時,特征僅對Voint 的視圖 定義。
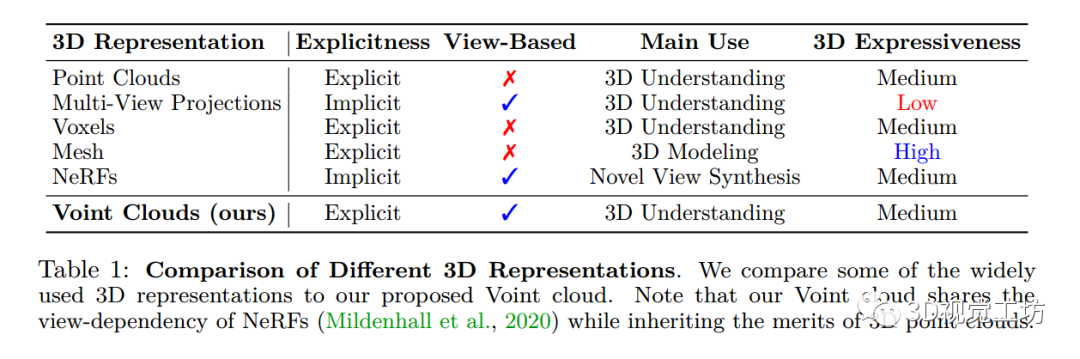
3D Voint clouds 上的操作 —— Operations on 3D Voint clouds表 1:不同 3D 表示的比較。
- 將一些廣泛使用的3D 表示與本文提出的 Voint 云進行了比較。
- 請注意, Voint 云共享 NeRF 的視圖依賴性,同時繼承了 3D 點云的優點。
在附錄中,展示了一組角度的最大池化單個視圖特征的函數形式可以近似球坐標中的任何函數。
本文提供了一個定理,該定理擴展了 PointNet 的點云函數組合定理及其對 Voints 基礎球函數的通用逼近。
接下來,在 Voint 上定義一組操作作為 Voint 神經網絡 (VointNet ) 的構建塊。
池化—— VointMax將 VointMax 定義為沿 voint 的視圖維度在可見視圖特征上的最大池化。對于所有 和 ,
*博客內容為網友個人發布,僅代表博主個人觀點,如有侵權請聯系工作人員刪除。






