預測熱門歌曲成功率 97%?這份清單前來「打假」

單看數據結果是不夠的,要仔細判斷這些數據的可靠性。
預測風口、潮流是每個行業都熱衷的事情。這可以讓從業人員第一時間掌握行業的最新動向,成為行業某一時段的領軍者。
音樂行業也同樣如此。音樂公司都希望自己能夠預測到下一次的音樂潮流,準確地挑選出下一首熱門歌曲,賺個盆滿缽滿。那實現這種預測是可能的嗎?
據《 Scientific American》與 《Axios》報道,這樣的模型真的出現了,介紹它的論文甚至被稱為可以改變音樂產業的文章。97% 的超高預測成功概率,能夠讓音樂公司不必再層層篩選,耗時耗力,而是通過模型就能夠高效地預測出下個音樂「時尚單品」。這樣的好辦法何樂而不為呢?

事實真的如此嗎?
在這篇論文發出前,已經有一些研究表示,音樂欣賞作為主觀性極強的事情,任何結果都是有可能的:最好的歌曲很少表現不佳,最差的歌曲很少表現良好,但不代表這些情況全然不會出現。
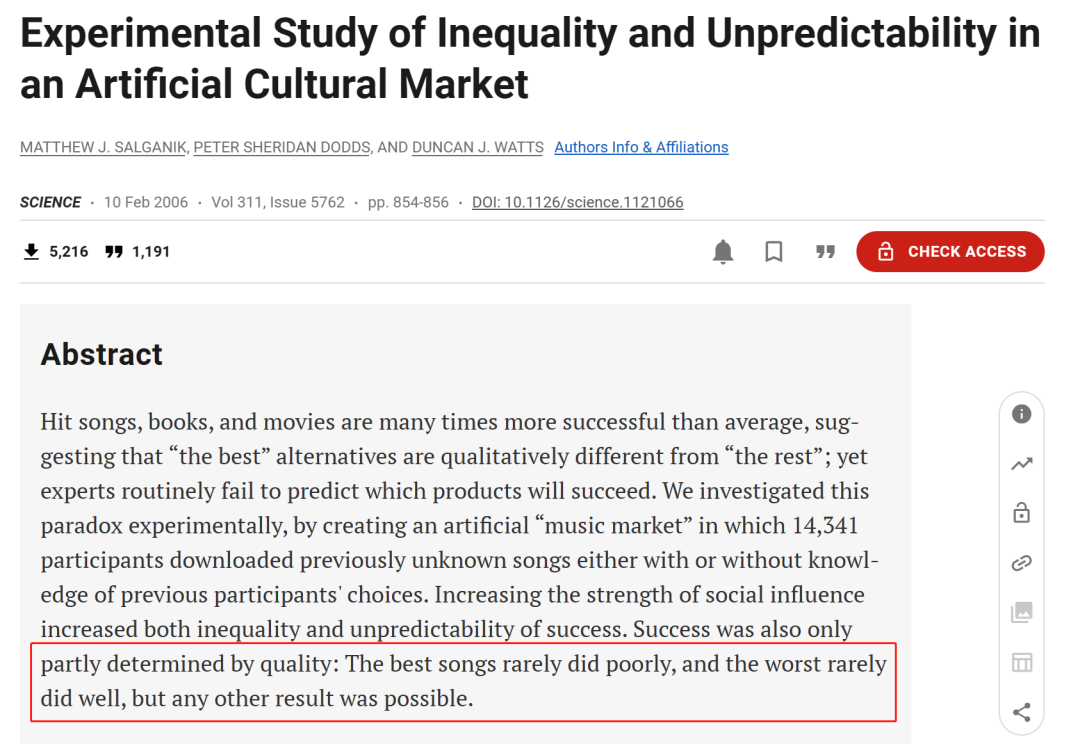
甚至有文章直接表示「本文認為,音樂預測還不是一項數據科學活動」。
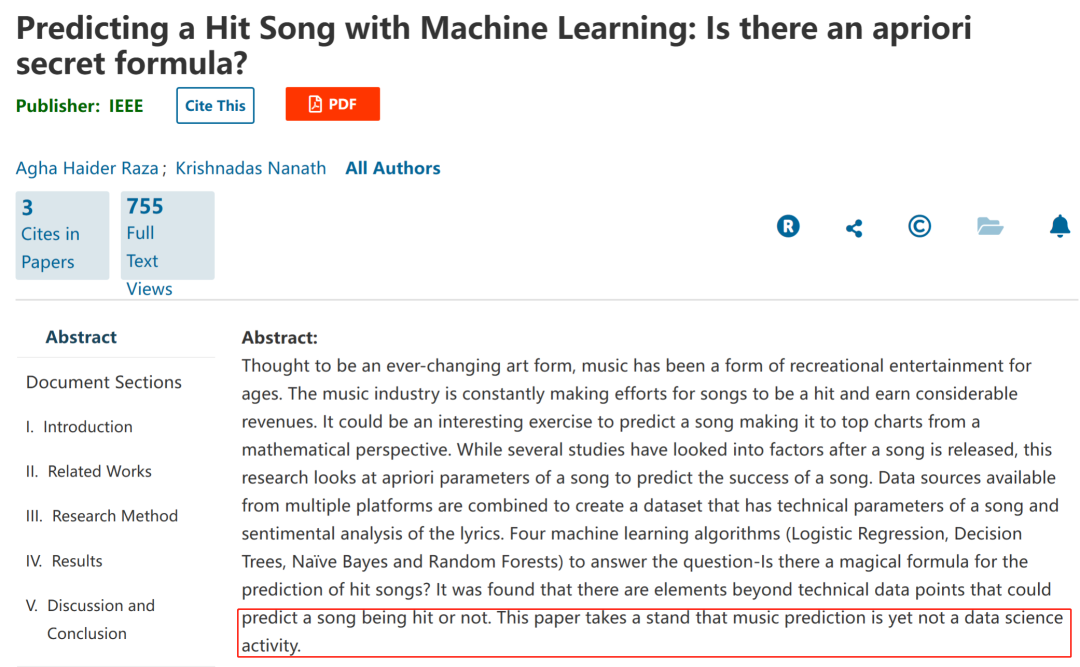
那么 97% 的預測成功概率如何實現的?是我們高估了預測難度還是低估了模型的能力?
有人指出,實際上并非如此。其實,人們現在還是無法用機器學習的方法來預測熱門音樂。

文章地址:https://reproducible.cs.princeton.edu/predicting-hits.html
文中指出了這個預測熱門音樂高準確率論文的紕漏:
論文作者使用了 33 位聽眾對 24 首歌曲的反應數據。他們的初始數據集由 24 個樣本組成,每首歌曲一個樣本。對于每首歌,模型只依賴三個特征來預測它是否會成為熱門歌曲,這些特征的值取所有聽眾的平均值。他們利用這個數據集,通過一種叫做 「過度采樣 」的方法,創建了一個包含 10000 個樣本的合成(假)數據集。測試機器學習模型的主要考慮因素之一是,其訓練數據應與評估數據應該完全分開。而本文的關鍵錯誤就在于,這種訓練 - 測試分離是在數據已經過采樣之后進行的。因此,訓練數據和測試數據之間的相似度遠遠高于包含其他歌曲的新數據集。換句話說,論文沒有提供模型在新歌曲上表現如何的證據。
當我們在作者發布的原始數據上修正這個誤差后測試模型時,模型的準確性比隨機好不了多少。我們還發現,使用作者的合成數據集,準確率實際上可以達到 100%。這并不奇怪:由于超采樣程度如此之高,使用訓練或測試分集都有可能重建原始數據。換句話說,他們是在基本相同的數據上進行訓練和測試。
可見,97% 這個數據雖然看著不錯,但可信度非常低,它并不能代表一個模型的能力,也并不證明音樂可以真正被預測。
這篇論文中介紹的模型存在機器學習中最常見的缺陷之一:數據泄漏。這意味著,模型是在與訓練數據相同或相似的數據上進行評估的,這就夸大了對準確性的估計。在實際應用中,效果就會大打折扣。這相當于開卷考試 97 分的同學突然要閉卷考試,那么 97 分就不能作為衡量這位同學的成績了。
其實數據泄漏這樣的錯誤不僅僅出現在這一篇文章里。很多文章,甚至很多領域都出現了這種錯誤。
例如就在上個月, 2020 年的一篇著名腫瘤學論文中發現滲漏。而這篇文章發表在最負盛名的科學期刊之一《自然》上,而在發現錯誤之前已經積累了上百次的引用。

論文地址:https://www.biorxiv.org/content/10.1101/2023.07.28.550993v1.full.pdf
該研究報告了微生物與 33 種不同癌癥類型之間的強相關性,并創建了機器學習預測器,其區分癌癥的準確性接近完美。我們發現報告的數據和方法至少存在兩個根本性的缺陷:
(1)基因組數據庫和相關計算方法的錯誤導致所有樣本中出現了數百萬個細菌讀數的假陽性結果,這主要是因為大多數被鑒定為細菌的序列實際上是人類的
(2)原始數據轉換中的錯誤產生了一種人工特征,即使是對沒有檢測到讀數的微生物也是如此,它為每種腫瘤類型標記了一個獨特的信號,機器學習程序隨后利用這個信號創建了一個表面上準確的分類器。
這些問題都使結果無效,從而得出結論:研究中提出的基于微生物組的癌癥識別分類器是完全錯誤的。這些問題隨后又影響了其他十幾項已發表的研究。這些研究使用了相同的數據,其結果很可能也是無效的。
機器學習中常出現的問題
泄漏是基于 ml 的科學中的許多錯誤之一。這樣的錯誤很常見的一個原因是,機器學習在各個科學領域中被隨意采用,論文中報告機器學習結果的標準沒有跟上步伐。過去在其他領域的研究發現,報告標準有助于提高研究的質量,但在少數領域以外的基于機器學習的科學中,這種標準并不存在。
除了泄漏外,解釋錯誤同樣也是一個常見的錯誤,這與論文中如何描述研究結果以及他人如何理解研究結果有很大關系。
一篇系統性綜述發現,提出臨床預測模型的論文通常會對其研究結果進行編造 — 例如,聲稱某個模型適合臨床使用,但卻沒有證據表明該模型在其測試的特定條件之外也有效。這些錯誤并不一定夸大了模型的準確性。相反,它們夸大了模型可以在何時何地有效使用。

綜述地址 https://www.sciencedirect.com/science/article/pii/S0895435623000756
另一個經常出現的疏忽是沒有明確模型輸出的不確定性水平。錯誤判斷會導致對模型的錯誤信任。許多研究沒有精確定義被建模的現象,導致研究結果的含義不明確。

相關論文地址:https://arxiv.org/abs/2206.12179
清單 REFORMS
既然這些錯誤這么常見,有沒有什么辦法可以避免呢?
有團隊做出了清單 REFORMS((Reporting standards for Machine Learning Based Science) ,供大家參考,并能夠最大限度地減少基于機器學習的科學研究中的錯誤,以及在錯誤悄然出現時使其更加明顯。現在公開的是預印本。

文章地址:https://reforms.cs.princeton.edu/
這是一份包含 8 個模塊、32 個項目的核對表,對開展機器學習科學研究的研究人員、審閱科學研究的裁判員以及提交和發表科學研究的期刊都有幫助。該清單由計算機科學、數據科學、社會科學、數學和生物醫學研究領域的 19 位研究人員共同制定。作者的學科多樣性對于確保這些標準在多個領域都有用至關重要。
這 8 個板塊及 32 個項目如下所示,如果你也正在進行著相關研究,可以作為參考。





當然要解決基于計算機科學研究的所有缺陷,僅靠一份檢查清單是遠遠不夠的。但是考慮到錯誤的普遍性和缺乏系統的解決方案,該團隊這樣的一份清單是被迫切需要的。
參與清單制作的成員指出,如果基于計算機科學的研究都使用這份清單自查,那他們就不會費力給豬涂口紅了(比喻想要把丑陋的事物變美好而做的無用功)。
*博客內容為網友個人發布,僅代表博主個人觀點,如有侵權請聯系工作人員刪除。






