獨家 | 使用檢索增強生成技術構建特定行業的 LLM

企業正在競相采用大型語言模型(也可以被稱為LLM)。讓我們深入了解如何通過RAG(檢索增強生成技術) 構建特定行業的大型語言模型。
公司可以通過使用像ChatGPT 這樣的大語言明星提高生產力。但是試著問 ChatGPT "美國目前的通貨膨脹率是多少",它會給出答案:
很抱歉造成您的困惑,作為一個人工智能語言模型,我不具備實時數據的瀏覽能力。我的回答是基于截至 2021 年 9 月的信息。因此,我無法為您提供美國當前的通貨膨脹率。
這是一個問題。ChatGPT顯然缺少及時相關的背景信息,而這對于做出明智的決策至關重要。
微軟如何解決這一問題在微軟 Build 會議 "矢量搜索還不夠"(Vector Search Isn't Enough)中,他們介紹了自己的產品,該產品將上下文感知較弱的LLM 與矢量搜索結合起來,以創造更有吸引力的體驗。
演講的出發點與本文相反—他們從彈性搜索(或矢量搜索)的角度出發,認為搜索本身是有限的,而添加LLM 層可以極大地改善搜索體驗。
其基本想法是,在LLM 中添加相關上下文可以極大地改善用戶體驗,尤其是在大多數商業案例中,因為LLM 并沒有見過此類數據。當您擁有海量數據,包括 100 多份(或更多)文檔時, 矢量搜索有助于選擇相關上下文。
矢量搜索 101
矢量搜索101 | Skanda Vivek
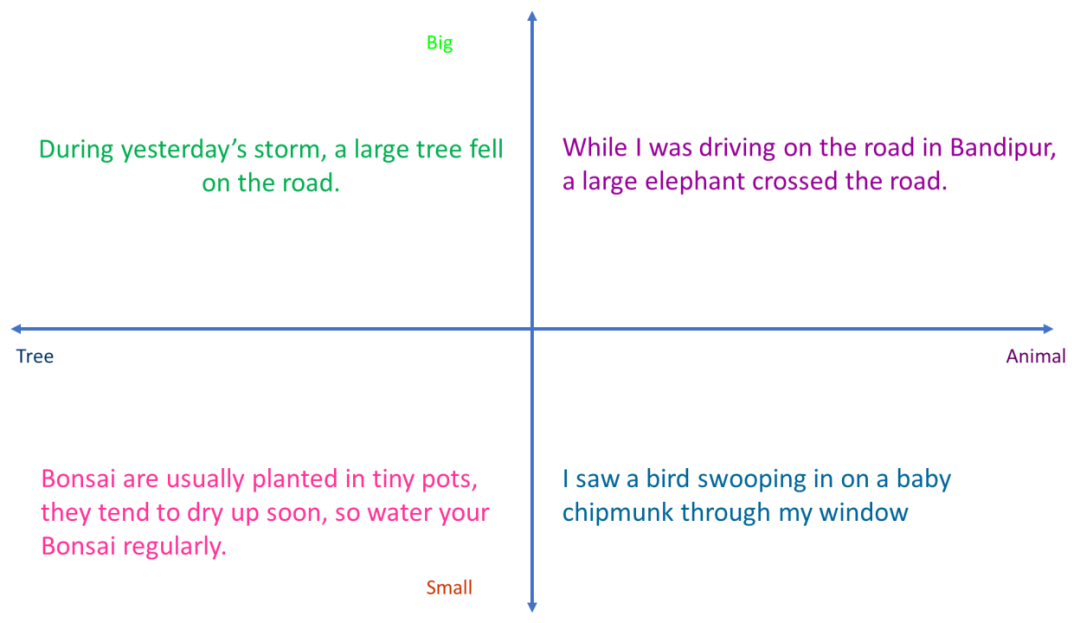
矢量化是將數據轉換成多維向量。在上面的案例中,您可以看到2個維度:尺寸和類型。尺寸有 2 種(小或大),類型有 2 個種(樹或動物)。這只是一個概念性的例子,當然矢量化也可以擴展到數百個維度(或更多值)。
句子的矢量搜索101 | Skanda Vivek
您也可以用單詞或句子代替圖片來做同樣的事情。請注意,在上述示例中,矢量化能夠捕捉語義表征,即它知道關于一只鳥俯沖向一只花栗鼠寶寶的句子應該位于(小鼠,動物)象限,而關于昨天暴風雨時一棵大樹倒在路上的句子應該位于(大,樹)象限。實際上,嵌入的維度不止 2 個--而是384個(句子或文本塊通過BERT 變換器,輸出 384個與384維相對應的數字)
矢量搜索 + LLM (RAG)矢量搜索現在在所有的搜索中都很普遍(谷歌、必應,以及您最喜歡的搜索引擎)。想一想,如果您的整個搜索數據庫中只有這4 個文檔,您可以問這樣一個問題:"請告訴我關于一棵大樹的事情。您可以問這樣一個問題:"請告訴我關于一棵大樹的事情"。
那么輸出為:
在昨天的暴風雨中,一棵大樹倒在路上。
只是數據庫中最相關的文檔。但如果您向LLM提出同樣的問題(并在最后添加 4 個 "文檔"),您將得到以下結果:
(本例中為ChatGPT):
大樹通常是一種高聳的大型植物,具有粗壯的樹干、樹枝和廣泛的根系網絡。這些樹木可以達到令人印象深刻的高度, 通常遠遠高于周圍的植被。它們是許多生態系統的重要組成部分,為各種生物提供樹蔭、庇護所和食物。
您提到的暴風雨中大樹倒在路上的事件表明了惡劣天氣條件的威力和影響。強風暴雨會將樹木連根拔起或折斷,導致道路堵塞,給車輛和行人帶來潛在危險。
在您提到的另一種情況下,當您在班迪布爾(Bandipur) 的公路上行駛時,遇到一頭大象橫穿馬路。班迪普爾是位于印度的一個國家公園和野生動物保護區,以其豐富的生物多樣性和多樣的動物而聞名。大象是班迪普爾的主要物種之一,它們經常穿越該地區,有時還會橫穿馬路。這樣的邂逅凸顯了野生動物保護的重要性,以及人類在自然棲息地與動物共存的必要性。
說到盆景,它們是生長在小盆中的微型樹木,經過精心造型和修剪以保持其小巧的體型。盆景栽培是一種古老的藝術形式,起源于東亞,現已風靡全球。由于根部空間有限,盆景景樹要定期澆水以防止干枯。小盆會導致土壤迅速干燥,因此監測濕度并相應地澆水至關重要。
最后,您提到透過窗戶觀察到一只鳥俯沖一只小花栗鼠。這種觀察反映了大自然的一個行動瞬間,一只鳥可能正在覓食。眾所周知,猛禽和某些鳥類(如鷹或貓頭鷹)會俯沖花栗鼠等小型哺乳動物,這是它們自然狩獵行為的一部分。目睹這種互動令人著迷,因為它們能讓我們對動物王國的活力有更深的了解。
總之,這些自然片段--無論是涉及大樹、大象、盆景樹還是鳥類捕食--都突出了我們周圍自然世界的多樣性和奇妙性。
這個答案似乎更加全面。ChatGPT使用的是在數萬億文檔中訓練出來的內部知識,并結合了所給的上下文。
但是,假設您有不止4個文檔--也許是成千上萬個,您無法在ChatGPT 提示中找到。在這種情況下,您可以使用矢量搜索來縮小最有可能包含答案的上下文范圍,并將其附加到提示中, 然后提出如下相同的問題:
這是它現在給出的(截斷的)答案:

ChatGPT answer | Skanda Vivek
您可以有一個數據庫,存儲文檔和嵌入。另一個數據庫存儲查詢,并根據查詢找到最相關的文檔:
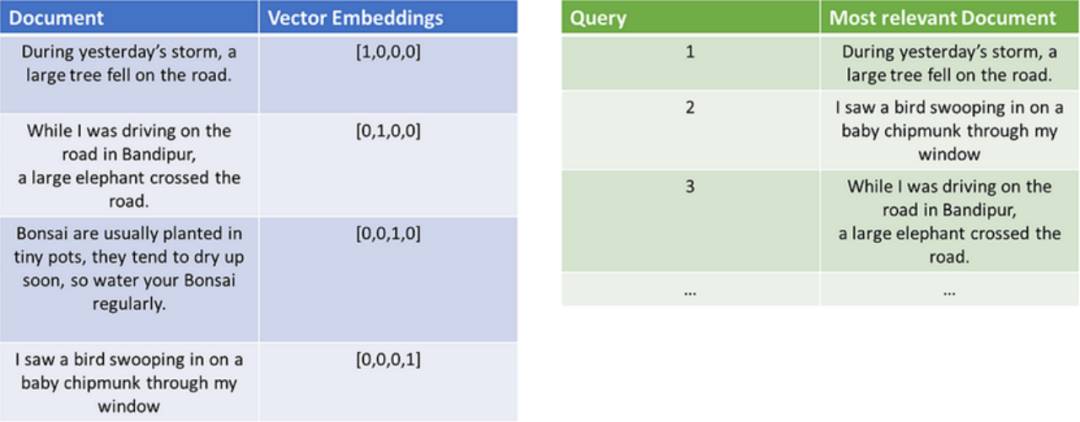
Document DB (左)和 Quey DB (右) | Skanda Vivek
一旦您通過查詢獲得了最相似的文檔,您就可以將其輸入到任何LLM,如ChatGPT。通過這個簡單的技巧,您就利用文檔檢索增強了您的 LLM!這也被稱為檢索增強生成(RAG)。
使用 RAG 建立特定行業的問答模型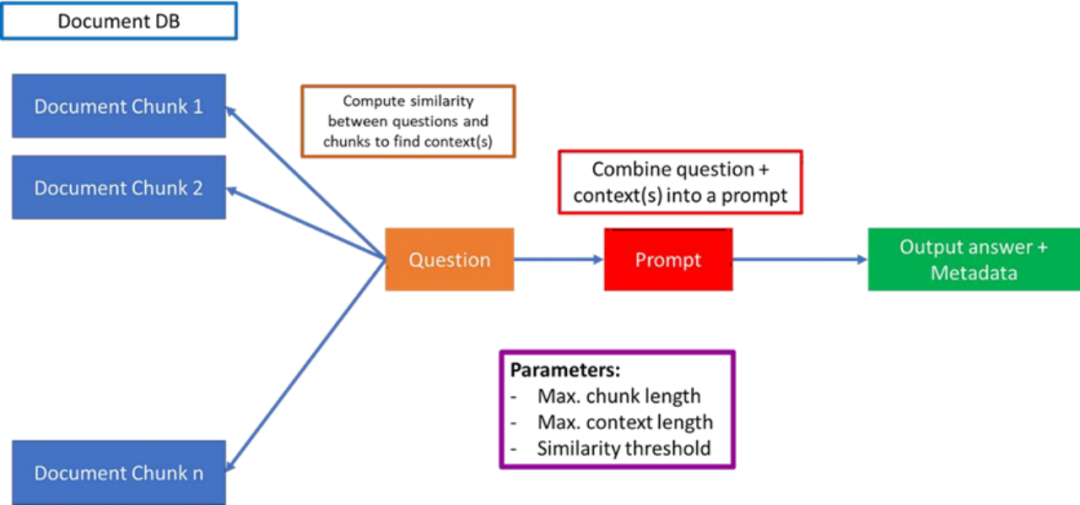
RAG原型 | Skanda Vivek
上圖概述了如何構建一個基本的RAG,利用自定義文檔的LLM進行問題解答。第一部分是將多個文檔分割成易于管理的塊,相關參數是最大分塊長度。這些塊應該是包含典型問題答案的典型(最小)文本大小。這是因為有時您提出的問題可能在文檔的多個位置都有答案。例如,您可能會問"X 公司從2015 年到 2020 年的業績如何?而您可能有一個大型文檔(或多個文檔),在文檔的不同部分包含了公司多年來業績的具體信息。在理想情況下,您希望捕獲包含這些信息的文檔的所有不同部分,將它們連接在一起,并根據這些經過過濾和連接的文檔塊傳遞給 LLM 進行回答。
最大上下文長度基本上是將各種語塊連接在一起的最大長度--為問題本身和輸出答案留出一些空間(請記住,像 ChatGPT 這樣的 LLM 有嚴格的長度限制,包括所有內容:問題、上下文和答案。
相似度閾值是將問題與文檔塊進行比較的方法,以找到最有可能包含答案的頂級文檔塊。余弦函數是典型的度量方法,但您可能希望使用不同的度量方法。例如,包含關鍵詞的上下文的權重更高。例如,當您向LLM 提出總結文檔的問題時,您可能希望對包含 "摘要 "或 "總結 "字樣的上下文進行加權。
如果您想通過一種簡單的方式測試自定義文檔上的生成式問答,請查看我的API (https://rapidapi.com/skandavivek/api/chatgpt-powered-question-answering-over-documents)和在后臺使用 ChatGPT 的代碼(https://github.com/skandavivek/web-qa)。
由 RAG 推動的 ChatGPT 原型機讓我們通過一個例子來說明RAG的作用。EMAlpha 是一家調研新興市場的公司--基本上是印度、中國、巴西等新興國家的經濟(完全披露--我是 EMAlpha 的顧問)。該公司正在開發一個由 ChatGPT 支持的app,根據用戶輸入生成對新興經濟體的觀點。儀表盤看起來像這樣--你可以比較 ChatGPT 和RAG 版ChatGPT(EM-GPT)的輸出,后者能夠在后臺查詢國際貨幣基金組織(IMF)的金融文件:

EMAlpha中的EM-GPT 從|斯坎達-維韋克
以下是ChatGPT 對 "尼泊爾每年的 GDP 是多少?"這個問題的回答:

ChatGPT回答| Skanda Vivek
ChatGPT 只返回 2019 年之前的 GDP,它說如果您想了解更多信息,請訪問 IMF。但是,如果您想知道這些數據在IMF 網站的什么位置,那就很難了,您需要對網站上的文件存儲位置有所了解。經過一番搜索,您會發現文件就在這里。即便如此,要想知道 GDP 信息到底在哪里,也需要進行大量的滾動。
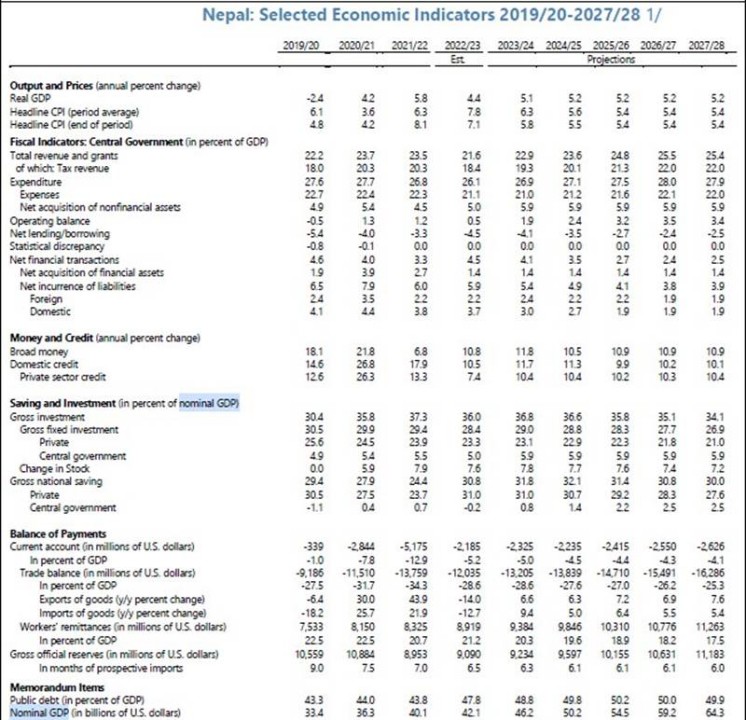
國際貨幣基金組織關于尼泊爾經濟的文件| Skanda Vivek
你可以看到,找到這些數據是很難的。但是,當您向 EM-GPT 提出同樣的問題時,它會追蹤相關上下文,并找到如下答案:
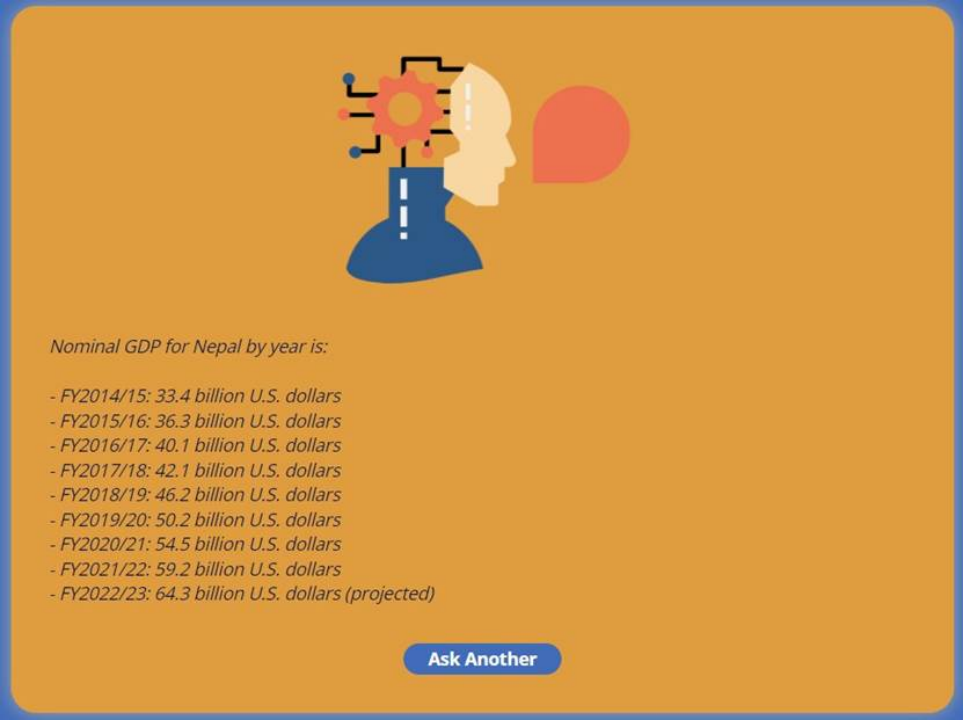
EM-GPT答案 | Skanda Vivek
下面是發送給ChatGPT 回答這個問題的確切提示。令人印象深刻的是,它能夠理解這些格式化的文本,提取正確的信息,并將其格式化為人類可讀的格式!

使用基于查詢的上下文進行聊天GPT 提示 | Skanda Vivek
我花了半個小時才在IMF網站上找到這些信息,而 RAG 修改后的 ChatGPT 只花了幾秒鐘。僅靠矢量搜索是不行的,因為它最多只能找到 "名義 GDP"這個詞,而不能將數字與年份聯系起來。ChatGPT 已經在過去的多個此類文檔中接受過訓練,因此一旦添加了相關上下文,它就知道文本的哪些部分包含答案,以及如何將答案格式化為可讀的格式。
結論RAG提供了一種在自定義文檔中使用LLM 的好方法。微軟、谷歌和亞馬遜等公司都在競相開發企業可以”即插即用“的應用程序。然而,該領域仍處于起步階段,在自定義文檔上使用矢量搜索驅動的 LLM 的特定行業應用程序可以成為先行者,并在競爭中脫穎而出。
當有人問我應該使用哪種LLM,以及是否要對自定義文檔進行微調或完全訓練模型,他們低估了LLM 和矢量搜索之間的同步工程的作用。以下是一些可以顯著提高或降低響應質量的注意事項:
1. 文檔塊的長度。如果正確答案更有可能包含在文本的不同部分,并且需要拼接在一起,則應將文檔分割成較小的塊,以便在查詢時附加多個上下文。
2. 相似性和檢索度量。有時,單純的余弦相似性是不夠的。例如,如果許多文檔包含關于同一主題的相互矛盾的信息,您可能希望根據這些文檔中的元數據將搜索限制在某些文檔上。因此,除了相似度之外,您還可以使用其他過濾指標。
3. 模型結構。我所展示的架構只是一個原型。為了提高效率和可擴展性,必須考慮各個方面,包括矢量嵌入模型、文檔數據庫、提示、LLM 模型選擇等。
4. 避免幻覺。您可能已經注意到我上面展示的例子幾乎是正確的。增強的 ChatGPT 得到了尼泊爾GDP 的正確數字--但是年份錯了。在這種情況下,需要在選擇提示、以更好的格式提取數據、評估出現幻覺的案例比例以及有效的解決方案之間進行大量的反饋。
現在,您已經知道如何將LLM應用到您的自定義數據中,去構建基于 LLM 的超棒產品吧!
原文標題:Pandas 2.0: A Game-Changer for Data Scientists?
原文鏈接:Build Industry-Specific LLMs Using Retrieval Augmented Generation | by Skanda Vivek | May, 2023 | Towards Data Science
*博客內容為網友個人發布,僅代表博主個人觀點,如有侵權請聯系工作人員刪除。






