混合密度網絡(MDN)進行多元回歸詳解和代碼示例(2)

兩個模型都沒有成功的主要原因是:對于同一個 X 值存在多個不同的 y 值……更具體地說,對于同一個 X 似乎存在不止一個可能的 y 分布。回歸模型只是試圖找到最小化誤差的最優函數,并沒有考慮到密度的混合,所以 中間的那些X沒有唯一的Y解,它們有兩種可能的解,所以導致了以上的問題。
現在讓我們嘗試一個 MDN 模型,這里已經實現了一個快速且易于使用的“fit-predict”、“sklearn alike”自定義 python MDN 類。如果您想自己使用它,這是 python 代碼的鏈接(請注意:這個 MDN 類是實驗性的,尚未經過廣泛測試):https://github.com/CoteDave/blog/blob/master/Made%20easy/MDN%20regression/mdn_model.py
為了能夠使用這個類,有 sklearn、tensorflow probability、Tensorflow < 2、umap 和 hdbscan(用于自定義可視化類 功能)。
EPOCHS = 10000
BATCH_SIZE=len(X)
model = MDN(n_mixtures = -1,
dist = 'laplace',
input_neurons = 1000,
hidden_neurons = [25],
gmm_boost = False,
optimizer = 'adam',
learning_rate = 0.001,
early_stopping = 250,
tf_mixture_family = True,
input_activation = 'relu',
hidden_activation = 'leaky_relu')
model.fit(X, y, epochs = EPOCHS, batch_size = BATCH_SIZE)
類的參數總結如下:
n_mixtures:MDN 使用的分布混合數。如果設置為 -1,它將使用高斯混合模型 (GMM) 和 X 和 y 上的 HDBSCAN 模型“自動”找到最佳混合數。
dist:在混合中使用的分布類型。目前,有兩種選擇;“正常”或“拉普拉斯”。(基于一些實驗,拉普拉斯分布比正態分布更好的結果)。
input_neurons:在MDN的輸入層中使用的神經元數量
hidden_neurons:MDN的 隱藏層架構。每個隱藏層的神經元列表。此參數使您能夠選擇隱藏層的數量和每個隱藏層的神經元數量。
gmm_boost:布爾值。如果設置為 True,將向數據集添加簇特征。
optimizer:要使用的優化算法。
learning_rate:優化算法的學習率
early_stopping:避免訓練時過擬合。當指標在給定數量的時期內沒有變化時,此觸發器將決定何時停止訓練。
tf_mixture_family:布爾值。如果設置為 True,將使用 tf_mixture 系列(推薦):Mixture 對象實現批量混合分布。
input_activation:輸入層的激活函數
hidden_activation:隱藏層的激活函數
現在 MDN 模型已經擬合了數據,從混合密度分布中采樣并繪制概率密度函數:
model.plot_distribution_fit(n_samples_batch = 1)
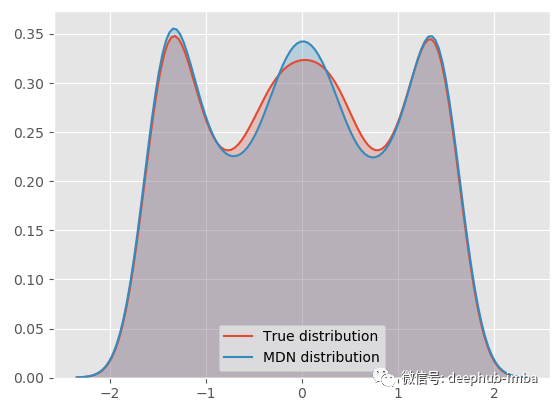
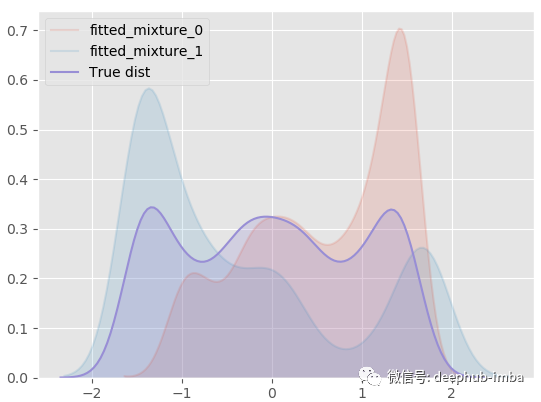
我們的 MDN 模型非常適合真正的一般分布!下面將最終的混合分布分解為每個分布,看看它的樣子:
model.plot_all_distribution_fit(n_samples_batch = 1)
使用學習到的混合分布再次采樣一些 Y 數據,生成的樣本與真實樣本進行對比:
model.plot_samples_vs_true(X, y, alpha = 0.2)
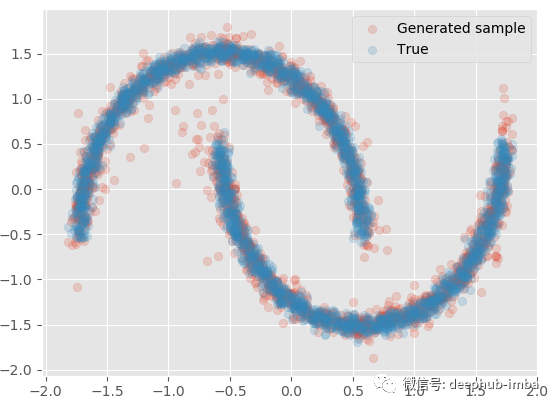
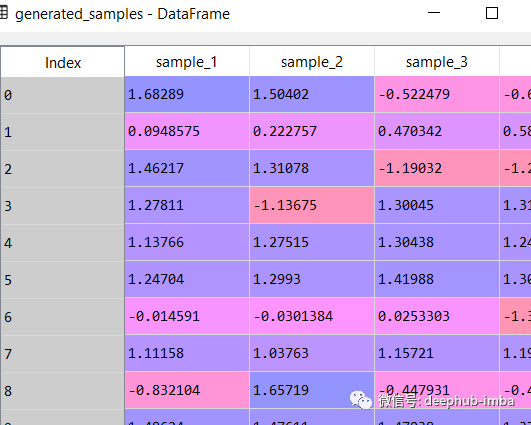
與實際的數據非常接近,如果,給定 X還可以生成多批樣本以生成分位數、均值等統計信息:
generated_samples = model.sample_from_mixture(X, n_samples_batch = 10)
generated_samples
繪制每個學習分布的平均值,以及它們各自的混合權重 (pi):
plt.scatter(X, y, alpha = 0.2)
model.plot_predict_dist(X, with_weights = True, size = 250)
有每個分布的均值和標準差,還可以繪制帶有完整不確定性;假設我們以 95% 的置信區間繪制平均值:
plt.scatter(X, y, alpha = 0.2)
model.plot_predict_dist(X, q = 0.95, with_weights = False)
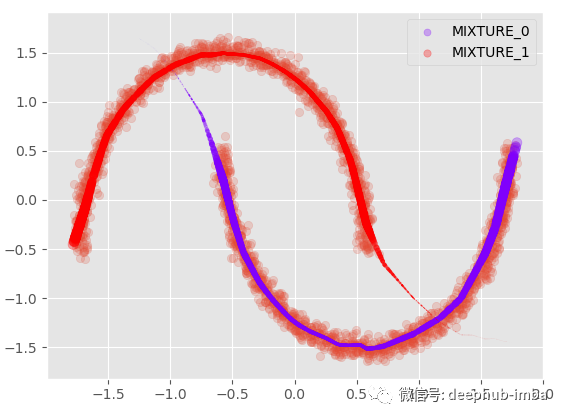
將分布混合在一起,當對同一個 X 有多個 y 分布時,我們使用最高 Pi 參數值選擇最可能的混合:
Y_preds = 對于每個 X,選擇具有最大概率/權重(Pi 參數)的分布的 Y 均值
plt.scatter(X, y, alpha = 0.3)
model.plot_predict_best(X)
這種方式表現得并不理想,因為在數據中顯然有兩個不同的簇重疊,密度幾乎相等。使得誤差將高于標準回歸模型。這也意味著數據集中可能缺少一個可以幫助避免集群在更高維度上重疊重要特征。
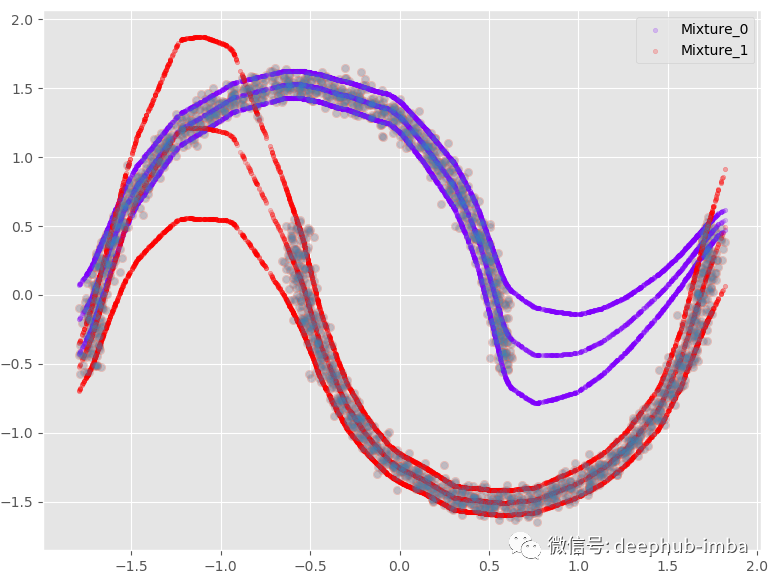
我們還可以選擇使用 Pi 參數和所有分布的均值混合分布:
· Y_preds = (mean_1 * Pi1) + (mean_2 * Pi2)
plt.scatter(X, y, alpha = 0.3)
model.plot_predict_mixed(X)
如果我們添加 95 置信區間: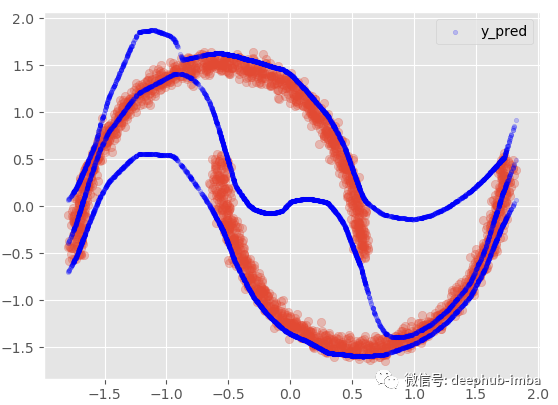
這個選項提供了與非線性回歸模型幾乎相同的結果,混合所有內容以最小化點和函數之間的距離。在這個非常特殊的情況下,我最喜歡的選擇是假設在數據的某些區域,X 有多個 Y,而在其他區域;僅使用其中一種混合。:
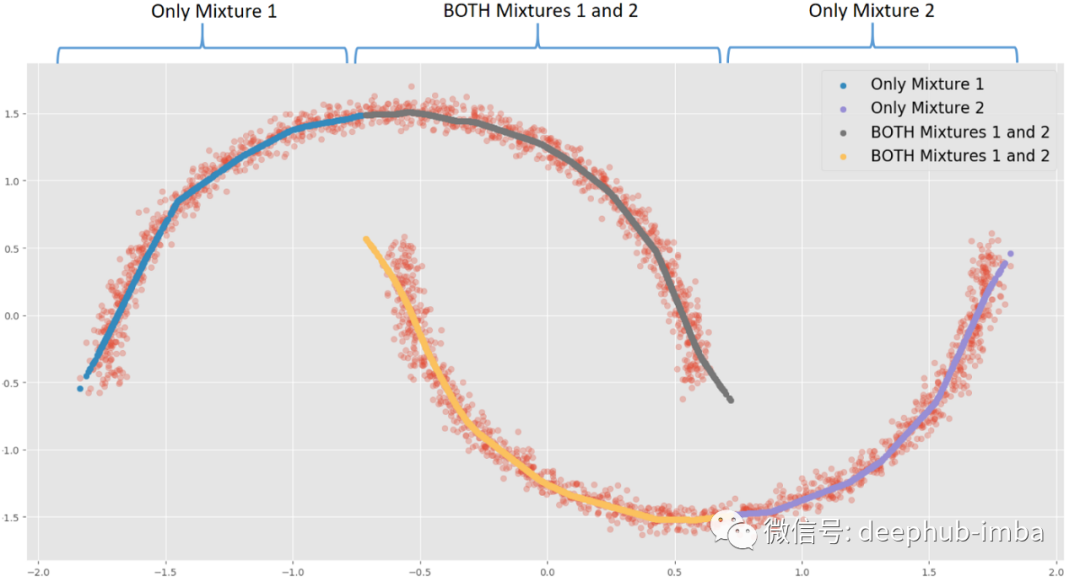
例如,當 X = 0 時,每種混合可能有兩種不同的 Y 解。當 X = -1.5 時,混合 1 中存在唯一的 Y 解決方案。根據用例或業務上下文,當同一個 X 存在多個解決方案時,可以觸發操作或決策。
這個選項得含義是當存在重疊分布時(如果兩個混合概率都 >= 給定概率閾值),行將被復制:
plt.scatter(X, y, alpha = 0.3)
model.plot_predict_with_overlaps(X)
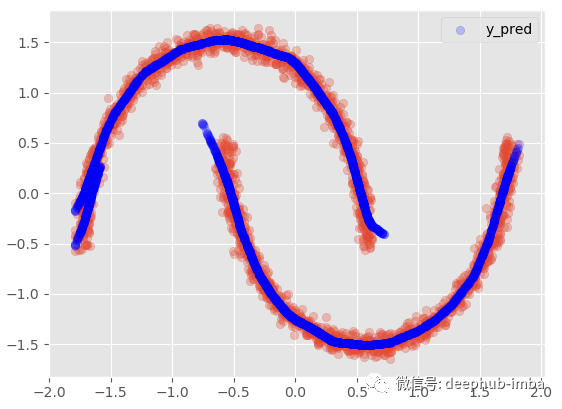
使用 95% 置信區間:
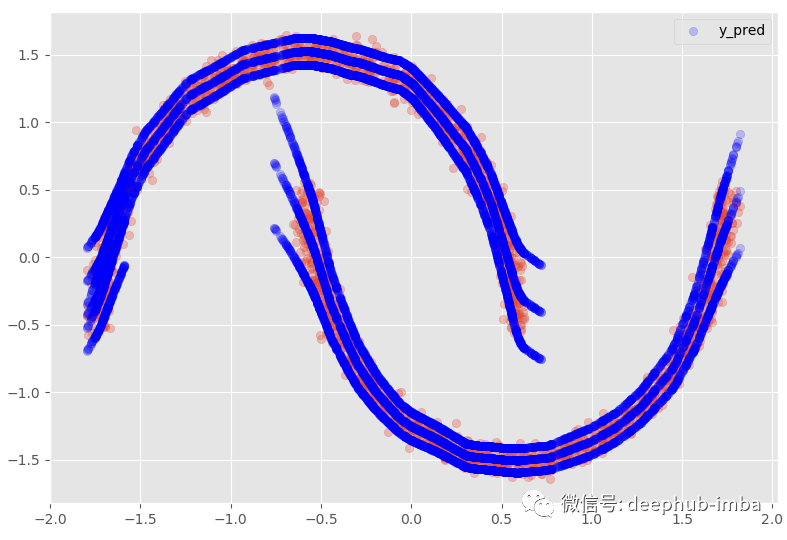
數據集行從 2500 增加到了 4063,最終預測數據集如下所示: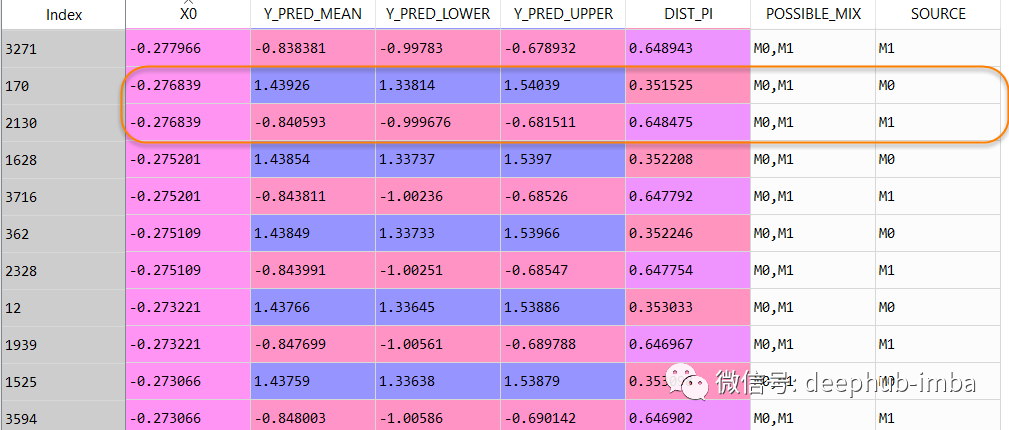
在這個數據表中,當 X = -0.276839 時,Y 可以是 1.43926(混合_0 的概率為 0.351525),但也可以是 -0.840593(混合_1 的概率為 0.648475)。
具有多個分布的實例還提供了重要信息,即數據中正在發生某些事情,并且可能需要更多分析。可能是一些數據質量問題,或者可能表明數據集中缺少一個重要特征!
“交通場景預測是可以使用混合密度網絡的一個很好的例子。在交通場景預測中,我們需要一個可以表現出的行為分布——例如,一個代理可以左轉、右轉或直行。因此,混合密度網絡可用于表示它學習的每個混合中的“行為”,其中行為由概率和軌跡組成((x,y)坐標在未來某個時間范圍內)。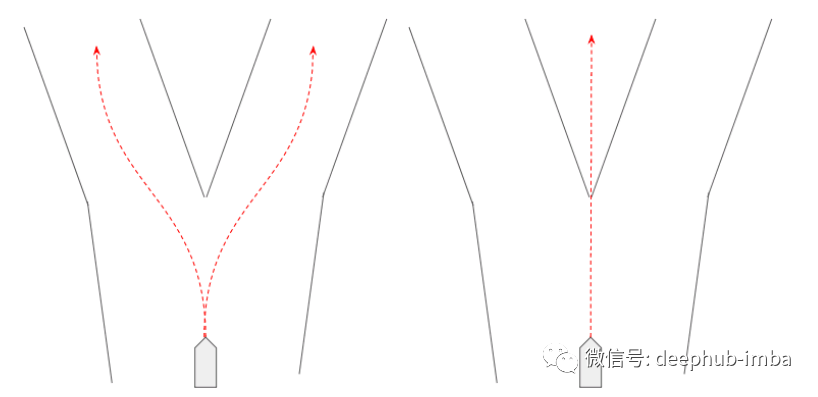
示例2:具有MDN 的多變量回歸
最后MDN 在多元回歸問題上表現良好嗎?
我們將使用以下的數據集: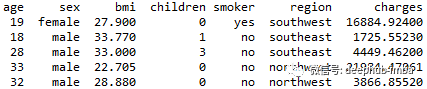
年齡:主要受益人的年齡
性別:保險承包商性別,女,男
bmi:體重指數,提供對身體的了解,相對于身高相對較高或較低的體重,使用身高與體重之比的體重客觀指數(kg / m ^ 2),理想情況下為18.5到24.9
子女:健康保險覆蓋的子女人數/受撫養人人數
吸煙者:吸煙
地區:受益人在美國、東北、東南、西南、西北的居住區。
費用:由健康保險計費的個人醫療費用。這是我們要預測的目標
問題陳述是:能否準確預測保險費用(收費)?
現在,讓我們導入數據集:
"""
#################
# 2-IMPORT DATA #
#################
"""
dataset = pd.read_csv('insurance_clean.csv', sep = ';')
##### BASIC FEATURE ENGINEERING
dataset['age2'] = dataset['age'] * dataset['age']
dataset['BMI30'] = np.where(dataset['bmi'] > 30, 1, 0)
dataset['BMI30_SMOKER'] = np.where((dataset['bmi'] > 30) & (dataset['smoker_yes'] == 1), 1, 0)
"""
######################
# 3-DATA PREPARATION #
######################
"""
###### SPLIT TRAIN TEST
from sklearn.model_selection import train_test_split
X = dataset[dataset.columns.difference(['charges'])]
y = dataset[['charges']]
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.25,
stratify = X['smoker_yes'],
random_state=0)
test_index = y_test.index.values
train_index = y_train.index.values
features = X.columns.tolist()
##### FEATURE SCALING
from sklearn.preprocessing import StandardScaler
x_scaler = StandardScaler()
y_scaler = StandardScaler()
X_train = x_scaler.fit_transform(X_train)
#X_calib = x_scaler.transform(X_calib)
X_test = x_scaler.transform(X_test)
y_train = y_scaler.fit_transform(y_train)
#y_calib = y_scaler.transform(y_calib)
y_test = y_scaler.transform(y_test)
y_test_scaled = y_test.copy()
數據準備完整可以開始訓練了
EPOCHS = 10000
BATCH_SIZE=len(X_train)
model = MDN(n_mixtures = -1, #-1
dist = 'laplace',
input_neurons = 1000, #1000
hidden_neurons = [], #25
gmm_boost = False,
optimizer = 'adam',
learning_rate = 0.0001, #0.00001
early_stopping = 200,
tf_mixture_family = True,
input_activation = 'relu',
hidden_activation = 'leaky_relu')
model.fit(X_train, y_train, epochs = EPOCHS, batch_size = BATCH_SIZE)
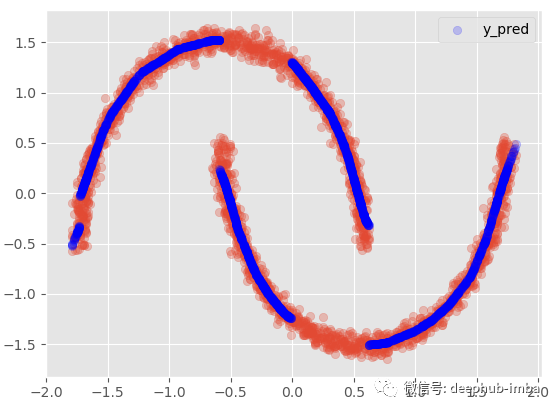
訓練完成后使用“最佳混合概率(Pi 參數)策略”預測測試數據集并繪制結果(y_pred vs y_test):
y_pred = model.predict_best(X_test, q = 0.95, y_scaler = y_scaler)
model.plot_pred_fit(y_pred, y_test, y_scaler = y_scaler)
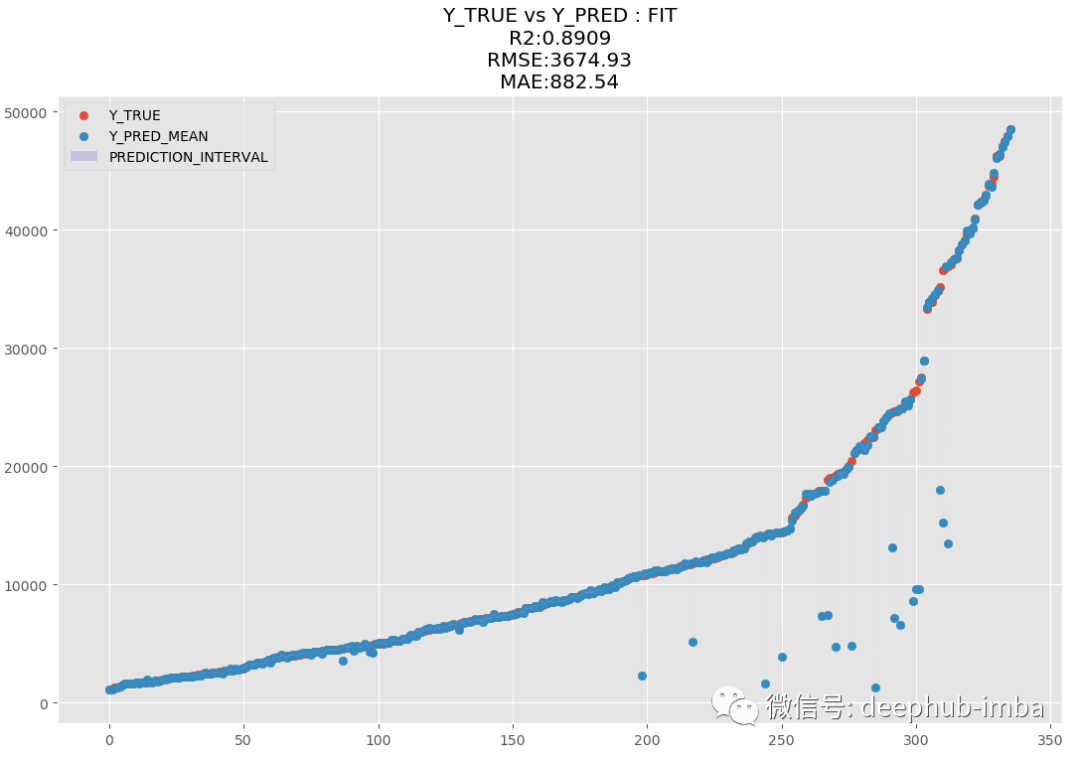
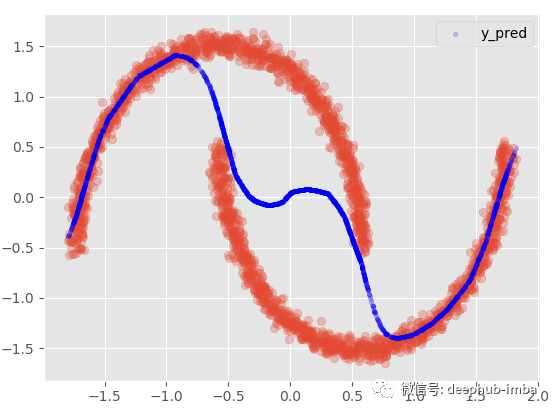
model.plot_pred_vs_true(y_pred, y_test, y_scaler = y_scaler)
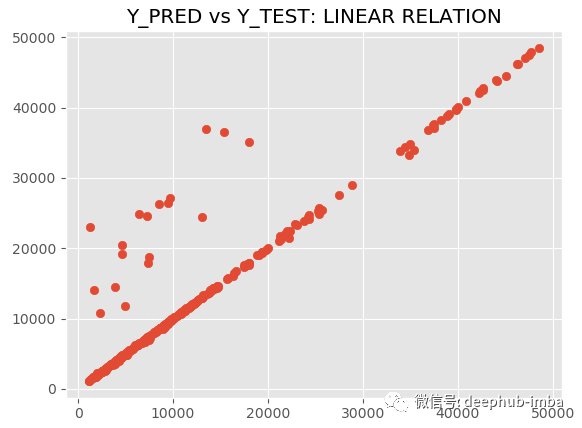
R2 為 89.09,MAE 為 882.54,MDN太棒了,讓我們繪制擬合分布與真實分布的圖來進行對比:
model.plot_distribution_fit(n_samples_batch = 1)
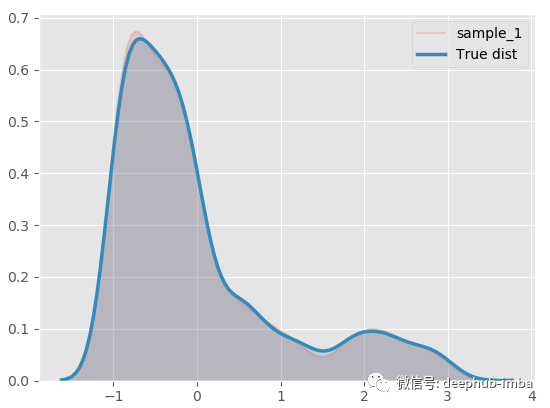
幾乎一模一樣!分解混合模型,看看什么情況: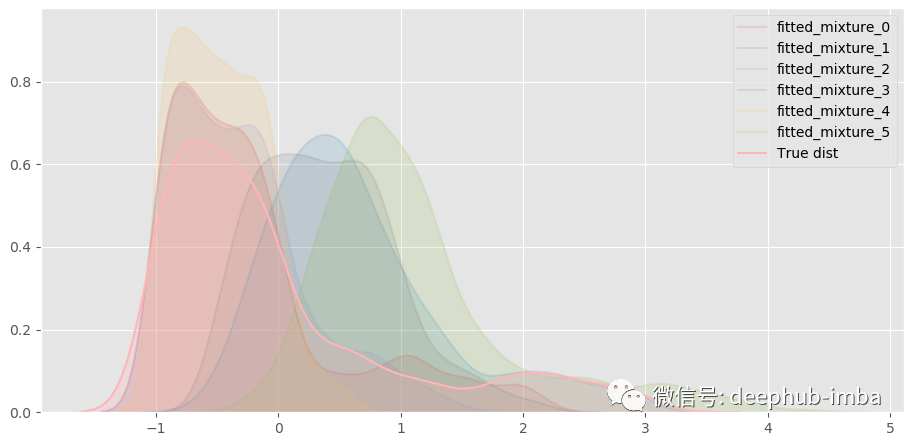
一共混合了六種不同的分布。
從擬合的混合模型生成多變量樣本(應用 PCA 以在 2D 中可視化結果):
model.plot_samples_vs_true(X_test, y_test, alpha = 0.35, y_scaler = y_scaler)
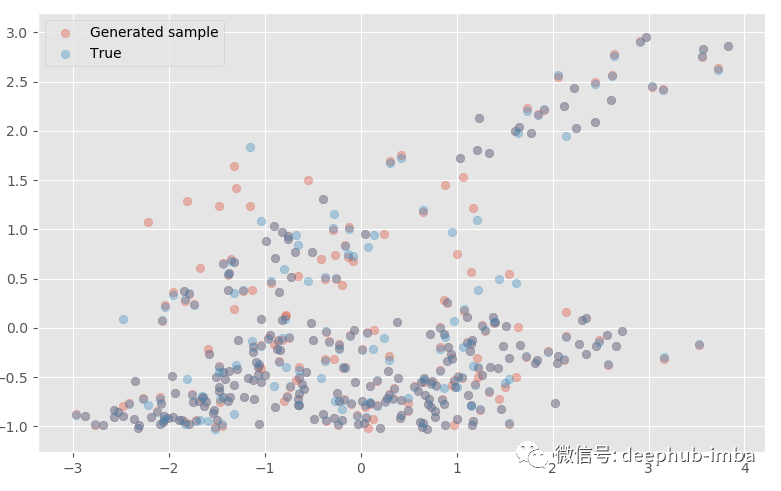
生成的樣本與真實樣本非常接近!如果我們愿意,還可以從每個分布中進行預測:
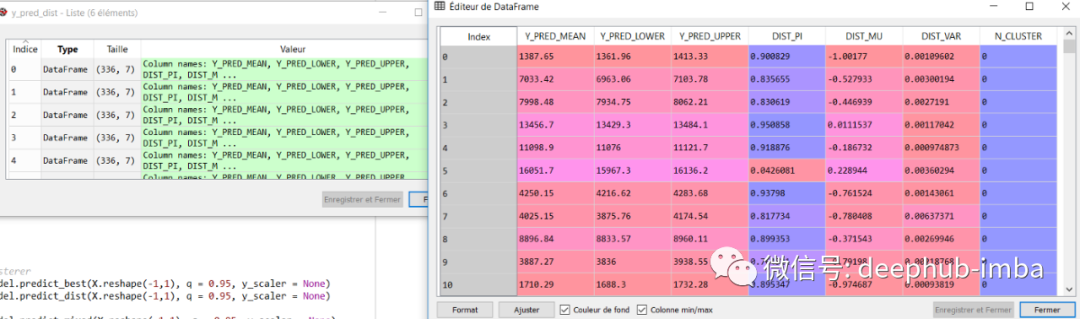
y_pred_dist = model.predict_dist(X_test, q = 0.95, y_scaler = y_scaler)
y_pred_dist
總結
與線性或非線性經典 ML 模型相比,MDN 在單變量回歸數據集中表現出色,其中兩個簇相互重疊,并且 X 可能有多個 Y 輸出。
MDN 在多元回歸問題上也做得很好,可以與 XGBoost 等流行模型競爭
MDN 是 ML 中的一款出色且獨特的工具,可以解決其他模型無法解決的特定問題(能夠從混合分布中獲得的數據中學習)
隨著 MDN 學習分布,還可以通過預測計算不確定性或從學習的分布中生成新樣本
本文的代碼非常的多,這里是完整的notebook,可以直接下載運行:
https://github.com/CoteDave/blog/blob/master/Made%20easy/MDN%20regression/Made%20easy%20-%20MDN%20regression.ipynb
*博客內容為網友個人發布,僅代表博主個人觀點,如有侵權請聯系工作人員刪除。

電子鎮流器相關文章:電子鎮流器工作原理
色差儀相關文章:色差儀原理




