手把手快速實(shí)現(xiàn) Resnet 殘差模型實(shí)戰(zhàn)

作者 | 李秋鍵
出品 | AI科技大本營(ID:rgznai100)
引言:隨著深度學(xué)習(xí)的發(fā)展,網(wǎng)絡(luò)模型的深度也隨之越來越深,但隨著網(wǎng)絡(luò)模型深度的加深,往往會(huì)曾在這隨著模型深度的加大,模型準(zhǔn)確率反而下降的問題,而深度殘差模型的提出就是為了解決這個(gè)問題。
一般來講,網(wǎng)絡(luò)的層數(shù)越深,提取到的特征越豐富,模型對(duì)目標(biāo)函數(shù)的擬合能力越強(qiáng)。但過深的網(wǎng)絡(luò)容易導(dǎo)致過擬合,且由于梯度消失等問題,深層的網(wǎng)絡(luò)難以訓(xùn)練。深度殘差網(wǎng)絡(luò)Resnet由卷積神經(jīng)網(wǎng)絡(luò)發(fā)展變換得來。2015年,由微軟研究院Kaiming He等提出的深度殘差網(wǎng)絡(luò)通過引入恒等路徑使權(quán)重參數(shù)有效傳遞與更新,解決了卷積神經(jīng)網(wǎng)絡(luò)層數(shù)加深導(dǎo)致的過擬合、權(quán)重衰減、梯度消失等問題,性能表現(xiàn)優(yōu)異。
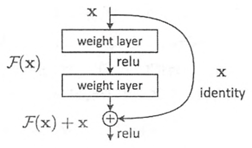
在深層次的網(wǎng)絡(luò)中訓(xùn)練時(shí),由于反向傳播的連乘機(jī)制,常常會(huì)出現(xiàn)在越靠近輸入層的地方出現(xiàn)梯度消失。Resnet將網(wǎng)絡(luò)結(jié)構(gòu)調(diào)整為,將靠近輸入層的網(wǎng)絡(luò)層進(jìn)行短接到輸出層。這樣網(wǎng)絡(luò)就被設(shè)計(jì)成只需要擬合輸入x和目標(biāo)輸出的殘差y-x的模型,這也是模型被稱為Resnet的原因。這樣即使是多加了一層,那模型的效果也不會(huì)變差,因?yàn)樾录拥膶訒?huì)被短接到兩層以后,相當(dāng)于是學(xué)習(xí)了個(gè)恒等映射,而跳過的兩層只需要擬合上層輸出與目標(biāo)之間的殘差即可。
故今天我們將實(shí)現(xiàn)python搭建resnet模型輔助我們理解殘差網(wǎng)絡(luò):
 Resnet基本介紹
Resnet基本介紹
深度殘差網(wǎng)絡(luò)的結(jié)構(gòu)包括輸入層、卷積層、多個(gè)殘差模塊、激活函數(shù)、批標(biāo)準(zhǔn)化層、全局平均池化層、正則化層和多標(biāo)簽分類層。其中卷積層可以有效地提取特征圖的局部特征,減少了可訓(xùn)練的權(quán)重參數(shù)。卷積層將卷積核與上層輸入數(shù)據(jù)卷積運(yùn)算后疊加一個(gè)偏置,得出的結(jié)果經(jīng)過激活函數(shù)計(jì)算得到的輸出特征值作為下層的輸入。批標(biāo)準(zhǔn)化層可以減小樣本數(shù)據(jù)和特征的差異,減輕初始化參數(shù)的依賴,使訓(xùn)練的收斂速度更快。其優(yōu)化了方差的大小和均值的位置,對(duì)可訓(xùn)練參數(shù)進(jìn)行正態(tài)分布處理并進(jìn)行歸一化處理,使得數(shù)據(jù)更均勻的分布在0~1,增強(qiáng)了模型的泛化能力。
殘差模塊的引入有效地解決了深度卷積網(wǎng)絡(luò)的退化問題,提升模型的特征提取能力。殘差模塊包含由多層堆疊卷積組成的殘差路徑和短路路徑。由于在卷積運(yùn)算的過程中不同的卷積步長會(huì)改變輸出特征圖的維度,如果卷積運(yùn)算沒有改變輸入特征圖的維度,可采用恒等映射型殘差模塊。恒等映射型殘差模塊的短路路徑將輸入特征圖恒等輸出,并將其與殘差路徑的輸出特征圖相加,得到殘差模塊的輸出特征圖。如果卷積運(yùn)算改變了輸入特征圖的維度,則無法將短路路徑和殘差路徑的輸出特征圖直接相加,需通過降采樣型殘差模塊,在短路路徑上進(jìn)行1×1卷積運(yùn)算降采樣以保持短路路徑與殘差路徑輸出特征圖維度相同后,兩者方可相加。
(1)Relu緩解的梯度消失和Resnet緩解的梯度消失有何不同?
Relu解決的使用sigmoid等激活函數(shù)時(shí)造成的梯度消失,原因在于sigmoid激活函數(shù)值域范圍為0到1,當(dāng)輸出值特別大或特別小時(shí),根據(jù)圖像特點(diǎn)可知此時(shí)的梯度接近于0,從而造成梯度消失。而relu激活函數(shù)不存在這種情況。
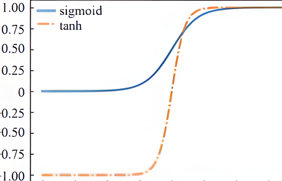
但是即使使用Relu激活函數(shù),當(dāng)網(wǎng)絡(luò)層數(shù)加深時(shí),多個(gè)深度網(wǎng)絡(luò)反向傳播鏈?zhǔn)絺鬟f的多個(gè)參數(shù)連乘仍然會(huì)出現(xiàn)梯度消失。故使用Resnet來改善網(wǎng)絡(luò)深度造成的梯度消失,使用殘差模塊和短接模塊進(jìn)行訓(xùn)練,當(dāng)模型效果已經(jīng)達(dá)到期望值時(shí),使得新加入的層直接學(xué)習(xí)恒等映射,并不會(huì)使得模型效果變差。
(2)Resnet是如何解決梯度消失的?
Resnet將網(wǎng)絡(luò)結(jié)構(gòu)調(diào)整為,將靠近輸入層的網(wǎng)絡(luò)層進(jìn)行短接到輸出層。這樣網(wǎng)絡(luò)就被設(shè)計(jì)成只需要擬合輸入x和目標(biāo)輸出的殘差y-x的模型。這樣即使是多加了一層,那模型的效果也不會(huì)變差,因?yàn)樾录拥膶訒?huì)被短接到兩層以后,相當(dāng)于是學(xué)習(xí)了個(gè)恒等映射,反向傳播時(shí)對(duì)后面的參數(shù)依賴減少,使得跳過的兩層只需要擬合上層輸出與目標(biāo)之間的殘差即可。從而緩解連乘參數(shù)多帶來的梯度消失問題。
 Resnet模型搭建
Resnet模型搭建
為了從代碼層面理解模型,下面用pytorch簡單搭建手寫字體識(shí)別模型。
這里程序的設(shè)計(jì)分為以下幾個(gè)步驟,分別為預(yù)準(zhǔn)備、模型搭建以及訓(xùn)練等幾個(gè)步驟。
2.1 模型預(yù)準(zhǔn)備
這里包括的預(yù)準(zhǔn)備首先包括GPU或CPU訓(xùn)練的選擇,迭代次數(shù)、batch一次訓(xùn)練樣本數(shù),學(xué)習(xí)率。然后通過pytorch中的transforms對(duì)數(shù)據(jù)變換,包括數(shù)據(jù)增強(qiáng)和轉(zhuǎn)為Tensor等格式以及讀入訓(xùn)練和測試數(shù)據(jù)等,代碼如下:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')num_epochs = 100batch_size = 32learning_rate = 0.001transform = transforms.Compose([ transforms.Pad(4), transforms.RandomHorizontalFlip(), transforms.RandomCrop(32), transforms.ToTensor()])train_datatset = torchvision.datasets.MNIST(root='./data/', train=True, transform=transform, download=True, )test_datatset = torchvision.datasets.MNIST(root='./data/', train=False, transform=transforms.ToTensor() )train_loader = torch.utils.data.DataLoader( dataset=train_datatset, batch_size=batch_size, shuffle=True)test_loader = torch.utils.data.DataLoader( dataset=test_datatset, batch_size=batch_size, shuffle=True)2.2 殘差模塊
構(gòu)建殘差神經(jīng)網(wǎng)絡(luò)模型,與一般神經(jīng)網(wǎng)絡(luò)搭建類似,但需要判斷輸出是否為短接加和。代碼如下:
class ResidualBlock(nn.Module): def __init__(self, in_channels, out_channels, stride=1, downsample=None): super(ResidualBlock, self).__init__() self.conv1 = conv3x3(in_channels, out_channels, stride) self.bn1 = nn.BatchNorm2d(out_channels) self.relu = nn.ReLU(inplace=True) self.conv2 = conv3x3(out_channels, out_channels) self.bn2 = nn.BatchNorm2d(out_channels) self.downsample = downsample
def forward(self, x): residual = x out = self.conv1(x) out = self.bn1(out) out = self.relu(out) out = self.conv2(out) out = self.bn2(out) if self.downsample: residual = self.downsample(x) out += residual out = self.relu(out) return out
2.3 Resnet模型搭建
構(gòu)建Resnet整體網(wǎng)絡(luò)模型。代碼如下:
class ResNet(nn.Module): def __init__(self, block, layers, num_classes=10): super(ResNet, self).__init__() self.in_channels = 16 self.conv = conv3x3(1, 16) self.bn = nn.BatchNorm2d(16) self.relu = nn.ReLU(inplace=True) self.layer1 = self.make_layer(block, 16, layers[0]) self.layer2 = self.make_layer(block, 32, layers[1], 2) self.layer3 = self.make_layer(block, 64, layers[2], 2) self.avg_pool = nn.AvgPool2d(8) self.fc = nn.Linear(64, num_classes) def make_layer(self, block, out_channels, blocks, stride=1): downsample = None if (stride != 1) or (self.in_channels != out_channels): downsample = nn.Sequential( conv3x3(self.in_channels, out_channels, stride=stride), nn.BatchNorm2d(out_channels) ) layers = [] layers.append(block(self.in_channels, out_channels, stride, downsample)) self.in_channels = out_channels for i in range(1, blocks): layers.append(block(self.in_channels, out_channels)) return nn.Sequential(*layers) def forward(self, x): out = self.conv(x) out = self.bn(out) out = self.relu(out) out = self.layer1(out) out = self.layer2(out) out = self.layer3(out) out = self.avg_pool(out) out = out.view(out.size(0), -1) out = self.fc(out) return outmodel = ResNet(ResidualBlock, [2, 2, 2]).to(device)
2.4 模型訓(xùn)練
同一般網(wǎng)絡(luò)模型訓(xùn)練相同,包括數(shù)據(jù)轉(zhuǎn)為GPU讀入格式,模型計(jì)算輸出,設(shè)置損失函數(shù)計(jì)算損失,梯度置零初始化,誤差反向傳播和參數(shù)更新等,代碼如下:
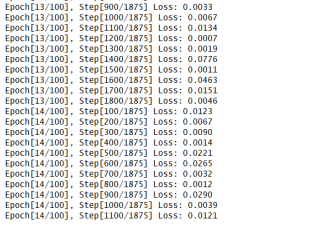
for epoch in range(num_epochs): for i, (images, labels) in enumerate(train_loader): images = images.to(device) labels = labels.to(device) outputs = model(images) loss = criterion(outputs, labels) optimizer.zero_grad() loss.backward() optimizer.step() if (i + 1) % 100 == 0: print("Epoch[{}/{}], Step[{}/{}] Loss: {:.4f}" .format(epoch + 1, num_epochs, i + 1, total_step, loss.item())) losss.append(loss.item())完整代碼:
鏈接:https://pan.baidu.com/s/1PwDHFI70k7pzpMdATulG_g提取碼:k2kq
李秋鍵,CSDN博客專家,CSDN達(dá)人課作者。碩士在讀于中國礦業(yè)大學(xué),開發(fā)有taptap競賽獲獎(jiǎng)等。
*博客內(nèi)容為網(wǎng)友個(gè)人發(fā)布,僅代表博主個(gè)人觀點(diǎn),如有侵權(quán)請(qǐng)聯(lián)系工作人員刪除。






