麻省理工最新研究 | 自動為目標任務和硬件定制高效CNN結構


導 讀
NAS受限于其過高的計算資源需求,仍無法在大規模任務上直接進行神經網絡的學習。
今天分享的這篇文章主要解決NAS代理機制下無法搜索到全局最優的問題,改進搜索策略,一定程度上解決資源消耗的問題。其主要是基于DARTs改的,那就先談談DARTs的一些問題:
· 只搜索cell,然后不斷的堆疊起來,實際上只要網絡堆疊的夠深,性能并不會太差;
· 一些operation的結構參數非常接近,比如兩個op的結構參數分別是20.2%,20.1%,似乎選擇20.2%和20.1% 并沒有太大的差別;
· 一開始是在整個Net上進行訓練,但是選取的時候只是選擇一個子網絡,中間可能會出現一些問題。
作者提出了ProxylessNAS,第一個在沒有任何Proxy的情況下直接在ImageNet量級的大規模數據集上搜索大設計空間的的NAS算法,并首次專門為硬件定制CNN架構,作者還將模型壓縮(減枝、量化)的思想與NAS進行結合,把NAS的計算成本(GPU時間和內存)降低到與常規訓練相同的規模,同時保留了豐富的搜索空間,并將神經網絡的硬件性能(延時,能耗)也直接納入到優化目標中。
引言
目前一個普遍的做法是在一個小型的Proxy任務上進行網絡學習,然后再遷移到目標任務上。這樣的Proxy包括:1) 訓練極少量輪數;2)在較小的網絡下學習一個結構單元,然后通過重復堆疊同樣的block構建一個大的網絡;3) 在小數據集(如:CIFAR)上進行搜索。然而,這些在 Proxy 上優化的網絡結構在目標任務上并不是最優的。
作者最后提出的ProxylessNAS在CIFAR-10和ImageNet的實驗驗證了「直接搜索」和「為硬件定制」的有效性。在CIFAR-10上,作者新提出的模型僅用5.7M參數就達到了2.08%的測試誤差。對比之前的最優模型AmoebaNet-B,ProxylessNAS僅用了六分之一的參數量就達到了更好的結果。在ImageNet上,ProxylessNAS比MobilenetV2高了3.1%的Top-1正確率,并且在GPU上比MobilenetV2快了20%。在同等的top-1準確率下(74.5%以上),ProxylessNAS的手機實測速度是當今業界標準MobileNetV2的1.8倍。在用ProxylessNAS來為不同硬件定制神經網絡的同時,作者發現各個平臺上搜索到的神經網絡在結構上有很大不同。這些發現為之后設計高效CNN結構提供新的思路。
相關背景
近期研究中,神經結構搜索(NAS)已經在各種深度學習任務(如圖像識別)的神經網絡結構設計自動化方面取得了很大成功。然而,傳統NAS算法的計算量巨大,如NASNet需要10^4 GPU hours來運行。以DARTs為代表的Differentiable NAS雖減少了計算需求,可隨著搜索空間線性增長的內存成了新的瓶頸。由于這些局限,之前的NAS都利用了Proxy任務,例如僅訓練少量Epoch,只學習幾個Block,在較小的數據集上搜索(如CIFAR)再遷移。這些Proxy任務上優化的結構,并不一定在目標任務上是最佳的。同時為了實現可轉移性,這些方法往往僅搜索少數結構Block,然后重復堆疊。這限制了塊的多樣性,并導致性能上的損失。依賴Proxy同時也意味著無法在搜索過程中直接權衡延遲等硬件指標。
因此,作者提出了一個簡單而有效的方案來解決上述限制,稱為ProxylessNAS,其直接在目標任務和硬件上學習結構而不依賴于Proxy。作者還移除了先前NAS工作中的重復塊的限制:所有stage都可以自由的選擇最適合的模塊,并允許學習和指定所有塊。為此,將體系結構搜索的計算成本(GPU時間和內存)降低到相同水平的常規訓練,為了直接在目標硬件上學習專用網絡結構,在搜索時我們也考慮了硬件指標。

在CIFAR-10和ImageNet上的實驗中,從直接性和專業性的角度出發,提出的新方法可以獲得較強的實證結果。在CIFAR-10上,新模型僅需5.7M參數即可達到2.08%的測試誤差。在ImageNet上,新模型比MobileNetV 2提高了3.1%,獲得了75.1%的top-1精度,同時速度為1.2倍。主要的貢獻可歸納如下:
· ProxylessNAS是第一個在沒有任何代理的情況下直接學習大規模數據集上的CNN結構的NAS算法,同時仍然允許大的候選集并消除重復塊的限制。它有效地擴大了搜索空間,實現了更好的性能;
· 為NAS提供了一種新的路徑級剪裁視角,顯示了NAS與模型壓縮之間的緊密聯系。通過使用path-level binarization將內存消耗節省一個數量級;
· 提出了一種新的基于梯度的方法(作為一個正則函數),來處理硬件目標(如:延遲)。針對不同的硬件平臺:CPU/GPU/FPGA/TPU/NPU,ProxylessNAS實現了針對目標硬件CNN結構定制。據所知,這是第一個來研究不同硬件結構下的專用神經網絡結構的文章;
· 廣泛的實驗證明了Directness和Specialization的優勢。它在不同硬件平臺延遲限制下,在CIFAR-10和ImageNet上實現了最好的性能。作者還分析了專用于不同硬件平臺的高效CNN模型的偏好,指出不同硬件平臺需要不同的神經網絡結構。
技術方法
Over-parameterized網絡的構建
首先描述了具有所有候選路徑的over-parameterized網絡的構造,然后介紹了如何利用二值化的體系結構參數將訓練over-parameterized網絡的內存消耗降低到與常規訓練相同的水平。提出了一種基于梯度的二值化結構參數訓練算法。最后,提出了兩種處理不可微目標(如延遲)的技術,用于在目標硬件上專門化神經網絡。

學習BINARIZED PATH
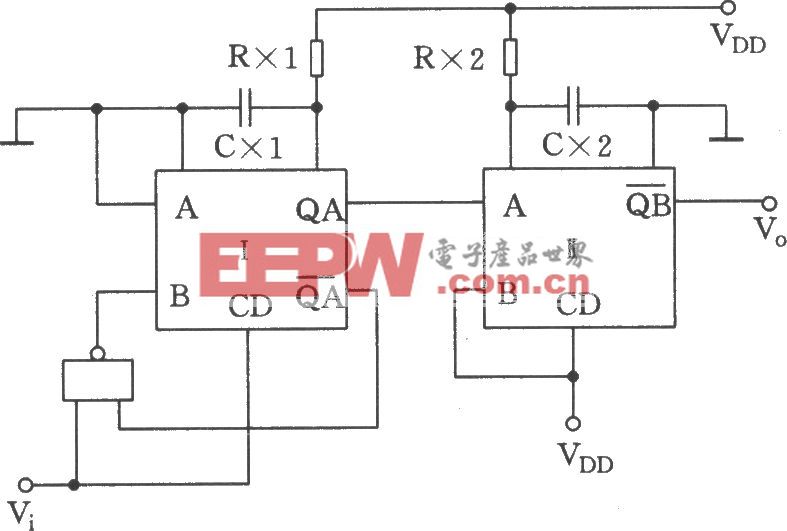
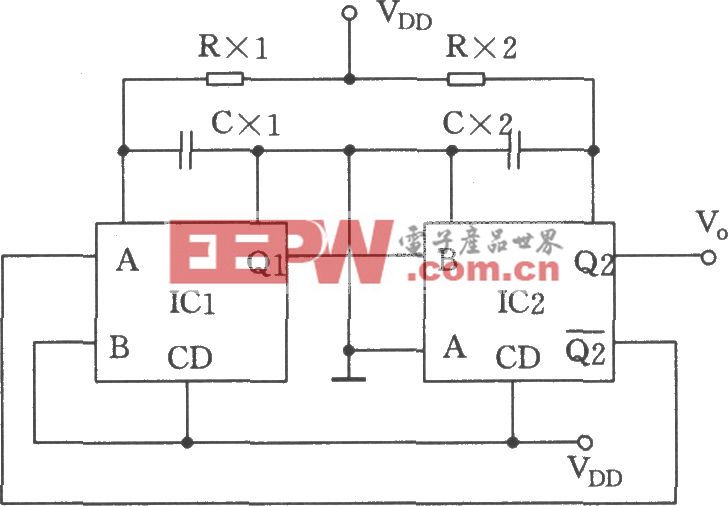
為了減少內存占用,在訓練over-parameterized網絡時,只保留一條路徑。與Courbariaux等人不同。對單個權重進行二值化后,對整個路徑進行二值化。引入n個實值結構參數{αI},然后將實值路徑權重轉換為二進制門:

然而直接去訓練這樣一個over-parameterized網絡是有問題的,因為其GPU顯存會隨著候選操作的數量線性增長。這里,作者就利用到路徑級二值化的思想來解決這個問題:即將路徑上的架構參數二值化,并使得在訓練過程中只有一個路徑處于激活狀態。這樣一來GPU顯存的需求就降到和正常訓練一個水平。在訓練這些二值化的架構參數的時候,作者采用類似BinaryConnect的思想,使用對應的Binary Gate的梯度來更新架構參數:

為了解決這個問題,考慮將從n個候選對象中選擇一條路徑的任務分解為多個二進制選擇任務。直覺是,如果一條道路是在某一特定位置上的最佳選擇,那么與任何其他路徑相比,它應該是更好的選擇。
HANDLING NON-DIFFERENTIABLE HARDWARE METRICS
除了準確率之外,在設計高效神經網絡結構的時侯,延遲是另一個非常重要的目標。與可以使用損失函數的梯度優化的準確率不同,延遲這一指標是不可微的。在本節中,我們提出了兩種算法來處理這種不可微分的目標。

通過將縮放因子λ2(>0)乘以控制精度和延遲之間的權衡,將網絡的預期延遲合并到正常的損失函數中。最后的損失函數如上圖所示(右)。
對于二進制參數,我們有以下更新:

實驗結果

在CIFAR-10和ImageNet上進行了實驗。不同于之前的NAS工作,作者直接在目標數據集上進行神經網絡結構學習,為目標硬件進行優化,同時允許每一個block自由地選擇操作。
在ImageNet上的結果

在移動端,與MobilenetV2相比,提出的ProxylessNAS在維持同等的延遲的前提下,TOP-1準確率提升了2.6%。此外,在各個不同的延遲設定下,新模型大幅優于MobilenetV2:為了達到74.6%的精度,MobilenetV2需要143ms的推理時間,而新模型僅需要78ms(1.83x)。
與MnasNet相比,新模型在提升0.6%Top-1的同時保持略低的推理時間。值得一提的是,新模型所消耗的搜索資源要比Mnas少得多(1/200)。

下圖展示了在三個硬件平臺上搜索到的CNN模型的詳細結構:GPU/CPU/Mobile。
我們注意到,當針對不同平臺時,網絡結構呈現出不同的偏好:
1)GPU模型短而寬,尤其是在feature map較大時;
2)GPU模型更喜歡大MBConv操作(如:7x7 MBConv6),而CPU模型則傾向于小操作。這是因為GPU比CPU有更高的并行度,因此它可以更好地利用大MBConv。
另一個有趣的觀察是,當特征圖被下采樣時,所有的網絡結構都傾向于選擇一個更大的MBConv。這可能是因為MBConv操作有利于網絡在下采樣時保留更多信息。值得注意的是,這是之前強制block之間共享結構的NAS方法無法發現的。

END
論文: https://arxiv.org/pdf/1812.00332.pdf
代碼:https://github.com/MIT-HAN-LAB/ProxylessNAS
*博客內容為網友個人發布,僅代表博主個人觀點,如有侵權請聯系工作人員刪除。